






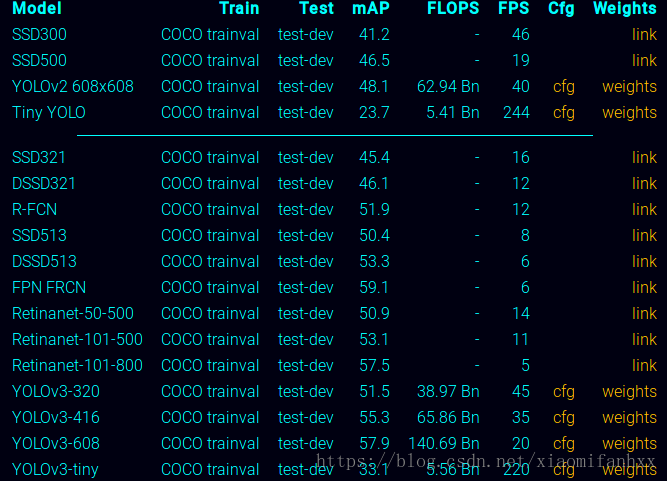
个人理解:yolov2相对于yolov1更改很多,但可以通过查看yolov1论文进行对yolo框架的了解,再过渡到yolov2
YOLO出自2016CVPR You Only Look Once:Unified,Real-Time Object Detection 是个值得学习的深度学习框架。
1 Abstract
作者提出了新的一种物体检测的方法YOLO,YOLO之前是通过region proposal产生大量的potential bounding boxes,随后分类器分别对每个Bounding box进行解析:判断该Boundingbox是否含有物体,物体所含类别,以及confidence。大部分深度学习网络如:R-CNN,FAST-R-CNN,Faster-R-CNN等都是通过这种方式来进行物体检测。
YOLO与上述方法不同,其将物体检测任务当做了一个regression问题来处理,通过将一张图片送入神经网络中,来预测出bounding box的坐标,类别以及置信度。由于YOLO目标检测是在一个神经网络中完成的,所以是end to end来进行目标检测。
YOLO的优点是在于其实时性比较好,其检测速度可以高达45FPS,使用Tiny-YOLO速度会更加快,但是Tiny-YOLO的准确率并不是很高。速度效率如图所示。
虽然,YOLO的实时性比较好,但是也是损失了少许精度,其准确率并不如Fast-R-CNN以及Faster-R-CNN。
2 Introduction
简介:
YOLO之前的物体检测系统是使用分类器来完成物体检测任务的,为了检测一个物体,这些物体检测系统要在一张图的不同位置,不同尺寸的Bounding box上使用物体分类器来检测是否有物体。如最早的DPM系统,就是使用滑框算法来在图像上进行滑框,再对滑框所处的位置通过分类器来进行分类。受到DPM算法的启发,如Fast-R-CNN、Faster-R-CNN均是通过先找到region proposal区域,然后再在使用potential bounding box来检测,最后对众多的boxes进行打分,接着通过post-processing来改善bounding boxes的选择,消除重复检测目标,再次对Boundingboxes进行从新打分,整个流程较为复杂,且进行分类与预测Bounding boxes是分开的,很难进行优化来提高速度。
三步走:
而本文作者将物体检测当成了回归问题,直接通过整张图片来得到Bounding boxes的坐标、置信度以及类别,YOLO是端到端的进行物体检测,只需要将一张图片输入到神经网络模型中就能检测到图片中物体的位置以及类别。通过使用YOLO来进行物体检测是通过三步来进行的:
(1)将输入图像resize到448*448作为神经网络的输入(使用高分辨率的图片使得feature map的分辨率也得以提高)
(2)运行神经网络,得到一些Bounding boxes的坐标、confidence以及probablely class
(3)运行非极大值抑制算法(NMS)对Bounding boxes进行筛选
YOLO优点:
(1)YOLO检测速度特别快,只需要将输入图片送入至神经网络中,就能够检测到图片中物体的位置信息,confidence,probablely classier,是end to end的网络,常用于实时检测,并能取得较好的结果。(由于其得到检测结果只是通过一次卷积神经网络,而例如R-CNN系列,虽然也是整张图输入,但是采用的proposal-classifier的思想,而yolo是直接采用回归的思想)
(2)YOLO可以很好的避免背景错误,产生false positives:其不像DPM使用滑窗也不像R-CNN使用region proposal,分类器只能得到图像的局部信息。YOLO在训练与测试中能够看到在一整张图的整体信息,YOLO在进行检测的时候能够利用好上下文的关系,从而不容易在背景中预测出错误的物体信息。和Fast-R-CNN相比,YOLO错误率不及其一半。(由于yolo检测的时候能够更好的使用图像的上下文关系,是对整张图片进行检测,而R-CNN系列使用的还是region-proposal,分类器只能得到图像的局部信息。)
(3)YOLO可以很好的学到泛化特征:在自然图像上,YOLO的性能会比其他网络模型更好。
YOLO缺点:
(1)由于检测速度的提升牺牲了部分部分精度,YOLO物体检测性比其他sate-of-the-art(最先进的)物体检测检测系统要低。
(2)YOLO较容易产生物体定位错误。(由于yolov1是采用了直接回归出绝对坐标,而直接回归出绝对坐标的难度较大,因此,yolov2以及yolov3针对物体定位提出了新的方法,回归相对坐标,难度较小且能够准确率较高。而且对于对不同大小的box预测的时候,相比于大物体预测的偏一些,小物体预测偏一些则不能忍受,会产生较大的误差,因此作者在构造损失函数的时候使用了将w,h使用了根的均方和误差,虽然做了该处理不过定位误差还是较大。)
(3)YOLO对检测小物体不好(一个grid cell只能预测两个Bounding boxes)(由于每个grid cell虽然可以预测B个bounding box,但是会选择最优的一个作为目标检测输出,即每个网格至多只能预测出一个物体,如果图像中包含大量密集的物体,则会检测错误,出现大量漏检现象。)
对于物体检测性能(使用的指标是mAP)的体现如图所示:
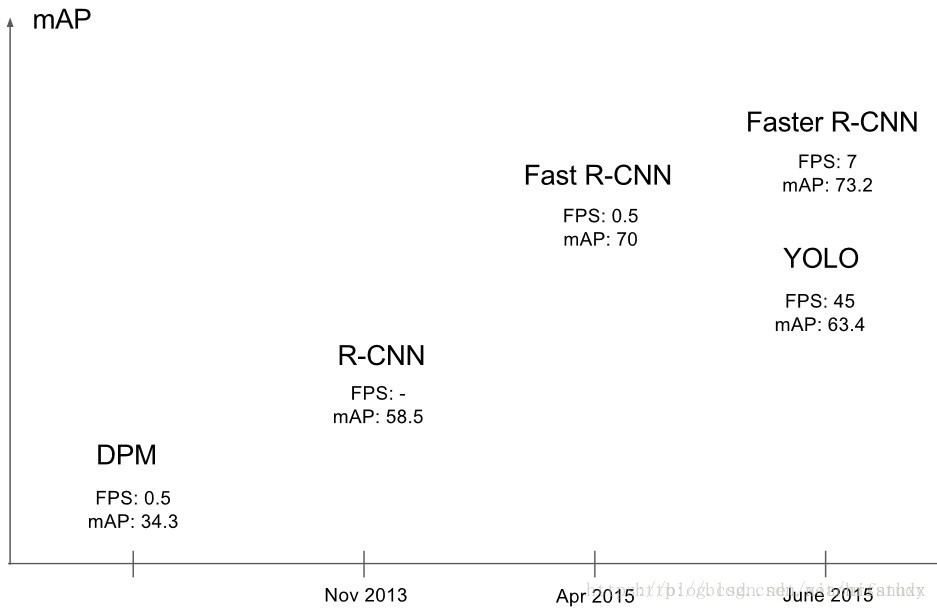
mAP(mean average precision)经常用于衡量物体检测系统识别精度的指标,多个类别检测中,每一类都可以根据recall和precision来判断。
3 下面进入重要章节(YOLO到底是如何进行物体检测的):Unified Detection
(1)整体流程:将输入图像分为S*S个栅格(grid cell),每个栅格来检测中心落在该栅格的物体,具体情况如图所示。每个栅格预测两个Bounding boxes(每个box含有5个变量:x,y,w,h,confidence)(此方法只是理解,后来证明降低了准确率)。且预测该栅格是哪个种类的物体,下面具体讲解Bounding boxes的参数,confidence的求解以及conditional class probability(条件类别概率)。

(2)对于Bounding box的理解:Bounding box含有4个变量,分别是x:代表在该栅格的物体中心相对于该栅格的横坐标;y:代表在该栅格的物体中心相对于该栅格的横坐标;w:代表在该Bounding box的宽度相对于整个图片的宽度;h:代表在该Bounding box的高度相对于整个图片的高度。
(3)关于confidence的理解:首先confidence的计算公式如下图所示。
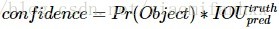
(4)conditional class probability:前面讲述一个grid cell预测2个Bounding boxes,而且其也预测该grid cell是属于哪个class。下图表示一个grid cell代表的含义。
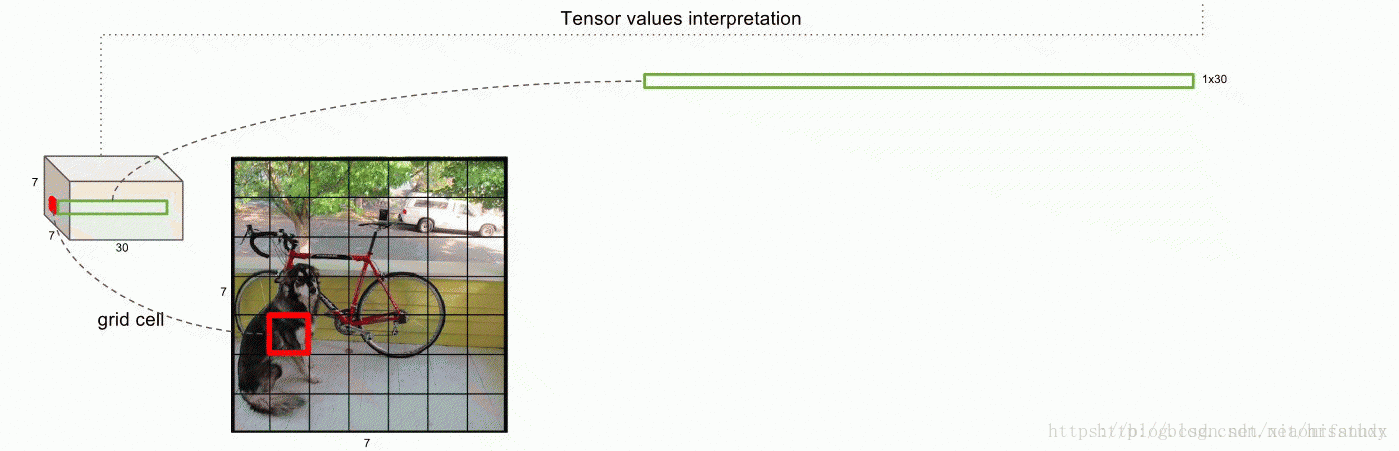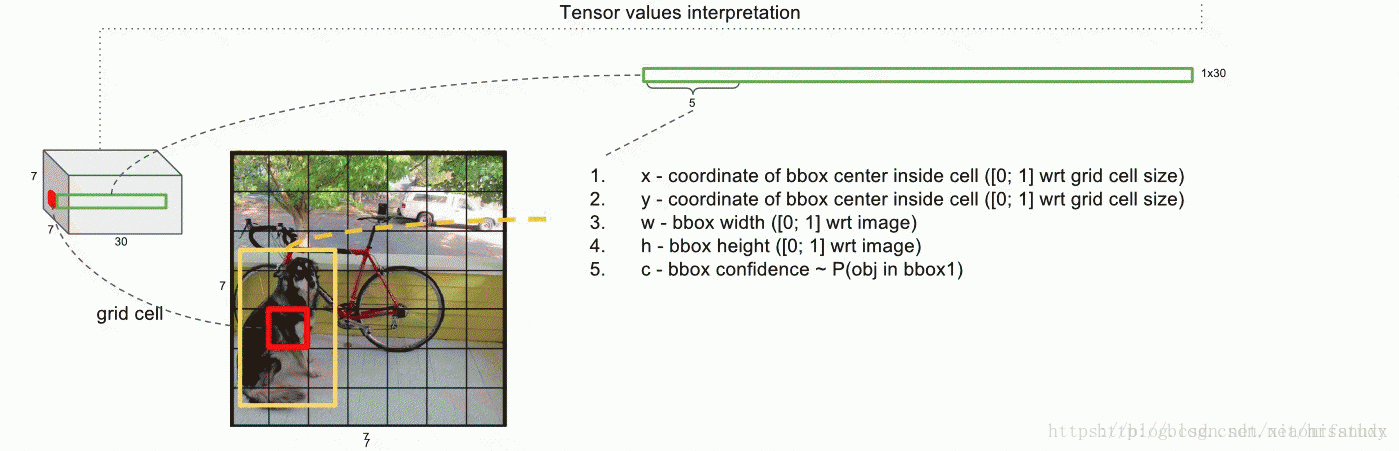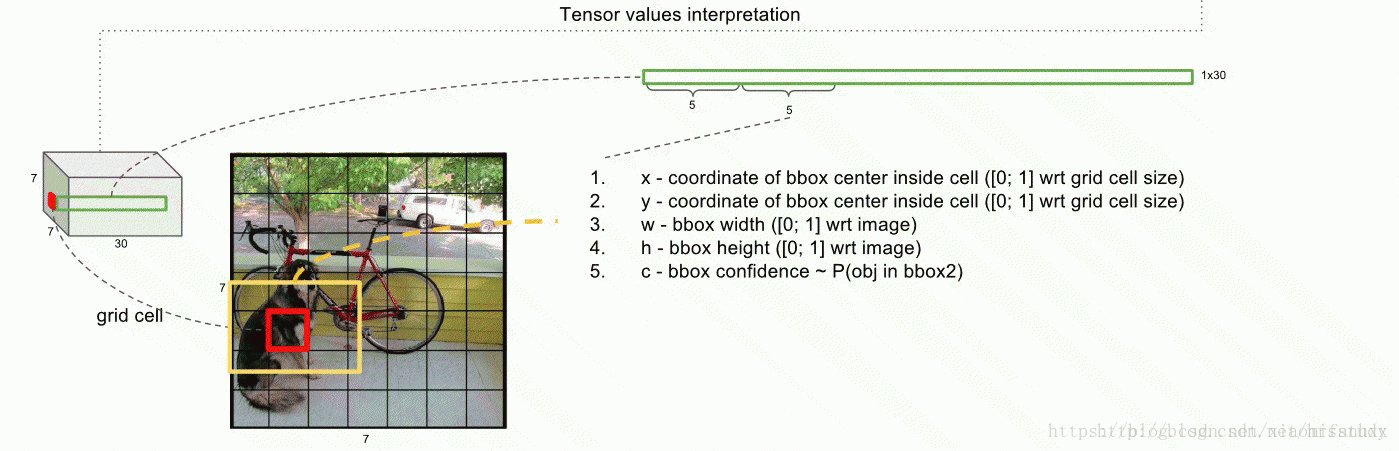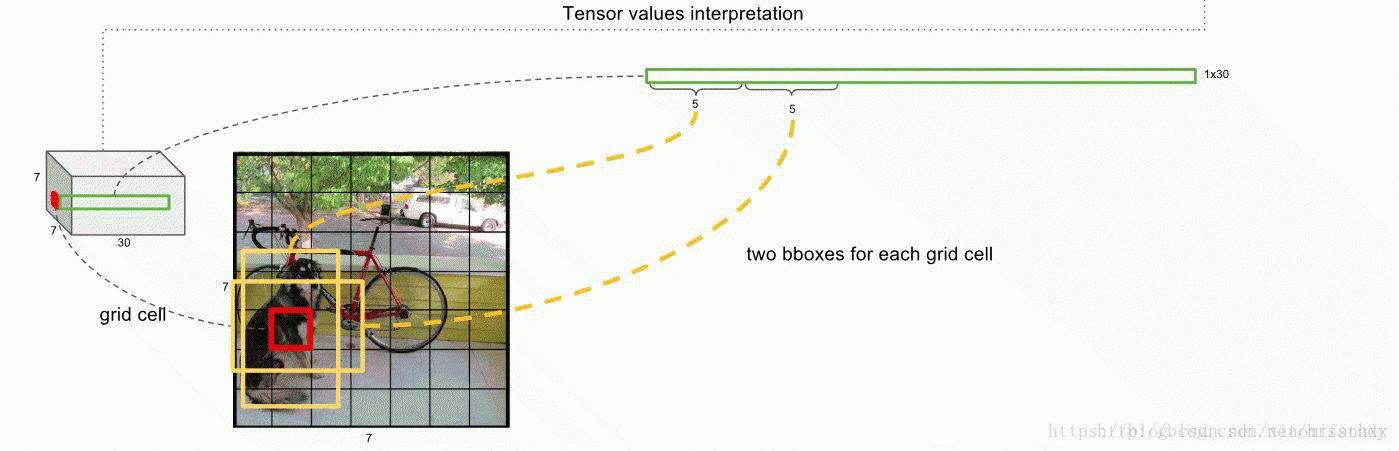
即一个grid cell的深度值为30:包含两个Bounding boxes的值也包括类别(在此作者的类别为20),因此一个grid celld的深度是(2*5+classes)。由于是一个grid cell预测一个类别,所以类别与Bounding boxes并没有什么联系。conditional class probability的计算方法为Pr(Class|Object),即在某个grid cell包含物体的情况下,确定该物体的类别。
(5)测试:在测试的时候将每个grid cell的conditional class probability与其预测的Bounding boxes的置信度进行乘积,求得最后的结果既可以表示每个Bounding box代表的类别也可以表示其是否有物体以及其坐标的准确度。
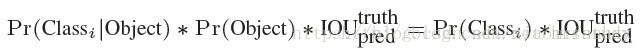
(6)YOLO训练:在对PASCAL VOC数据集进行训练的时候,论文中使用的S=7,类别为20类,因此最后输出张量的个数为7*7*(2*5+Classes(20))
4 Network Design
YOLO物体检测系统包括24个卷积层,2个池化层。卷积层的作用是为了提取图像的特征,全连接层是为了预测图像的位置以及物体类别的概率值。网络模型如图所示。
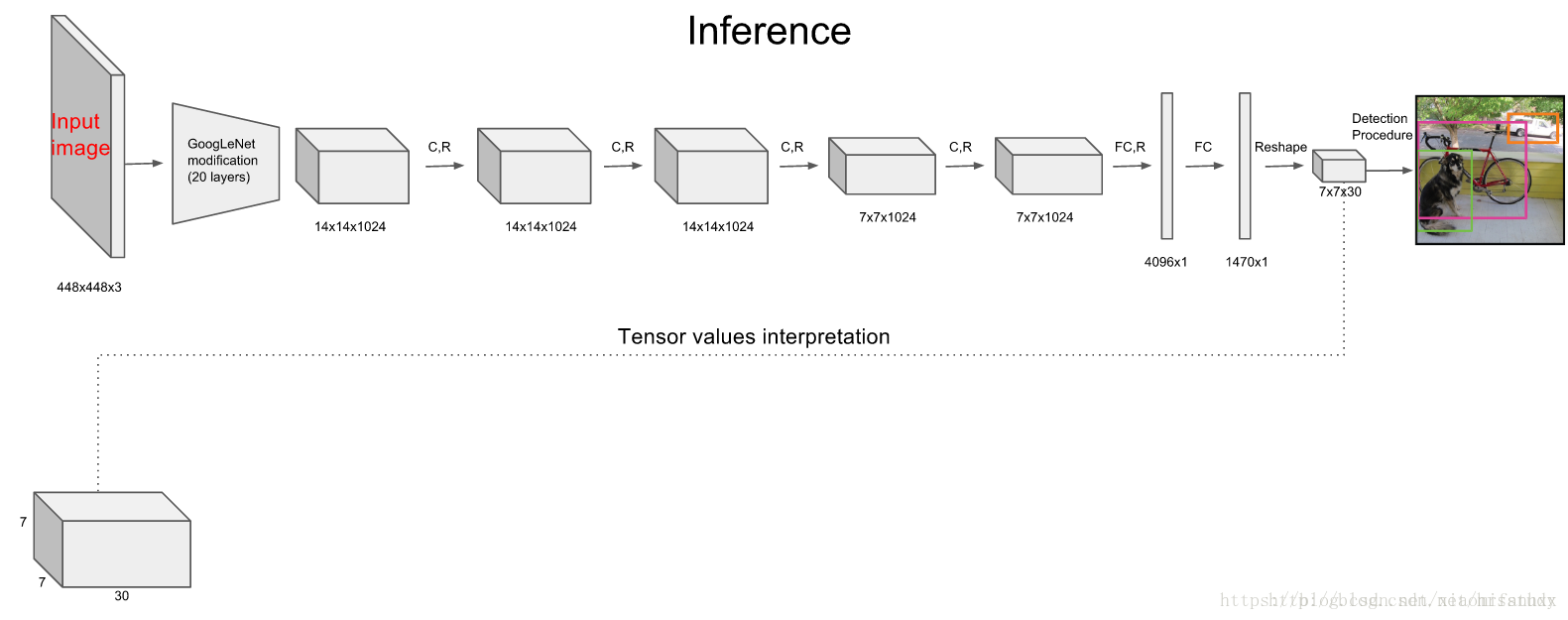

5 Training
在训练数据中,大家可以参考YOLO的官网来进行操作,参考网站:https://pjreddie.com/darknet/yolo/ (注意:由于官网上是比较简单入门的,可以提前练练手)。对于自己训练数据大家可以参考我的博文。
YOLO使用了ImageNet数据集训练好的参数即Pre-Training,在这个基础之上在进行训练会使得收敛速度加快,同时为了获取更加细化的结果,将输入的图片分辨率调节为448*448.在激活函数中使用了Leaky RELU,防止过拟合加入了Dropout层,同时为了提高精度做了数据增强。(Dropout没有batch-normalization效果好,建议大家可以看看batch-normalization)。
6 损失函数
在做深度学习的童鞋们都应该知道,我们是通过降低损失来不断优化我们的模型,使我们的模型更加强壮,而在目标识别中损失函数较为简单,再加入检测时,会使得损失函数比较复杂,了解YOLO的损失函数构成,对我们以后的学习,代码的理解起到至关重要的作用。(本人自己的理解,若不对,请勿喷)
YOLO损失函数的设置时为了让坐标(x,y,w,h),confidence以及classification这个三个函数达到平衡,由于一张图中物体相对于背景占少数一部分,但是其数量过多且数值为0,很容易使得网络不稳定甚至发散。而且8维的location error与20维的classification占相同比例肯定不符合,于是YOLO模型的损失函数就如图所示。
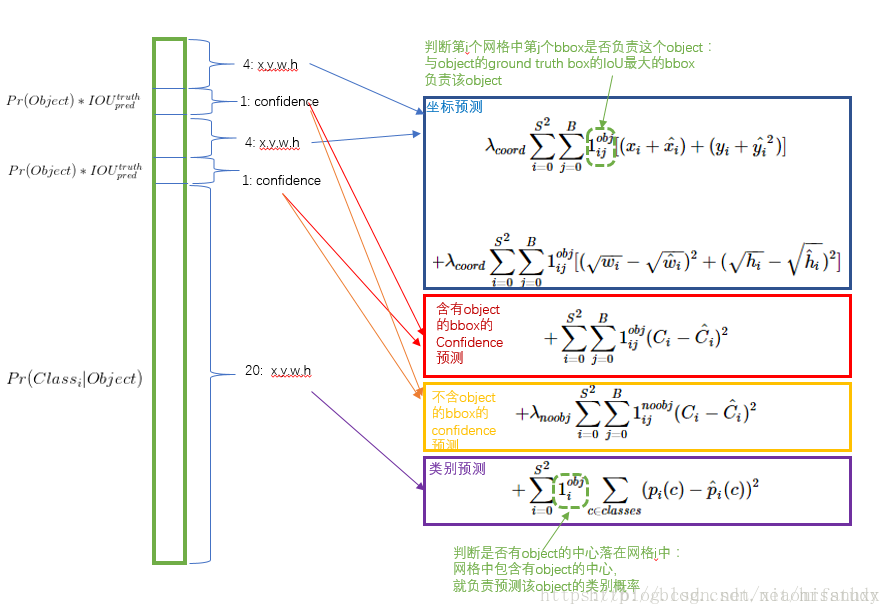
解决方案:更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为 λcoord ,在pascal VOC训练中取5。(上图蓝色框),对没有object的bbox的confidence loss,赋予小的loss weight,记为 λnoobj ,在pascal VOC训练中取0.5。(上图橙色框) 有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。 因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个 predictor就负责 predict object。 这会使得每个predictor可以专门的负责特定的物体检测。随着训练的进行,每一个 predictor对特定的物体尺寸、长宽比的物体的类别的预测会越来越好。
7 非极大值抑制(NMS)
由于每个grid cell都会生成若干个Bounding boxes,但是有可能不同的grid cell产生的Bounding boxes会产生交集,就此运用NMS来选择分数最高的,来抑制分数比较低的box,即去除掉冗余框。
我自己查阅博客然后进行理解,参考了诸多博客的内容加上自己的理解,阅读完论文,下一步就要去查看源码,来进行更深的理解,由于我也阅读了YOLOV2的论文,其改变的还是比较大,尤其是Bounding box的选取采用了改进K-means算法来实现的,我以后会对源码以及YOLOV2的一些特点进行分析。
参考资料:https://blog.csdn.net/hrsstudy/article/details/70305791
https://pjreddie.com/darknet/yolo/














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









