




 Flink是一款高性能的大数据处理引擎,支持流批一体化处理,具备低延迟、高吞吐、ExactlyOnce语义保证等特性。适用于事件驱动、数据分析及ETL管道应用。Flink提供丰富的窗口机制、状态管理、背压控制及复杂事件处理能力。
Flink是一款高性能的大数据处理引擎,支持流批一体化处理,具备低延迟、高吞吐、ExactlyOnce语义保证等特性。适用于事件驱动、数据分析及ETL管道应用。Flink提供丰富的窗口机制、状态管理、背压控制及复杂事件处理能力。
Flink概括
Apache Flink是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。
可部署在各种集群环境,对各种大小的数据规模进行快速计算。
Flink的重要特性
1、低延时、高吞吐
2、checkpoint
3、backpressure
4、ExactlyOnce保证了数据只会被消费一次
5、 状态管理的能力
6、 强大的时间窗口
7、 流批一体
flink应用场景有三类
-Event-driven Applications【事件驱动】
-Data Analytics Applications【分析】
-Data Pipeline Applications【管道式ETL】
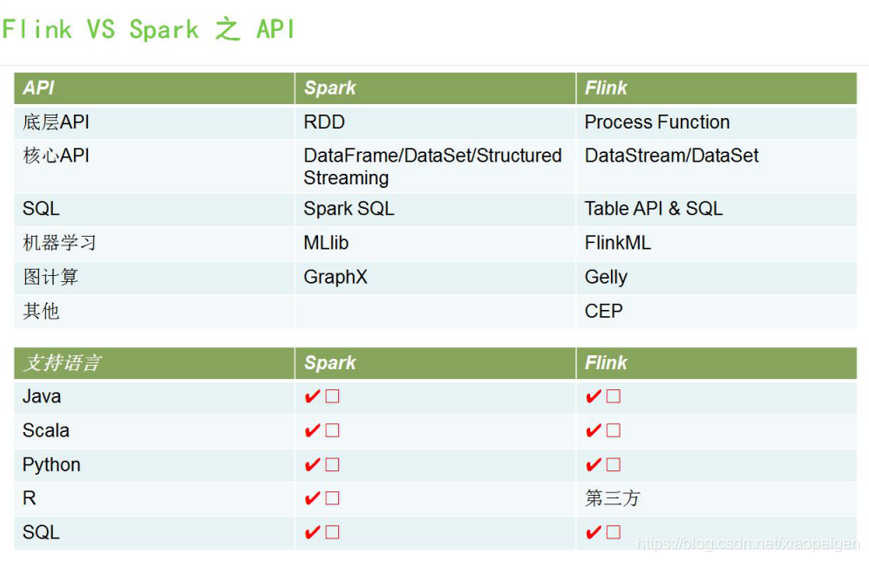
Flink的四层执行计划
1.StreamGraph
根据用户代码生成最初的图,表示程序的拓扑结构,在client端生成
2. JobGraph
优化streamgraph,将多个符合条件的Node chain在一起,在client端生成
3.ExecutionGraph
JobManger根据JobGraph生成,并行化
4·物理执行图
实际执行图,不可见
flink chain 划分
将符合条件的StreamNode 组成一个chain
没有禁用Chain
上下游算子并行度一致
下游算子的入度为1(也就是说下游节点没有来自其他节点的输入)
上下游算子在同一个slot group下游节点的chain策略为ALWAYS(可以与上下游链接,map.
flatmap、filter等默认是ALWAYS
上游节点的chain策略为ALWAYS或HEAD(只能与下游链接,不能与上游链接,Source默认是
HEAD)
上下游算子之间没有数据shuffle(数据分区方式是forward)
reduce和fold的不同点
1 reduce是组内的2个元素合并成一个同类型的新元素;fold是组内的每个元素与累加器(一开始是初始值initialValue)合并再返回累加器,累加器的类型可以与组内的元素类型不一致;
2 reduce可以用于DataStream或DataSet,但是fold只能用于DataStream。
min():获取的最小值,指定的field是最小,但不是最小的那条记录。
minBy():获取的最小值,同时也是最小值的那条记录。
join和cogroup
a、join只返回匹配到的数据对。若在window中没有能够与之匹配的数据,则不会有输出。
b、join会输出window中所有的匹配数据对。
c、不在window内的数据不会被匹配到。
cogroup无论能不能匹配,2边的数据都被coGroup到一起了
Window总结
Flink认为Batch是Streaming 的一个特例,所以Flink底层引擎是一个流式引擎,在上面实现了流
处理和批处理。而窗口(window)就是从Streaming 到Batch的一个桥梁。Flink提供了非常完善
的窗口机制,这是Flink最大的亮点之一(其他的亮点包括消息乱序处理,和checkpoint机制)。

Window Assigner:决定某个元素被分配到哪个/哪些窗口中去。
Trigger:触发器,触发窗口的计算或数据清除,每个WindowAssigner有一个默认的Trigger
Window的函数:函数里定义了应用于窗口(Window)内容的计算逻辑
Evictor:“驱逐者”,类似filter作用。在Trigger触发之后,window被处理前或者后,Evictor用来删除窗口
中无用的元素。默认没有驱逐器
Session window的特点为,没有固定的开始和结束时间,只要两个元素之间的时间间隔不大于设定值,就会分配到同一个window中,否则后来的元素会进入新的window。将window默认的trigger修改为count trigger。这里的含义为每到来一个元素,都会立刻触发计算。
processfunction
是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块:
事件、状态、定时器
watermark原理
实时系统中,由于各种原因造成的延时,造成某些消息发到lflink的时间延时于事件产生的时间。如果
基于event time构建window,但是对于late element,我们又不能无限期的等下去,必须要有个机
制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark
Watermarks(水位线)就是来处理这种问题的机制
参考google的DataFlow,是event time处理进度的标志
表示比watermark更早(更老)的事件都已经到达(没有比水位线更低的数据)
基于watermark来进行窗口触发计算的判断
只有基于EventTime的流处理程序需要指定Timestamp 和Watermarks的生成方式
方式1:直接在source function中生成
方式2: 通过AssigTimestampsAndWatermarks方法指定
两种Watermark
1. Periodic Watermarks
基于Timer
ExecutionConfig.setAutoWatermarkInterval(msec)(默认是200ms,设置watermarker"发送的周期)
实现AssignerWithPeriodicWatermarks接口
周期性调用getCurrentWatermark,如果获取的Watermark不等于null且比上一个最新的Watermark大
就向下游发射
2. Puncuated WaterMarks
基于某些事件触发watermark的生成和发送(由用户代码实现,例如遇到特殊元素)
实现AssignerWithPeriodicWatermarks 接口
Stream分类
Keyed Windows(在已经按照key分组的基础上(KeyedStream),再构建多任务并行window)
Non-Keyed Windows(在未分组的DataStream上构建单任务window,并行度是1,API都带AlI后缀)
状态
1、Operator State
绑定到特定operator并行实例,每个operator的并行实例维护一个状态;与key无关
2、Keyed State
基于KeyedStream之上的状态,dataStream.keyBy(),只能在作用于function/Operator里使用
KeyBy之后的Operator State,可理解为分区过的Operator State
每个并行keyed Operator的每个实例的每个key有一个Keyed State
3、Broadcast State
processBroadcastElement
ctx.getBroadcastState(queryDescriptor).put(query.getQueryId(), query);
processElement
ctx.getBroadcastState(queryDescriptor).immutableEntries()
一个并行度为3的source有3个状态,只和并行度有关
一个并行度为3的keyed operator有key*3个状态
状态分为托管状态和原始状态
(1)原始状态是有用户自行管理的具体的数据结构,需要序列化,当用户自定义operator时会用到
需要实现 CheckpointedFunction接口
(2)托管状态是由flink框架管理的状态,如valuestate,liststatue,mapstate
通过框架提供的接口来更新和管理状态的值,不需要序列化
TTL生存时间 Time To Liv
状态值已过期,则将以最佳方式清理;TTL目前只支持ProcessingTime
每个operator、data source或者data sink都可以通过调用setParallelism()方法来指定parallelism
背压
背压警告(如 High 级别),这意味着生成数据的速度比下游算子消费的的速度快
Streaming 的背压主要是根据下游任务的执行情况等,来控制上游的速率。Flink 的背压是通过一定时间内堆栈跟踪,监控阻塞的比率来确定背压的。
CEP(Complex Event Processing)
就是在无界事件流中检测事件模式,让我们掌握数据中重要的部分。flink CEP是在flink中实现的复杂事件处理库
目标:从简单事件流中发现一些高阶特征
输入:一个或者多个简单事件构成的事件流
处理:检测简单事件之间的联系,多个事件组合一起符合匹配规则,将该多个事件构成复杂事件
输出:符合规则的复杂事件
序列化
大多数情况下,用户不用担心flink的序列化框架,flink可以自己推断出数据的类型信息,不能推断的则采用kryo或者其他方式序列化
类型推断->自带的类型系统来处理->kryo->其他
Flink支持非常完善的数据类型,数据类型的描述信息都是由TypeInformation定义。TypeInformation主要作用是在分布式计算过程中对数据的数据类型进行管理和推断
多数情况下用户无需关系类型处理,用户与flink的数据类型处理包括:
注册子类型、注册自定义序列化、添加类型提示、手动创建typeinformation
checkpoint
checkpoint是把job的所有状态都周期性持久化到存储里,当出现故障时,从最新的一次检查点恢复
默认状态下,检查点不被保留,仅用于从故障中恢复作业
checkpointmode:exactly_once/at_least_once
提供exactly_once语意保证,只保证flink内部,对于sink和source需要依赖外部组件
一般情况下选择exactly_once,除非场景要求极低的延迟
checkpoint的保留策略
DELETE_ON_CANCELLATION:仅当作业失败时,作业的 Checkpoint 才会被保留用于任务恢复。当作业取消时,Checkpoint 状态信息会被删除,因此取消任务后,不能从 Checkpoint 位置进行恢复任务。
RETAIN_ON_CANCELLATION:当作业手动取消时,将会保留作业的 Checkpoint 状态信息。注意,这种情况下,需要手动清除该作业保留的 Checkpoint 状态信息,否则这些状态信息将永远保留在外部的持久化存储中。
所以:无论配合何种策略,如果 Flink 任务失败了,Checkpoint 的状态信息将被保留
state backend 组件有三种
memorystatebackend:state保存在taskmanager的内存中,快照存储在jobmanager的内存中
fsstatebackend:文件的路径等元数据传递给jobmanager的内存
rocksdbstatebackend:文件的路径等元数据传递给jobmanager的内存,支撑增量checkpoint
每一个barrier都带有快照ID,barrier之前的数据都进入此快照
barrier被插入到数据流中,作为数据流的一部分和数据一起向下流
barrier 对齐就是 Exactly Once,barrier 不对齐就是 At Least Once
有两个输入流,一个数字流,一个字母流,一旦Operator从输入流接收到数字流 barrier n,它就不能处理来自该流的任何数据记录,直到它从其他所有输入接收到barrier n为止;接收到barrier n的流暂时被搁置。从这些流接收的记录不会被处理,而是放入输入缓冲区
barrier在数据源端插入,当snapshot n的barrier插入后,系统记录当前snapshot的位置值,当一个operator从其输入流接收到所有标识snapshot n的barrier时,它会向其所有输出流插入一个标识snapshot n的barrier。当sink operator接收到snapshot n的barrier时,快照就被标识为完成
整个checkpoint的过程是operator实例填格子的过程,所有实例的状态都填满后,认为一次完整的checkpoint
savepoint由两部分组成
数据目录:稳定存储的目录,保存状态快照
元数据文件:指向数据目录属于当前savepoint的数据文件的指针
两阶段提交
(1)预提交阶段:
1. JobManager会周期性的发送执行checkpoint命令;
2.当source端收到执行指令后会产生一条barrier消息插入到input消息队列中,当处理到barrier时会执行本地checkpoint, 并且会将barrier发送到下一个节点,当checkpoint完成之后会发送一条ack信息(确认字符)给JobManager;
3.当DAG图中所有节点都完成checkpoint之后,JobManager会收到来自所有节点的ack信息,表示一次完整的checkpoint的完成。如果发生故障,我们可以回滚到上次成功完成快照的时间点。
(2)提交阶段:JobManager 为应用程序中的每个 operator 发出 checkpoint 已完成的回调,
通知所有 operator,checkpoint 已经成功了。
在预提交成功之后,提交的 commit 需要保证最终成功 - operator 和外部系统都需要保障这点。如果 commit 失败(例如,由于间歇性网络问题),整个 Flink 应用程序将失败,应用程序将根据用户的重启策略重新启动,还会尝试再提交。这个过程至关重要,因为如果 commit 最终没有成功,将会导致数据丢失。
Flink on Yarn
(yarn session 和 flink run 两种模式)
session:这种方式需要先向yarn申请一块空间后,再提交作业,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交,这种方式资源被限制在session中,不能超过
flink run:一个任务会对应一个job,每提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行。这种方式就需要确保集群资源足够。
Flink on Yarn的两种运行方式
第一种【yarn-session.sh(开辟资源)+flink run(提交任务)】
启动一个一直运行的flink集群
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 [-d]
附着到一个已存在的flink yarn session
./bin/yarn-session.sh -id application_1463870264508_0001
执行任务
./bin/flink run ./data/batch/WordCount.jar -input hdfs://hadoop00:9000/LICENSE -output hdfs://hadoop00:9000/wordcount-result.txt
停止任务 【web界面或者命令行执行cancel命令】
第二种【flink run -m yarn-cluster(开辟资源+提交任务)】
启动集群,执行任务
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./data/batch/WordCount.jar
kafka乱序解决方法
kafka提供了接口来实现根据指定的 key 值发送到同一 partition 的方法;在 producer 发送数据时,选择一个 key,通过 KeyedMessage 方法生成消息,然后 send


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









