






1.1 什么是机器学习
机器学习或ML一个流行的定义,来源于Tom Mitchell[1],如下:
如果一个计算机程序在 T 类任务中的表现(用 P 来衡量)随着经验 E 的增加而提高,那么它被认为是在经验E上学习了任务T。
[1]T. Mitchell. Machine Learning. McGraw Hill, 1997.
因此,有许多不同类型的机器学习,这取决于T的性质、P的性质以及经验E的性质。
在这本书中,我们将从概率的角度介绍最常见的ML类型。粗略地说,这意味着我们将所有未知量(例如,明天的温度或某个模型的参数)视为随机变量,这些变量被赋予概率分布,该概率分布描述了变量可能具有的值。(如有必要,请参阅第2章快速复习,概率基础知识。)
我们采用概率方法的主要原因有两个。首先,这是在不确定性下进行决策的最佳方法(第5章介绍)。其次,概率建模是大多数其他科学和工程领域使用的语言,因此在这些领域之间提供了一个统一的框架。
正如DeepMind的研究员Shakir Mohamed所说:
几乎所有的机器学习都可以从概率的角度来看待,这使得概率思维成为基础。当然,这并不是唯一的角度。但正是通过这种角度,我们可以将机器学习中所做的工作与其他所有计算科学联系起来,无论是在随机优化、控制理论、运筹学、计量经济学、信息论、统计物理学还是生物统计学中。仅出于这个原因,掌握概率思维也是非常重要的。
1.2 监督学习
ML最常见的形式是监督学习.在这个问题中,任务T是:学习从输入到输出
的映射
。输入
也被称为特征、协变量或预测变量;通常是一个固定维度的数字向量,例如一个人的身高和体重,或者一幅图像中的像素。在这种情况下,
,其中D是向量的维度(即输入特征的数量)。输出
也称为标签、目标或响应。经验E给出了输入-输出集的形式,即
,(原文为
,译者认为有误)称为训练集。(N称为样本量。)性能指标P取决于我们预测的输出类型,如下所述。
注意:有时(例如,在statsmodels Python包中)x被称为外生变量,y被称为内生变量。
1.2.1 分类
在分类问题中,输出空间是一组无序且互斥的标签,称为类,Y={1,2,…,C}。在给定输入的情况下预测标签类的问题也称为模式识别。(如果只有两个类,通常用y∈{0,1}或y∈{−1,+1}表示,则称为二元分类。)
1.2.1.1 例子:鸢尾花分类
例如,考虑将鸢尾花分为3个亚种,Setosa、Versicolor和Virginica的问题。图1.1显示了每个类的一个示例。

在图像分类中,输入空间X是图像集,这是一个非常高维的空间:对于具有C=3个通道(例如RGB)和D1×D2像素的彩色图像,我们有,其中D=C×D1×D2。(在实践中,我们用一个整数来表示每个像素强度,通常在{0,1,…,255}的范围内,但为了表示简单,我们假设光强度真实值为输入。)学习,
,从图像x到标签y是相当具有挑战性的,如图1.2所示。
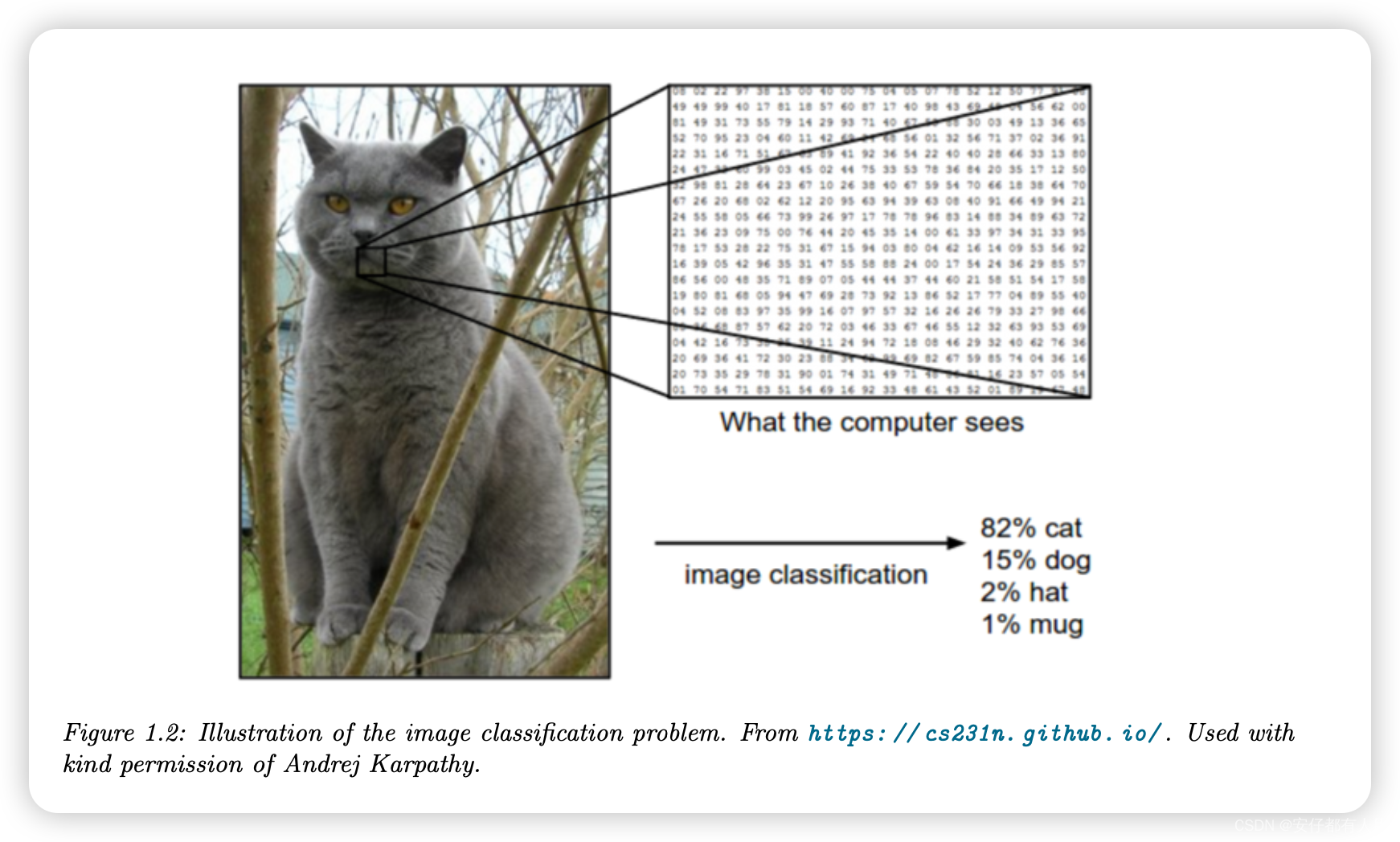
然而,它可以使用某些类型的函数来处理,例如卷积神经网络(CNN),我们将在第14.1节中讨论。幸运的是,一些植物学家已经确定了4个简单但信息量大的数字特征——萼片长度、萼片宽度、花瓣长度、花瓣宽度——可以用来区分这三种鸢尾花。在本节中,为了简单起见,我们将使用这个低维得多的输入空间,。Iris数据集是150个标记的Iris花实例的集合,每种类型50个,由这4个特征描述。它被广泛用作例子,因为它很小,理解起来很简单。(我们将在本书后面讨论更大、更复杂的数据集。)
当我们有小的特征数据集时,通常将它们存储在N×D矩阵中,其中每行表示一个示例,每列表示一个特征。这被称为设计矩阵(design matrix);示例见表1.1。
这个特殊的设计矩阵有N=150行和D=4列,因此具有高而瘦的形状,因为N远远大于D。相比之下,一些数据集(例如基因组学)示例D远远大于N,它具有更多的特征;它们的设计矩阵又短又胖。术语“大数据”通常意味着N很大,而术语“宽数据”意味着D很大(相对于N)。
Iris数据集是表格数据的一个示例。当输入是可变大小时(例如,单词序列或社交网络),而不是固定长度的向量时,数据通常以其他格式存储,而不是以设计矩阵存储。然而,这种数据通常被转换为固定大小的特征表示(一种称为特征化的过程),从而隐含地创建设计矩阵。我们将在第1.5.4.1节中给出一个例子,其中我们将讨论序列数据的“bag of words”(词袋)表示。
1.2.1.2 探索性的数据分析
在解决ML问题之前,通常最好探索性分析一下数据,看看是否存在任何明显的模式(这可能会提示应该选择什么方法),或者数据是否存在任何显著的问题(例如,标签噪声或异常值)。
对于具有少量特征的表格数据,通常制作pair plot,其中面板上的(i,j)显示变量i和j的散点图,对角线的图(i,i)显示变量i的边缘密度;所有的绘图都可以选择用类标签进行颜色编码——示例见图1.3。

对于高维数据,通常先执行降维,然后以2d或3d形式可视化数据。我们将在第20章中讨论降维方法。
1.2.1.3 学习一个分类器
从图1.3中,我们可以看到Setosa类很容易与其他两个类区分开来。例如,假设我们创建以下决策规则:
这是分类器的一个非常简单的例子,其中我们将输入空间划分为两个区域,由一维(1d)决策边界定义。位于该边界左侧的点被归类为Setosa;右边的点是Versicolor或Virginica。
我们看到这个规则完美地分类了Setosa的例子,但没区分Virginica和Versicolor的例子。为了提高性能,我们可以通过进一步的划分空间来达到。例如,我们可以添加另一个决策规则,将其应用于第一次分类失败的输入,以检查花瓣宽度是否低于1.75cm(预测为Versicolor)或高于1.75cm(预测为Virginica)。我们可以将这些嵌套规则排列成树结构,称为决策树,如图1.4a所示。这导致了图1.4b所示的2d决策面。
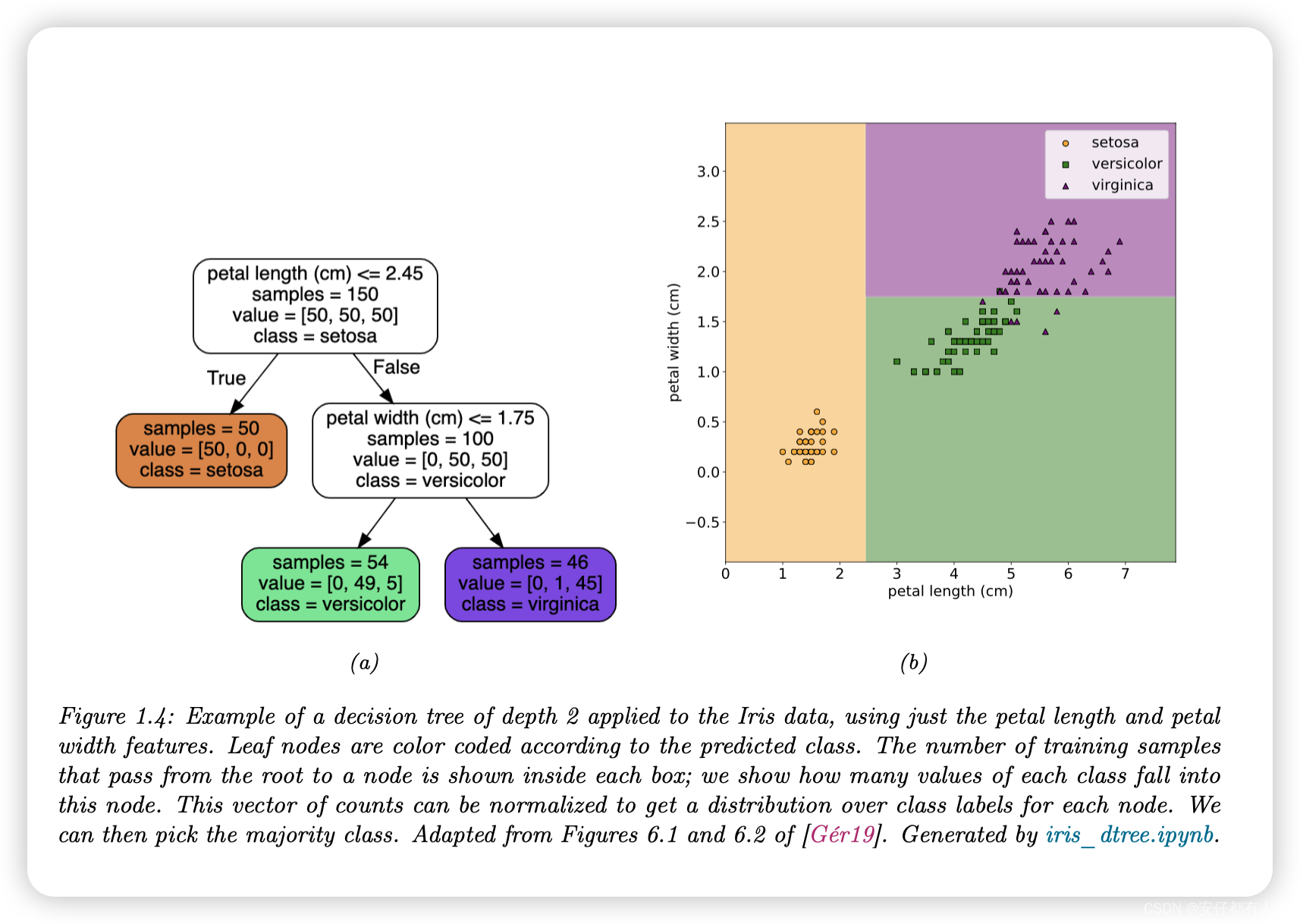
我们可以通过为每个节点存储索引以及相应的阈值来表示树。我们用θ来表示所有这些参数。我们将在第18.1节中讨论如何学习这些参数。
1.2.1.4 经验风险最小化(empirical risk minimization)
译者名词解释:经验风险。
经验:指训练集,这些都可称为经验。
风险:指预测结果和实际结果之间的差距。
经验风险:指根据经验,得到的预测值和真实值之间的差距。我们希望真实值和预测值之间的差距尽可能的小。因此要使经验风险最小化。
监督学习的目标是自动构建分类模型,如图1.4a所示,以便可靠地预测任何给定输入的标签。这个任务的一种常见衡量指标是训练集的错误分类率:
此处是示性函数,当且仅当e为真时,返回1.否则返回0。即:
这假设所有错误都是相等的。然而,有些错误可能比其他错误代价更高。例如,假设我们在荒野中觅食,发现了一些鸢尾花。此外,假设Setosa和Versicolor很美味,但Virginica有毒。在这种情况下,我们可以使用表1.2中所示的不对称损失函数

然后,我们可以将这种经验风险定义为预测器在训练集上的平均损失:
我们看到,当我们使用zero-one损失来比较真实标签和预测时,错误分类率方程(1.2)等于经验风险:
详见第5.1节。
定义模型拟合或训练问题的一种方法是找到一组参数,使训练集上的风险最小化:
这被称为经验风险最小化(empirical risk minimization)。
然而,我们真正的目标是,将我们尚未看到的数据的预期损失降至最低。也就是说,我们想要模型泛化,而不仅仅是在训练集中表现出色。我们将在第1.2.3节中讨论这一重要问题。
1.2.1.5 不确定性
译者名词解释:不确定性
不确定性:指的是模型的输出,并非一个值,而是一组可能的值,这些值的概率有高有低。
我们必须避免因对世界概率性质的无知而产生的错误自信,也要避免在我们应该看到灰色的地方,却渴望看到黑白分明。— 由玛利亚·康尼科娃(Maria Konnikova)改述的伊曼努尔·康德
参考:M. Konnikova. The Biggest Bluff: How I Learned to Pay Attention, Master Myself, and Win. en. Penguin Press, 2020.
在许多情况下,由于缺乏input-output映射的知识(这被称为认识不确定性或模型不确定性),和/或由于映射中固有的(不可分割的)随机性(这被称作任意不确定性或数据不确定性)。
在我们的预测中表示不确定性对于各种应用都很重要。例如,让我们回到有毒花卉的例子,其损失矩阵如表1.2所示。如果我们预测这种花很有可能是Virginica,那么我们就不应该吃这种花。另外,我们可以执行信息收集操作,例如执行诊断测试,以减少我们的不确定性。有关如何在不确定性存在的情况下做出最佳决策的更多信息,请参阅第5.1节。
我们可以使用以下条件概率分布来得到我们的不确定性:
此处将输入映射到C个可能标签上的概率分布。因为
返回标签c的概率,因此
,且
.为了避免这种限制,通常要求模型返回未规范化的对数概率。然后,我们可以使用softmax函数将这些转换为概率,定义如下
这个映射到
,并且满足
,
.softmax函数的输入
被称为logit。详见2.5.2节。因此,我们将整体模型定义如下:
这种情况的常见特例是当 f 是形式如下的仿射函数时:
其中θ=(b,w)是模型的参数。这个模型被称为逻辑回归,将在第10章中进行更详细的讨论。
在统计学中,w参数通常称为回归系数(通常用β表示),b称为截距。在ML中,参数w称为权重,b称为偏差。这个术语源于电气工程,在电气工程中,我们将函数f视为一个接收x并返回f(x)的电路。每个输入都通过“导线”馈送到电路,导线的权重为w。电路计算其输入的加权和,并添加恒定的偏置或偏移项b。(“偏差”一词的使用不应与第4.7.6.1节中讨论的偏差统计概念相混淆。)
为了减少记号的杂乱,通常通过定义和定义
将偏置项b吸收到权重w中,使得:
这将仿射函数转换为线性函数。所以我们只需将预测函数写如下:
1.2.1.6 最大似然估计
在拟合概率模型时,通常使用负对数概率作为我们的损失函数:
其原因在第5.1.6.1节中进行解释,但直觉是,一个好的模型(具有低损失)是指为每个相应的(x,y)分配高概率的模型。训练集的平均负对数概率由下式给出
这被称为负对数似然。如果我们将其最小化,我们可以计算最大似然估计或MLE:
正如我们将看到的,这是一种非常常见的将模型与数据相匹配的方法。
1.2.2 回归
译者注:
在统计学中,“回归”一词的由来可以追溯到19世纪,当时由英国天文学家和数学家弗朗西斯·高尔顿提出了"最小二乘回归"的概念。他研究了天文观测数据,试图找到一种方法来拟合曲线以预测行星位置。高尔顿注意到,如果他将观测到的数据点与拟合曲线之间的误差的平方和最小化,就可以得到一个很好的拟合曲线。这一方法后来被称为最小二乘法。
"回归"一词本身来自于拉丁语 "regredi",意思是"返回"或"恢复"。在这个上下文中,"回归"指的是通过观察到的数据来推断或恢复变量之间的关系,从而进行预测或解释。因此,"回归分析"旨在理解变量之间的关系,并用于预测或解释一个或多个因变量与自变量之间的关系。
现在假设我们想要预测实值量y∈R,而不是类标签y∈{1,…,C};这就是所谓的回归。例如,在鸢尾花的情况下,y可能是食用该花的毒性程度,或者是植物的平均高度。
回归与分类非常相似。然而,由于输出是实值的,我们需要使用不同的损失函数。对于回归,最常见的选择是使用二次损失,或l2损失:
对于较大差值的惩罚大于较小的差值。 使用二次损失函数的经验风险等于均方误差或MSE:
根据第1.2.1.5节的讨论,我们还应该对预测中的不确定性进行建模。在回归问题中,通常假设输出分布是高斯分布或正态分布。正如我们将在第2.6节中所解释的,这种分布定义为:
此处,是均值,
是方差。
是保证概率密度函数积分为1的归一化常数。在回归的背景下,我们可以通过定义μ=f(xn;θ)使平均值取决于输入。因此,我们得到以下条件概率分布:
如果我们假设方差是固定的(为了简单起见),则对应的平均值(每个样本)负对数似然变为:
我们看到NLL与MSE成比例。因此,计算参数的最大似然估计将导致平方误差最小化,这似乎是一种合理的模型拟合方法。
1.2.2.1 线性回归
作为回归模型的一个例子,请考虑图1.5a中的1d数据。我们可以使用以下形式的简单线性回归模型来拟合这些数据:
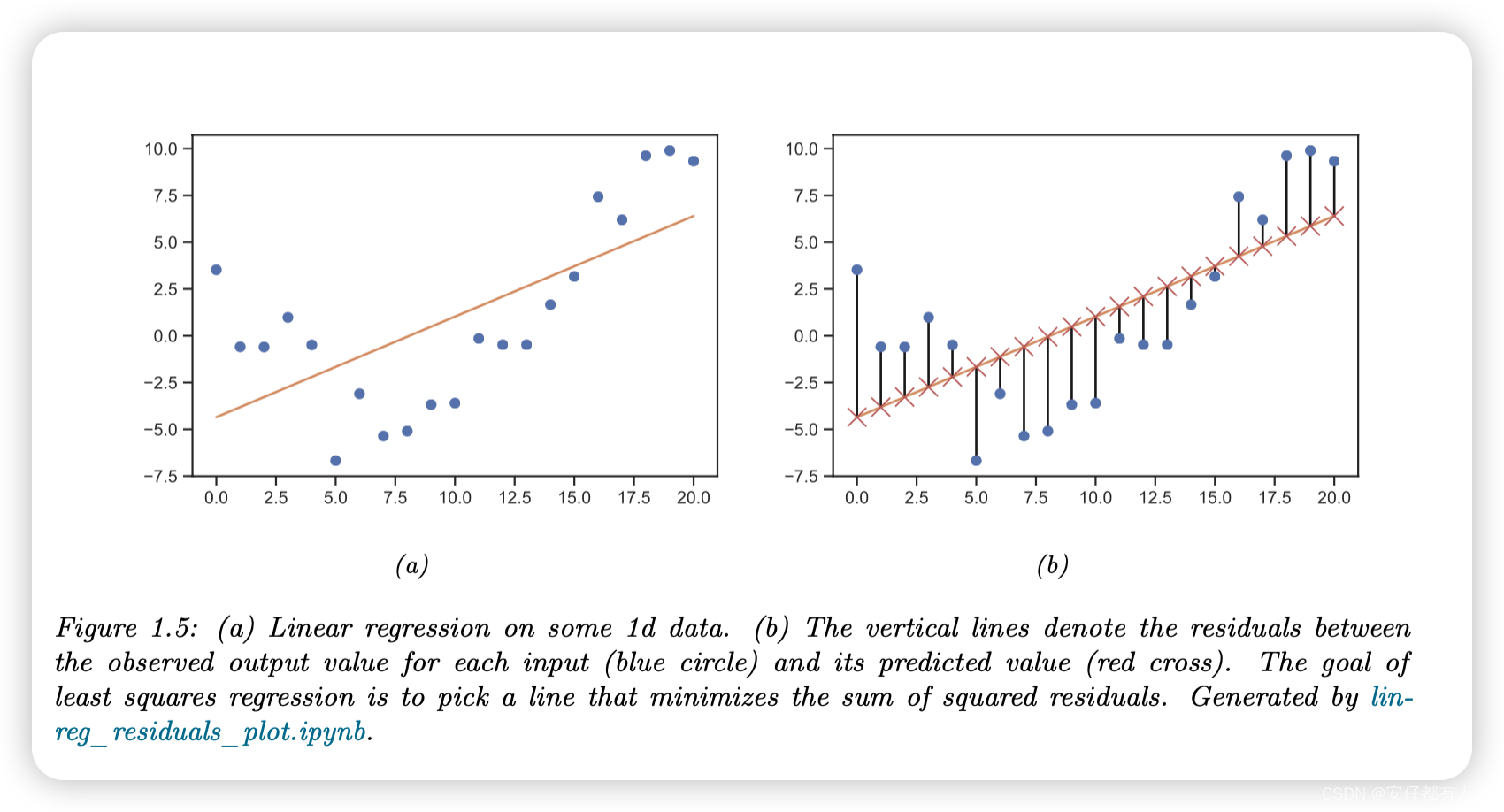
其中w是斜率,b是偏移,θ=(w,b)是模型的所有参数。通过调整θ,我们可以最小化均方误差和,如图1.5b中的垂直线所示。
详见第11.2.2.1节。
如果我们有多个输入特征,我们可以写作:
其中θ=(w,b)。这被称为多元线性回归。
例如,考虑房间中二维位置与温度的关系。图1.6(a)绘制了以下形式的线性模型的结果:
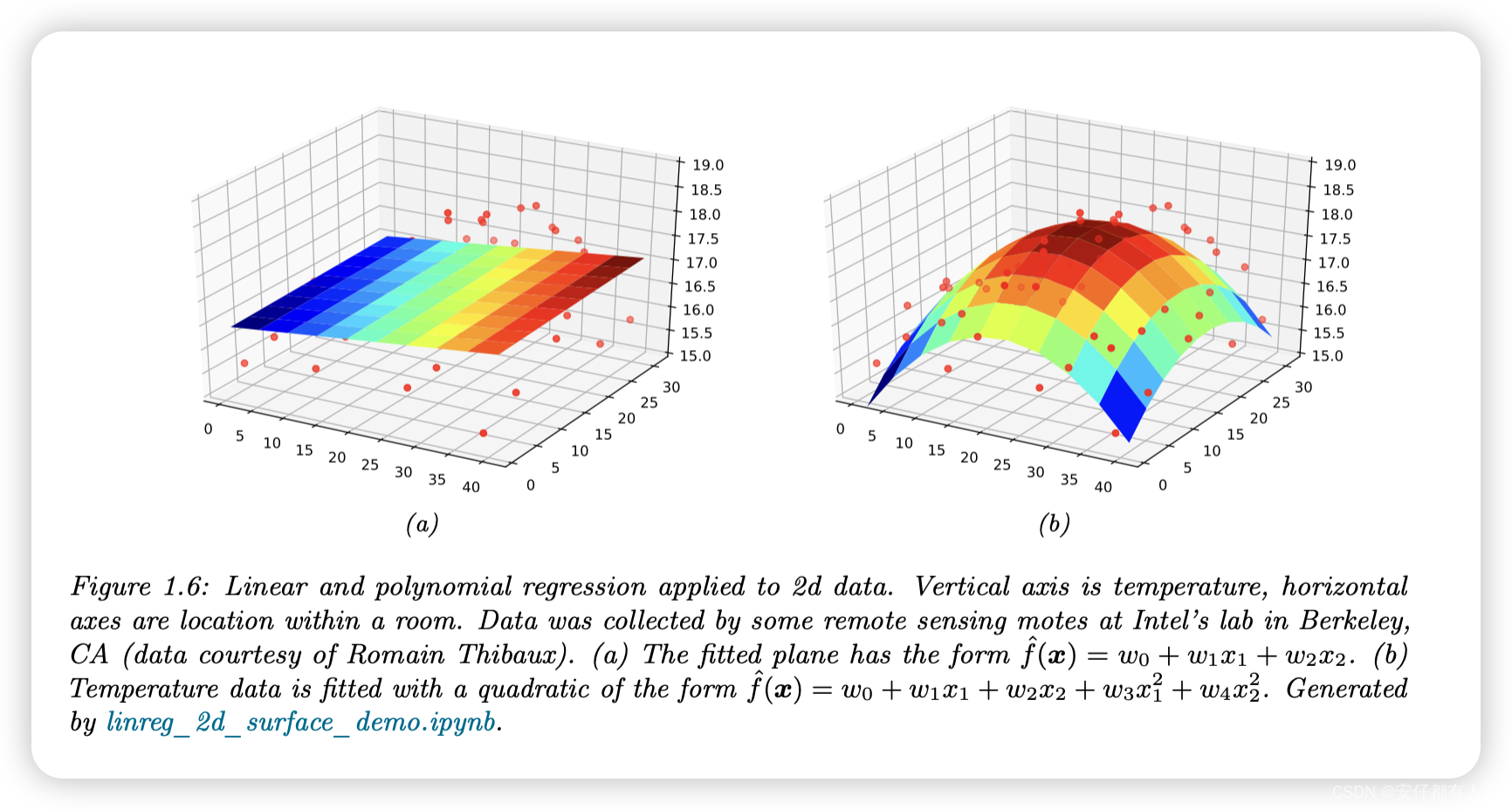
我们可以将该模型扩展为特征大于2(如一天中的时间),但它不利于可视化。
1.2.2.2 多项式回归
图1.5a中的线性模型显然并不非常适合数据。我们可以通过使用D阶多项式回归模型来改善拟合度。其形式为,其中
是从输入导出的特征向量,具有以下形式:
这是一个简单的特征预处理示例,也称为特征工程。
在图1.7a中,我们看到使用D=2可以得到更好的拟合。我们可以不断增加D,从而增加模型中的参数数量,直到D=N−1;在这种情况下,我们每个数据点有一个参数,所以我们可以完美地计算数据。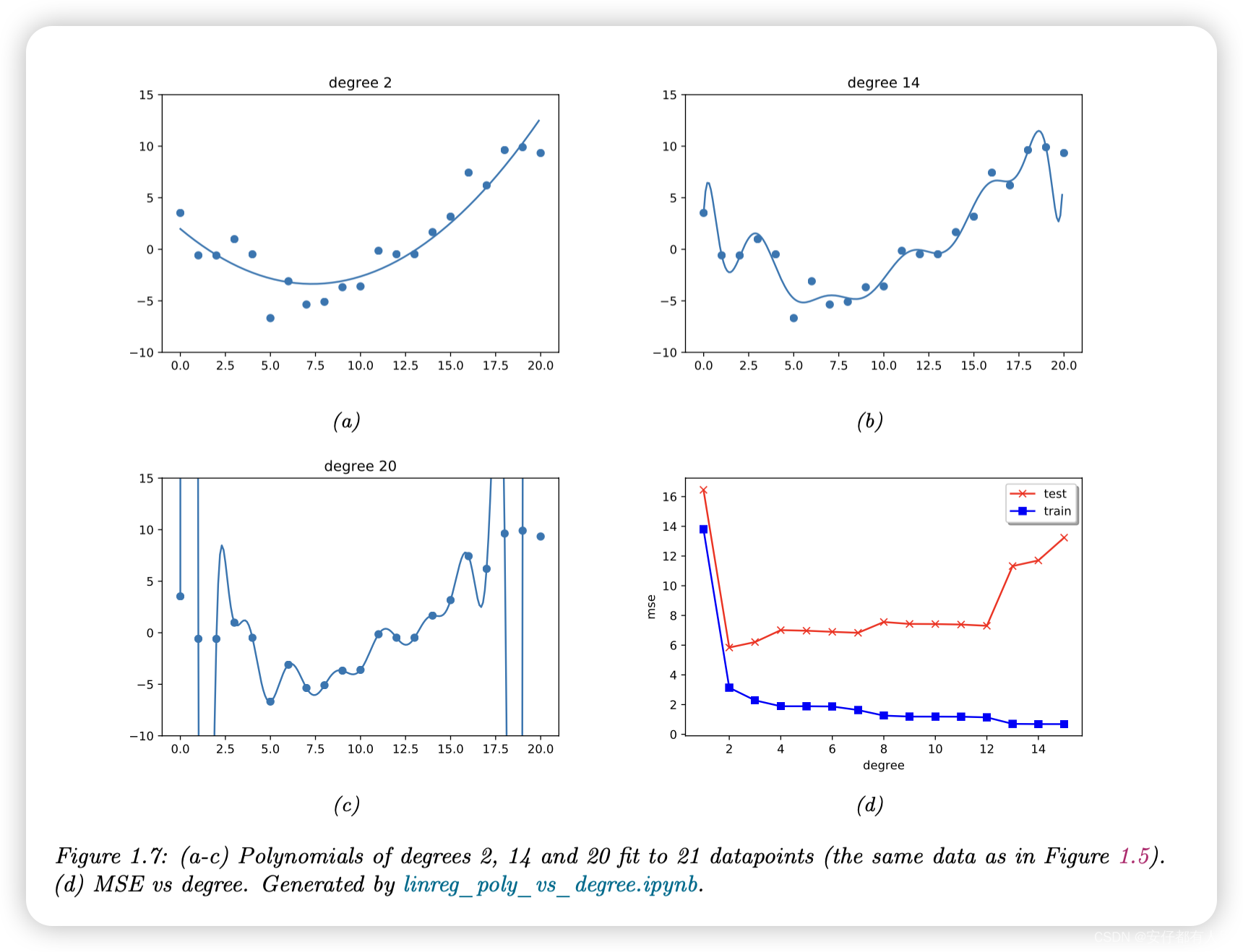
得到的模型将具有0 MSE,如图1.7c所示。然而,直观地说,结果函数并不能很好地预测未来的输入,因为它太“摆动”了。我们将在第1.2.3节对此进行更详细的讨论。
我们还可以将多项式回归应用于多维输入。例如,图1.6(b)绘制了对输入进行二次展开后温度模型的预测。
与图1.6(a)中的线性模型相比,二次型更适合数据,因为它捕捉到了房间中间更热的事实。我们还可以添加交叉项,如x1x2,以捕捉交互效果。详见第1.5.3.2节。
请注意,上述模型使用的预测函数仍然是参数 w 的线性函数,尽管它是原始输入 x 的非线性函数。这一点之所以重要,是因为线性模型会产生 MSE 损失函数 MSE(θ),而 MSE(θ)具有唯一的全局最优值,这一点我们将在第 11.2.2.1 节中解释。
1.2.2.3 深度神经网络
在第 1.2.2.2 节中,我们手动指定了输入特征的变换,即多项式展开, 。通过自动学习这种非线性特征提取,我们可以创建功能更强大的模型。如果我们让
有自己的一组参数,例如 V,那么整个模型的形式为:
我们可以递归地将特征提取器 分解为更简单的函数组合。这样,模型就变成了一个由 L 个嵌套函数组成的堆栈:
其中,是第 l 层的函数。最后一层是线性的,其形式为
.因此
其中
是学习到的特征提取器。这是深度神经网络(DNN)背后的关键思想,其包括诸如用于图像的卷积神经网络(CNNs)和用于序列的递归神经网络(RNN)的常见变体。详见第三部分。
1.2.3 过度拟合和泛化
译者名词解释:拟合
拟合:指"符合",有动词和名词的意思。
过度拟合:指,过度符合,也即模型过度符合训练集了。事实上一个训练集(也可称为经验)除了含有事物之本质以外,还含有噪声。过度拟合,其实相当于记住了太多的噪声。
我们可以用以下等效方式重写方程(1.4)中的经验风险:
其中是训练集
的大小。这个公式很有用,因为它明确了在哪个数据集上评估损失。
有了一个适当灵活的模型,我们可以通过简单地记住每个输入的正确输出,将训练损失降到零(假设没有标签噪声)。例如,图1.7(c)完美地记住了训练数据(最右边最后一点除外)。但我们关心的是新数据的预测准确性,这些数据可能不是训练集的一部分。一个完美拟合训练数据但过于复杂的模型被认为存在过拟合问题。
为了检测一个模型是否过拟合,现在假设我们能够访问用来生成训练集的真实(但未知)分布。然后,我们不是计算经验风险,而是计算理论预期损失或总体风险。
差值被称为泛化差距。如果一个模型有一个大的泛化差距(即,低经验风险但高总体风险),这是它过拟合的一个迹象。
在实践中,我们不知道p*。然而,我们可以将现有数据划分为两个子集,即训练集和测试集。然后我们可以使用测试风险来近似估计总体风险。
例如,在图1.7d中,我们绘制了多项式回归的训练误差和测试误差随着模型最高次幂D变换的曲线。我们可以看到,随着模型变得更复杂,训练误差趋向于0。然而,测试误差呈现出U形曲线:在左侧,当D=1时,模型存在欠拟合现象;在右侧,当D远大于1时,模型存在过拟合现象;而当D=2时,模型的复杂度“刚刚好”。
如何选择合适复杂度的模型?如果我们使用训练集来评估不同的模型,我们总会选择最复杂的模型,因为那会有最多的高次项,因此会有最小的损失。所以我们应该选择测试集上损失最小的模型。
在实践中,我们需要将数据划分为三个集合,即训练集、测试集和验证集;后者用于模型选择,我们仅使用测试集来估计未来的表现(总体风险),即测试集不用于模型拟合或模型选择。更多细节见第4.5.4节。
1.2.4 没有免费午餐定理
所有模型都是错误的,但一些模型是有用的。 — George Box
引用:G. Box and N. Draper. Empirical Model- Building and Response Surfaces. Wiley, 1987.
鉴于文献中模型的巨大多样性,很自然地会想哪一个模型是最好的。不幸的是,没有单一的最佳模型能够在所有类型的问题上都表现最优 — 这有时被称为无免费午餐定理 [1]。原因是,在一个领域中表现良好的一组假设(也称为归纳偏差)在另一个领域中可能表现糟糕。选择合适模型的最佳方式是:基于领域知识,和/或实验、试错(例如,使用模型选择技术如交叉验证(第4.5.4节)或贝叶斯方法(第5.2.2节和第5.2.6节)。因此,拥有许多模型和算法技术在自己的工具箱中以供选择是很重要的.
1. D. Wolpert. “The lack of a priori distinc- tions between learning algorithms”. In: Neu- ral Computation 8.7 (1996), pp. 1341–1390.
1.3 非监督学习
在监督学习中,我们假设训练集中的每个输入样本x都有一个相关的输出目标集y,我们的目标是学习输入输出之间的映射。虽然这很有用,但它很难,本质上,监督学习只是“高级曲线拟合”[Peal18]。
[Peal18]:J. Pearl. Theoretical Impediments to Ma- chine Learning With Seven Sparks from the Causal Revolution. Tech. rep. UCLA, 2018.
一个可以说更有趣的任务是尝试“理解”数据,而不仅仅是学习映射。也就是说,我们只有“输入”而没有相应的“输出”。这被称为无监督学习。
从概率的角度来看,我们可以将无监督学习的任务视为拟合一个无条件模型,形式为p(x),它可以生成新的数据x,而监督学习涉及拟合一个条件模型,p(y|x),它指定了给定输入的输出(分布)。
无监督学习避免了收集大量标记数据集,这通常是耗时且昂贵的(想想让医生标记医学图像)。
无监督学习也避免了 将世界划分为任意的类别。例如,在视频中出现 "喝水 "或 "啜饮 "等动作时,考虑该怎么标注这些时刻。是当人拿起杯子时,还是当杯子第一次接触到嘴时,还是当液体倒出时?如果他们倒出一些液体,然后停顿一下,接着再倒,这是两个动作还是一个动作?在这些问题上,人类经常会产生分歧 [Idr+17],这就意味着任务的定义并不明确。因此,期望机器学习此类映射是不合理的。
[Idr+17]:H. Idrees, A. R. Zamir, Y.-G. Jiang, A. Gor- ban, I. Laptev, R. Sukthankar, and M. Shah. “The THUMOS challenge on action recogni- tion for videos “in the wild””. In: Comput.Vis. Image Underst. 155 (2017), pp. 1–23.
最后,无监督学习迫使模型 "解释 "高维输入,而不仅仅是低维输出。这样,我们就能学习到 "世界如何运转 "的更丰富的模型。正如多伦多大学著名的 ML 教授杰夫-辛顿(Geoff Hinton)所说:"无监督学习迫使模型'解释'高维输入,而不仅仅是低维输出:
当我们学习观察时,没有人会告诉我们正确的答案是什么--我们只是看。每隔一段时间,你妈妈就会说 "那是一只狗",但这只是很少的信息。如果你能通过这种方式获得几个比特的信息,甚至是每秒一个比特的信息,那你就很幸运了。大脑的视觉系统有
个神经连接。而人的生命只有
秒。因此,每秒学习一个比特是没有用的。你需要的是每秒 O
个比特。而只有一个地方可以获得这么多信息:从输入本身。- 杰弗里-辛顿,1996 年
(引自:P. F. Gorder. “Neural Networks Show New Promise for Machine Vision”. In: Computing in science & engineering 8.6 (2006), pp. 4–8.)
1.3.1 聚类
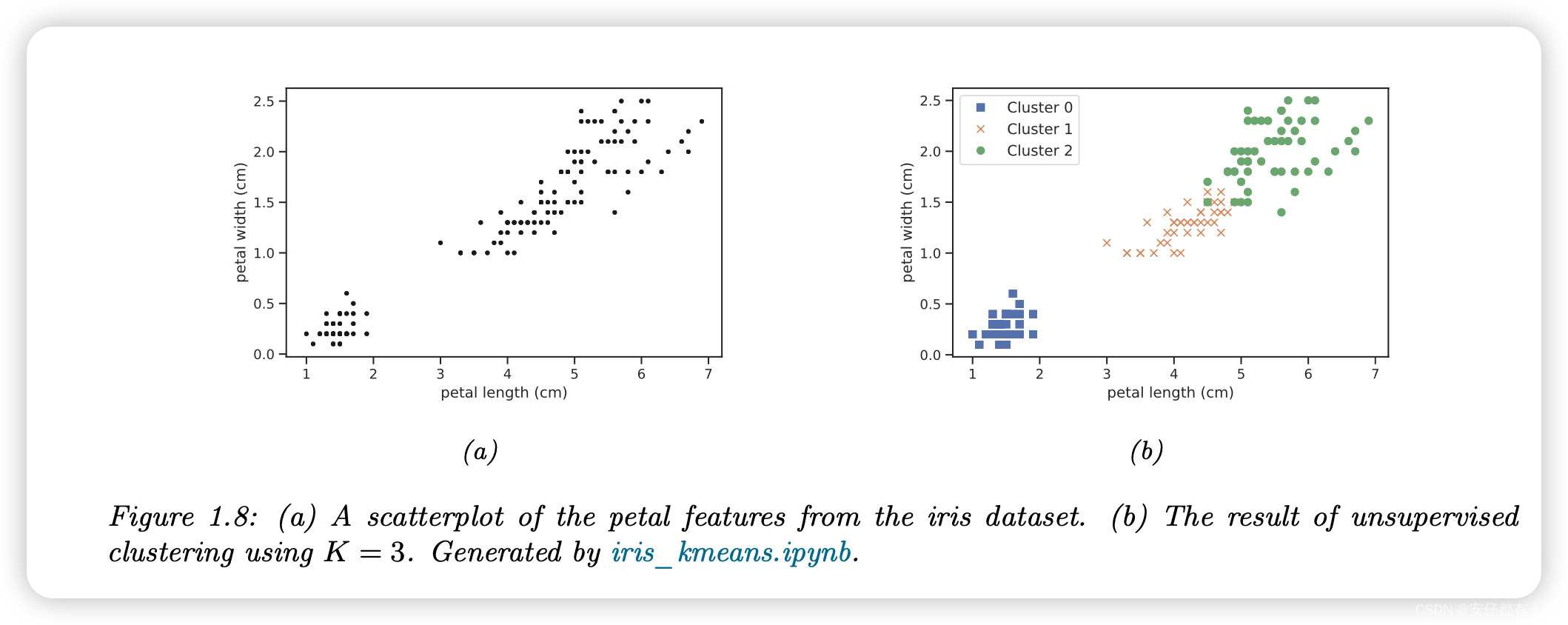
无监督学习的一个简单例子就是在数据中寻找聚类。其目标是将输入数据划分为包含 "相似 "点的区域。以 2d 版本的鸢尾花数据集为例。在图 1.8a 中,我们显示了没有任何类别标签的点。直观地说,数据中至少有两个聚类,一个在左下方,一个在右上方。此外,如果我们假设一组 "好的 "聚类应该相当紧凑,那么我们可能希望将右上方分成(至少)两个子聚类。最终划分为三个簇的结果如图 1.8b 所示。(请注意,并不存在正确的簇数;相反,我们需要考虑模型复杂性与数据拟合之间的权衡。我们将在第 21.3.7 节讨论如何进行权衡)。
1.3.2 发现潜在的“变异因素”
在处理高维数据时,通常需要将其投影到能捕捉数据 "本质 "的低维子空间,从而降低维度。解决这个问题的一种方法是假设每个观察到的高维输出是由一组隐藏的或未观察到的低维潜在因子
生成的。我们可以用下面的图表来表示该模型:
,其中箭头代表因果关系。由于我们不知道潜在因素 zn,我们通常假设 p(zn) 是一个简单的先验概率模型,如高斯模型,即每个因素都是一个随机的 K 维向量。如果数据是实值,我们也可以使用高斯似然法。
最简单的例子是当我们使用线性模型时,。由此产生的模型称为因子分析(FA)。 它与线性回归类似,只是我们只观察输出 xn,而不观察输入 zn。在
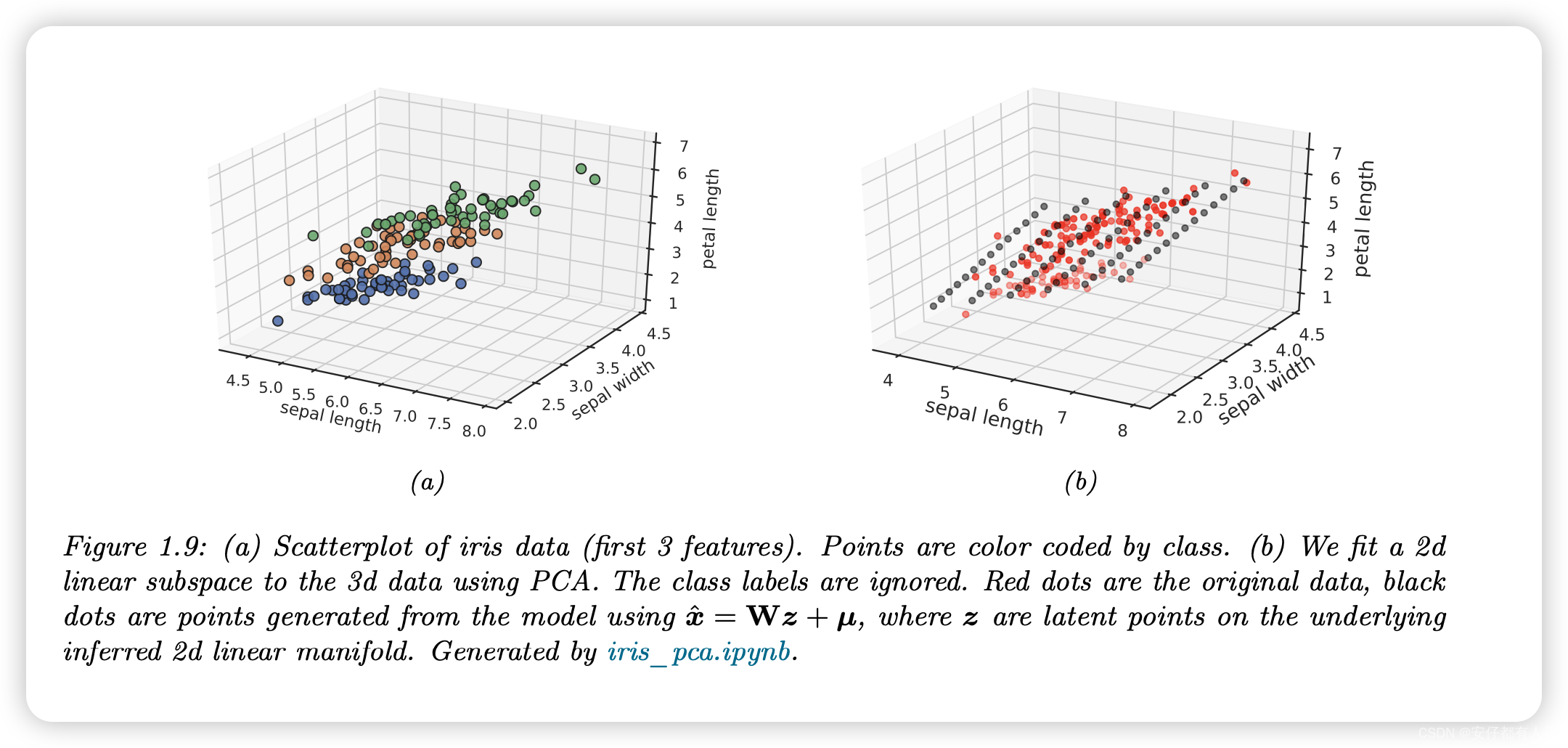
的特殊情况下,这将简化为一种称为概率主成分分析(PCA)的模型,我们将在第 20.1 节中对此进行解释。在图1.9中,我们举例说明了当应用于一些简单的三维数据时,该方法如何找到二维线性子空间。
译者对
的解释:
1. 左边表示,在
决定
的条件下(
),模型的参数为
.整个模型就表示为:
,输出是
2. 右边表示,假如是一个高斯模型,且
当然,假设从 zn 到 xn 是线性映射是非常有限制性的。但是,我们可以通过定义 来创建非线性扩展,其中 f(z;θ) 是一个非线性模型,例如深度神经网络。拟合这种模型(即估计参数 θ)变得更加困难,因为必须推断神经网络的输入以及模型的参数。不过,也有各种近似方法,例如变分自编码器(参见第 20.3.5 节)。
1.3.3 自监督学习
最近流行的一种无监督学习方法被称为自监督学习。在这种方法中,我们从未标明的数据中创建代理监督任务。例如,我们可以尝试学习:从灰度图像预测彩色图像,或屏蔽句子中的单词,然后根据周围的上下文尝试预测这些单词。我们希望由此产生的预测器(其中
是观察到的输入,
是预测到的输出)能从数据中学习到有用的特征,然后将其用于标准的下游监督任务中。这就避免了试图推断观察数据背后的 "真实潜在因素 "z 的难题。我们将在第 19.2 节详细讨论这种方法。
1.3.4 评估无监督学习
尽管无监督学习很有吸引力,但很难评估无监督学习方法的输出质量,因为没有可与[TOB16]相比的基本事实。
[TOB16]:L. Theis, A. van den Oord, and M. Bethge. “A note on the evaluation of generative models”. In: ICLR. 2016.
评估无监督模型的一种常见方法是测量模型对未知测试示例的概率。我们可以通过计算数据的(无条件的)负对数概率来做到这一点:
这种方法将无监督学习问题视为密度估计问题。其核心思想是,一个好的模型不会对实际数据样本感到“意外”(即会给予它们高概率)。此外,由于概率必须总和为1.0,如果模型给予数据空间中的某些区域高概率,它隐含地将低概率分配给其他区域。因此,模型已经学会了捕捉数据中的典型模式。这可以用于数据压缩算法中。
遗憾的是,密度估计很难,尤其是在高维情况下。此外,对数据赋予高概率的模型可能并没有学习到有用的高级模式(毕竟,模型可以只记住所有的训练示例)。
另一种评估指标是将学习到的无监督表示作为下游监督学习方法的特征或输入。如果无监督方法发现了有用的模式,那么就有可能使用这些模式进行监督学习,使用的标记数据要比使用原始特征时少得多。例如,在第 1.2.1.1 节中,我们看到鸢尾花的 4 个人工定义的特征包含了进行分类所需的大部分信息。因此,我们只需使用 150 个示例就能训练出性能近乎完美的分类器。如果输入的是原始像素,我们就需要更多的例子才能达到类似的效果(见第 14.1 节)。也就是说,我们可以通过先学习一个好的表示来提高学习的样本效率(即减少获得良好性能所需的标注示例数量)。
提高样本效率是一个有用的评估指标,但在许多应用中,尤其是在科学领域,无监督学习的目标是获得理解,而不是提高某些预测任务的性能。这就要求使用可解释的模型,但这些模型也能生成或 "解释 "数据中观察到的大部分模式。套用柏拉图的话说,我们的目标是:发现如何 "在自然的关节处雕刻"。当然,要评估我们是否成功地发现了某些数据集背后真正的底层结构,往往需要进行实验,从而与世界互动。我们将在第 1.4 节中进一步讨论这一主题。
1.4 强化学习
除了有监督和无监督学习之外,还有第三种ML,称为强化学习(RL)。在这类问题中,系统或代理必须学习如何与其环境交互。这可以通过策略a=π(x)进行编码,该策略指定对每个可能的输入x(来源于环境状态)采取的操作。
例如,考虑一个学习玩电子游戏的代理,如Atari Space Invaders(见图1.10a)。

在这种情况下,输入x是图像(或过去图像的序列),输出a是移动的方向(向左或向右)以及是否发射导弹。作为一个更复杂的例子,考虑机器人学习走路的问题(见图1.10b)。在这种情况下,输入x是所有肢体的关节位置和角度的集合,输出a是动作或马达控制信号的集合。
与监督学习(SL)的不同之处在于,系统不会被告知采取哪种行动最好(即对给定的输入产生哪种输出)。相反,系统只是偶尔收到一个奖励(或惩罚)信号,以回应它所采取的行动。这就像与批评家一起学习,批评家偶尔会竖起大拇指或摁下大拇指,而不是与老师一起学习,老师会告诉你每一步该怎么做。
最近,RL 因其广泛的适用性而越来越受欢迎(因为代理试图优化的奖励信号可以是任何感兴趣的指标)。然而,由于种种原因,RL 比监督或无监督学习更难发挥作用。一个主要的困难是,奖励信号可能只是偶尔给出(例如,是否代理最终达到了期望的状态),即便如此,代理可能也不清楚它的许多行动中哪些行动是获得奖励的原因。(想想玩国际象棋这样的游戏,游戏结束时只有一个输赢信号)。
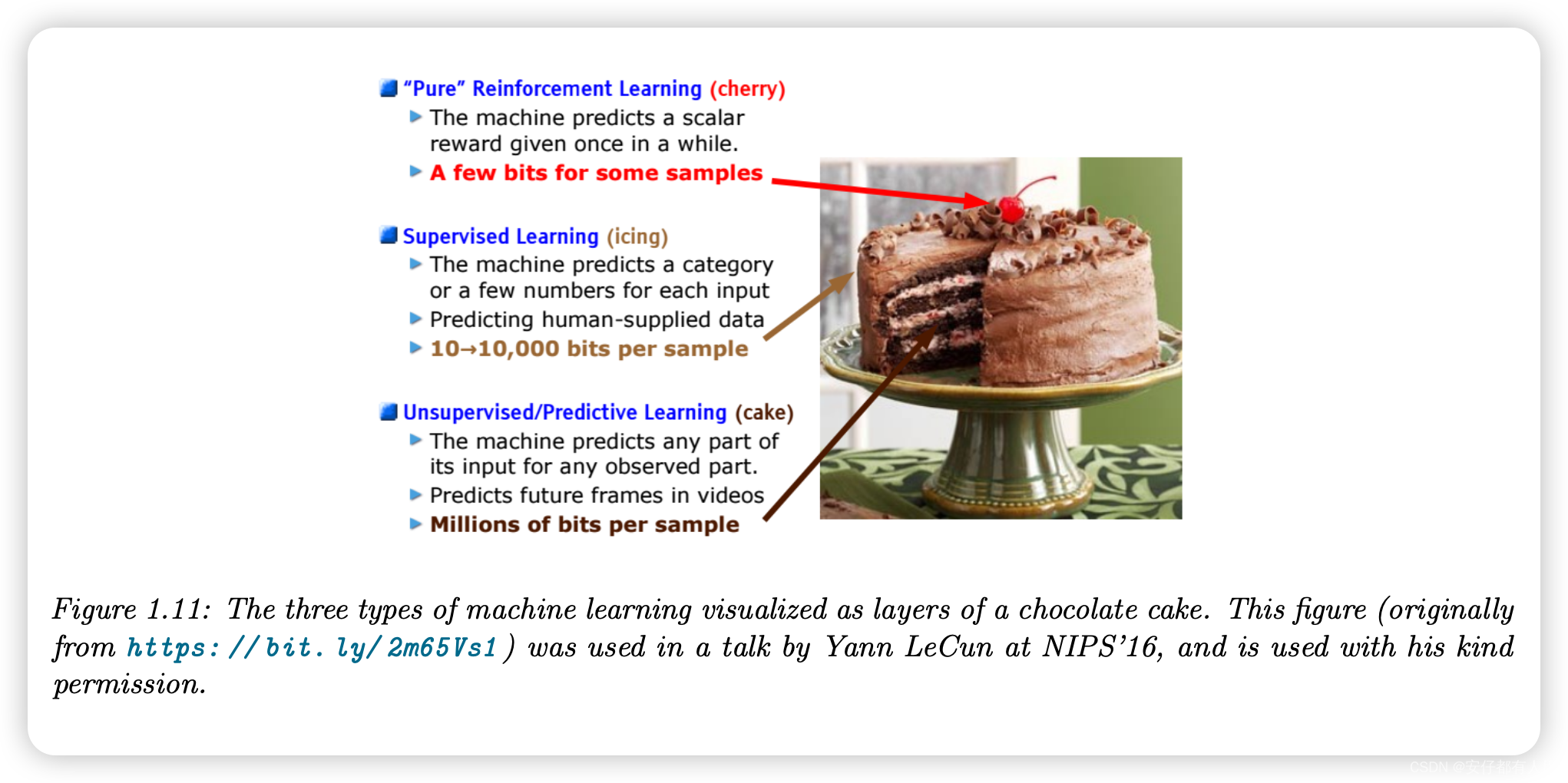
为了弥补来自奖励信号的信息量极小的缺陷,通常会使用其他信息源,如专家示范(可在监督下使用)或无标记数据(可被无监督学习系统用于发现环境的潜在结构)。这样就可以从有限的试验(与环境的交互)中学习。正如扬-勒昆(Yann LeCun)在2016年NIPS8大会的特邀演讲中所说的那样: "如果智能是一个蛋糕,那么无监督学习就是海绵巧克力,有监督学习就是糖霜,而强化学习就是樱桃"。如图 1.11 所示。
关于RL的更多信息可以在本书的续集[Mur23]中找到。
1.5 数据
机器学习涉及使用各种算法对数据模型进行拟合。虽然我们的重点是建模和算法方面,但必须提到的是,训练数据的性质和质量对任何学习模型的成功也起着至关重要的作用。
在本节中,我们将简要介绍本书使用的一些常见图像和文本数据集。我们还将简要讨论数据预处理。
1.5.1 一些常见的图像数据集
在本节中,我们将简要讨论书中使用的一些图像数据集。
1.5.1.1 小型图像数据集
最简单、使用最广泛的一种是MNIST[LeC+98;YB19]。这是一个由60k个训练图像和10k个测试图像组成的数据集,每个图像的大小为28×28(灰度),显示了10个类别的手写数字。每个像素是范围{0,1,…,255}中的一个整数;这些通常被重新缩放到[0,1],以表示像素强度。我们可以选择通过阈值处理将其转换为二进制图像。见图1.12a。
[LeC+98]:Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. “Gradient-Based Learning Applied to Document Recognition”. In: Proceedings of the IEEE 86.11 (1998),pp. 2278-2234.
[YB19]:C. Yadav and L. Bottou. “Cold Case: The Lost MNIST Digits”. In: arXiv (2019).
注意:术语“MNIST”代表“修改后的国家标准协会(Modified National Institute of Standards)”;之所以使用“修改”一词,是因为图像经过了预处理,以确保数字大部分位于图像的中心。
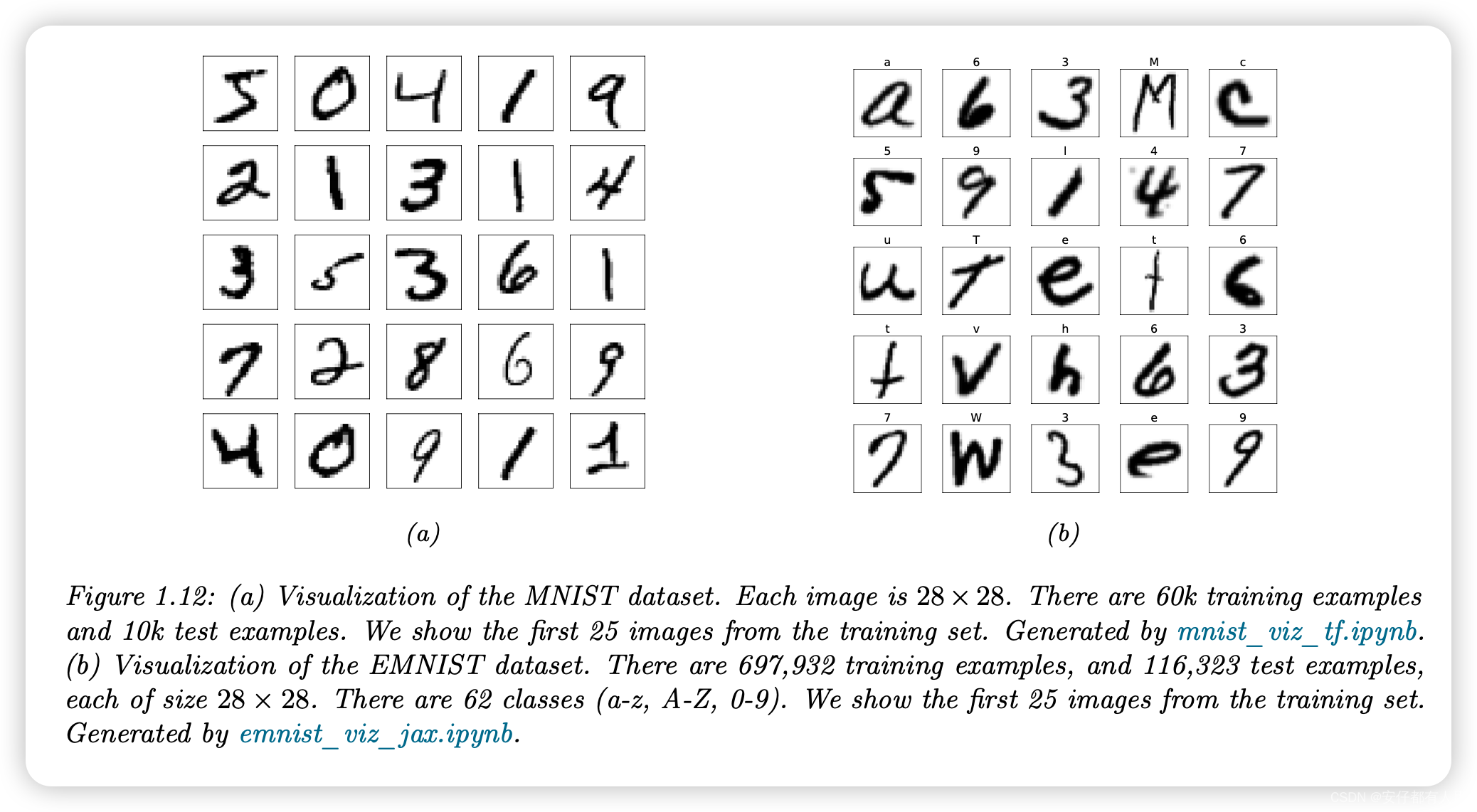
MNIST在ML社区中的应用如此广泛,以至于著名的ML研究人员Geoff Hinton称其为“机器学习的果蝇”,因为如果我们不能使一种方法在MNIST上很好地工作,那么它很可能在更难的数据集上也不好地工作。然而,如今MNIST分类被认为“太容易了”,因为只看一个像素就可以区分大多数数字对。因此各种各样的变体已经被提出。
在[Coh+17]中,他们提出了EMNIST(扩展MNIST),它也包括小写和大写字母。可视化见图1.12b。该数据集比MNIST要困难得多,因为有62个类,其中几个类非常模糊(例如,数字1与小写字母l)。
[Coh+17]:G. Cohen, S. Afshar, J. Tapson, and A. van Schaik. “EMNIST: an extension of MNIST to handwritten letters”. In: (2017). arXiv: 1702. 05373 [cs.CV].
在[XRV17]中,他们提出了Fashion MNIST,它的尺寸和形状与MNIST完全相同,但每个图像都是一件衣服的图片,而不是手写数字。可视化见图1.13a。
[XRV17]:H. Xiao, K. Rasul, and R. Vollgraf. “Fashion- MNIST: a Novel Image Dataset for Bench- marking Machine Learning Algorithms”. In: (2017). arXiv: 1708.07747 [stat.ML].

对于小彩色图像,最常见的数据集是CIFAR[KH09]。这是一个由60k张图像组成的数据集,每张图像的大小为32×32×3,代表10或100个类别的日常对象;见图1.13b。11
[KH09]:A Krizhevsky and G Hinton. Learning multi- ple layers of features from tiny images. Tech. rep. U. Toronto, 2009.
1.5.1.2 ImageNet
小型数据集对原型设计很有用,但在较大的数据集上测试也很重要,无论是在图像大小还是标记示例的数量方面。这种类型使用最广泛的数据集称为ImageNet[Ras+15]。这是一个大小为256×256×3的~14M图像数据集,展示了20000个类别的各种对象;一些示例见图1.14a。
[Ras+15]:O. Russakovsky et al. “ImageNet Large Scale Visual Recognition Challenge”. In: Intl. J. Computer Vision (2015), pp. 1–42.
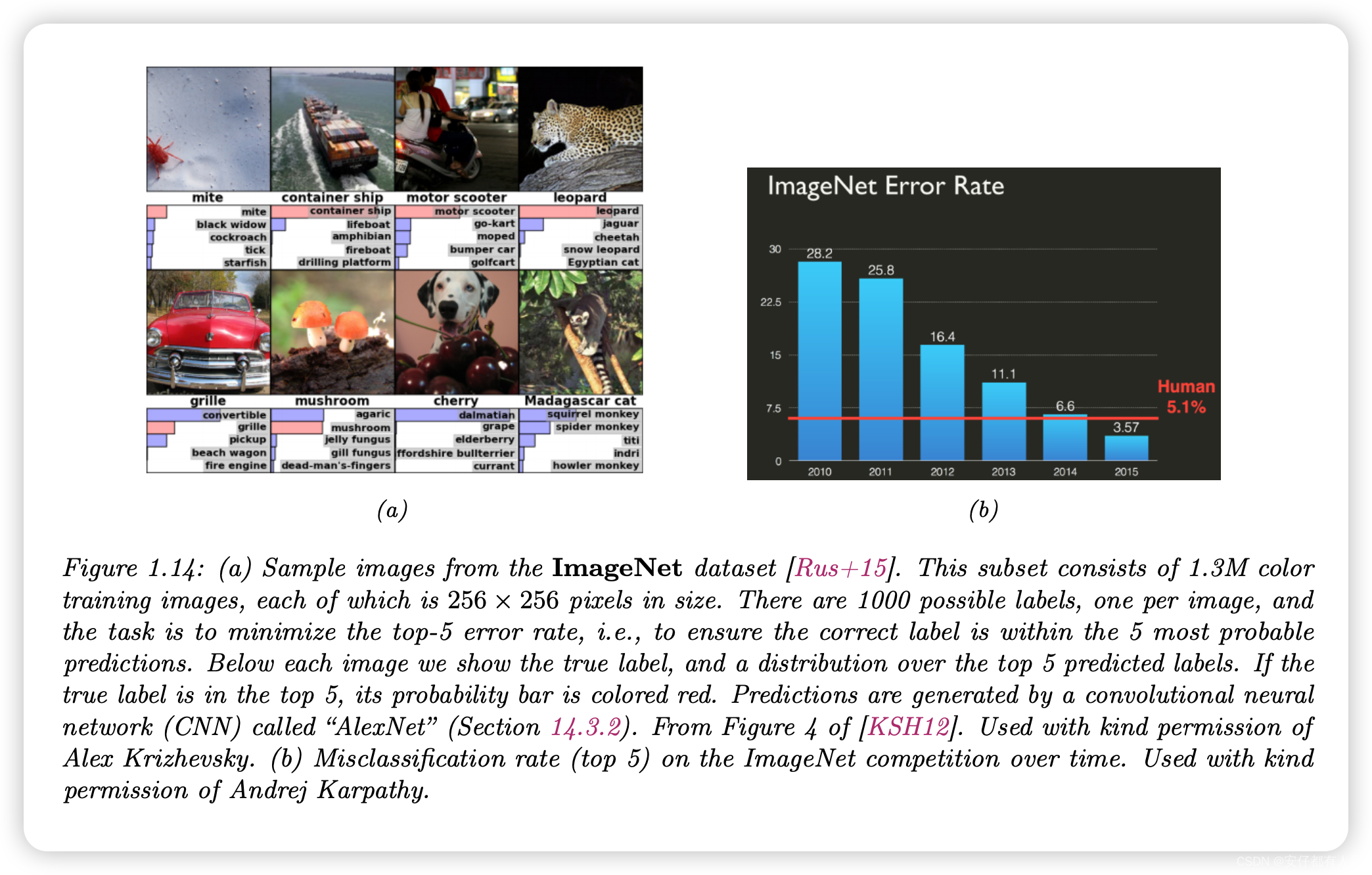
ImageNet数据集被用作ImageNet大规模视觉识别挑战赛(ILSVRC)的基础,该挑战赛从2010年持续到2018年。它使用了来自 1000 个类别的 130 万张图像子集。如图 1.14b 所示,在比赛过程中,社区取得了重大进展。其中,2015 年是 CNN 在 ImageNet 图像分类任务中首次超过人类(或至少超过一名人类,即 Andrej Karpathy)。请注意,这并不意味着 CNN 的视觉能力优于人类(关于一些常见的失败模式,请参见 [YL21])。相反,这很可能反映了这样一个事实,即数据集做出了许多人类难以理解的细粒度区分--例如 "老虎 "和 "虎猫 "之间的区分。- 相比之下,足够灵活的 CNN 可以学习任意模式,包括随机标签 [Zha+17a]。
[YL21]:A. L. Yuille and C. Liu. “Deep Nets: What have they ever done for Vision?” In: Intl. J. Computer Vision 129 (2021), pp. 781–802.
[Zha+17a]:C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. “Understanding deep learn- ing requires rethinking generalization”. In: ICLR. 2017.
尽管作为分类基准,ImageNet 比 MNIST 和 CIFAR 难得多,但它也几乎 "饱和" [Bey+20]。不过,在ImageNet上表现好的模型,在其他分类任务中也表现良好(参见 [Rec+19]),因此它仍被广泛使用。
[Bey+20]:L. Beyer, O. J. Hénaff, A. Kolesnikov, X. Zhai, and A. van den Oord. “Are we done with ImageNet?” In: (2020). arXiv: 2006 . 07159 [cs.CV].
[Rec+19]:B. Recht, R. Roelofs, L. Schmidt, and V. Shankar. “Do Image Net Classifiers Generalize to Image Net?" In:ICML. 2019.
1.5.2 一些常见的文本数据集
机器学习通常应用于文本来解决各种任务。这被称为自然语言处理或NLP(例如,参见[JM20]了解详细信息)。下面简要介绍一下在本书中使用的一些文本数据集。
[JM20]:D. Jurafsky and J. H. Martin. Speech and lan- guage processing: An Introduction to Nat- ural Language Processing, Computational Linguistics, and Speech Recognition (Third Edition). Draft of 3rd edition. 2020.
1.5.2.1 文本分类
一个简单的NLP任务是文本分类,可用于电子邮件垃圾邮件分类、情感分析(例如,电影或产品评论是正面的还是负面的)等。评估此类方法的常见数据集是[Ma+11]的IMDB电影评论数据集。(IMDB代表“互联网电影数据库”。)其中包含25k个标记示例用于训练,25k个用于测试。每个示例都有一个二进制标签,表示正面或负面评级。一些例句见表1.3。

1.5.2.2 机器翻译
一个更困难的NLP任务是:将一种语言中的句子x映射到另一种语言的“语义等效”句子y;这叫做机器翻译。训练这样的模型需要对齐的(x,y)。幸运的是,有几个这样的数据集,例如来自加拿大议会(English-French pairs)和欧盟(Europarl)。后者的一个子集被称为WMT数据集(Workshop on Machine Translation),由英语-德语对组成,并被广泛用作基准数据集。
1.5.2.3 其他 seq2seq 任务
机器翻译的一个通用方法是:学习从一个序列 x 到任何其他序列 y 的映射。这被称为 seq2seq 模型,可视为一种高维分类形式(详见第 15.2.3 节)。这种框架非常普遍,包括许多任务,如文档摘要、问题解答等。例如,表 1.4 展示了如何将问题解答表述为一个 seq2seq 问题。输入是文本 T 和问题 Q,输出是答案 A,它是一组单词,可能是从输入中提取出来的

1.5.2.4 语言建模
"语言建模 "这个相当宏大的术语指的是创建文本序列无条件生成模型 p(x1, ... , xT ) 。这只需要输入句子 x,而不需要任何相应的 "标签 "y。因此,我们可以将其视为无监督学习的一种形式,我们在第 1.3 节中对此讨论过。如果语言模型像 seq2seq 中那样根据输入生成输出,我们可以将其视为条件生成模型。
1.5.3 对离散输入数据进行预处理
许多ML模型假设数据由实值特征向量组成。然而,有时输入可能具有离散的输入特征,如种族和性别等分类变量,或某些词汇中的单词。在下面的部分中,我们将讨论一些预处理此类数据以将其转换为矢量形式的方法。这是一种常见的操作,用于许多不同类型的模型。
1.5.3.1 One-hot编码(独热编码)
当我们有分类特征时,我们需要将它们转换为数字尺度,这样计算输入的加权组合才有意义。预处理此类分类变量的标准方法是使用one-hot编码,也称为伪编码。如果变量x有K个值,我们将如下表示其伪编码:。例如,如果有3种颜色(比如红色、绿色和蓝色),则对应的one-hot矢量将是one-hot(红色)=[1,0,0],one-hot(绿色)=[0,1,0],和one-hot(蓝色)=[0,0,1]。
1.5.3.2 特征交叉
使用针对每个分类变量的伪编码的线性模型可以捕捉每个变量的主要效应,但不能捕捉它们之间的相互效应。例如,假设我们想要根据两个分类输入变量来预测车辆的燃油效率:类型(例如SUV(SUV)、卡车(Truck)或家庭轿车(Family car))和原产国(例如美国(USA)或日本(Japan))。如果我们将三元和二元特征的独热编码连接起来,我们得到以下输入编码:
其中x1是类型,x2是原产国。
此模型无法捕获特征之间的依赖关系。例如,我们预计卡车的燃油效率会更低,但也许美国的卡车甚至不如日本的卡车。使用方程(1.34)中的线性模型无法捕捉到这一点,因为来源国的贡献与汽车类型无关。
我们可以通过计算特征交叉来解决这个问题。例如,我们可以定义一个新的复合特征,其可能值为 3 × 2,以捕捉类型和原产国的相互影响。新模型变为:
我们可以看到,使用特征交叉将原始数据集转换为更宽的格式,包含更多的列。
1.5.4 预处理文本数据
在第 1.5.2 节中,我们简要讨论了文本分类和其他 NLP 任务。要将文本数据输入分类器,我们需要解决各种问题。首先,文档具有可变长度,因此并不是固定长度的特征向量,这与许多模型的假设不符。其次,单词是具有许多可能值的变量(等于词汇表的大小),因此相应的独热编码将是非常高维的,没有自然的相似性概念。第三,我们在测试时可能会遇到在训练过程中没有出现过的单词(即所谓的 "词汇表外单词 "或 "OOV 单词")。下面我们将讨论解决这些问题的一些方法。更多详情可参见 [BKL10; MRS08; JM20] 等文献。
[BKL10]:S. Bird, E. Klein, and E. Loper. Natural Language Processing with Python: Analyz- ing Text with the Natural Language Toolkit.2010.
[MRS08]:C. Manning, P. Raghavan, and H. Schuetze. Introduction to Information Retrieval. Cam- bridge University Press, 2008.
[JM20]:D. Jurafsky and J. H. Martin. Speech and lan- guage processing: An Introduction to Nat- ural Language Processing, Computational Linguistics, and Speech Recognition (Third Edition). Draft of 3rd edition. 2020.
1.5.4.1 词袋模型
词袋模型是一种在自然语言处理中常用的简单文本表示方法。在词袋模型中,文本被视为词汇的无序集合,忽略其语法和语序。具体来说,词袋模型将文本表示为一个由单词构成的向量,其中每个维度对应于一个词汇表中的单词,而向量的值表示该单词在文本中的出现次数或其他统计信息。因此,词袋模型不考虑单词的顺序或上下文,只关注单词的出现情况。
为了减少词数量,我们经常使用各种预处理技术,例如:去掉标点符号,将所有单词转换为小写字母;去掉常见但信息量不大的单词,如 "and "和 "the"(这称为停止词去除);将单词替换为其基本形式,如将 "running "和 "runs "替换为 "run"(这称为词干化)等。详见 [BL12],示例代码见 text_preproc_jax.ipynb。链接
[BL12]:J. A. Bullinaria and J. P. Levy. “Extract- ing semantic representations from word co- occurrence statistics: stop-lists, stemming, and SVD”. en. In: Behav. Res. Methods 44.3 (2012), pp. 890–907.
让 表示第 n 个文档中位于 t 位置的token。如果词汇表中有 D 个不同的token,那么我们可以用一个 D 维向量
来表示第 n 个文档,其中
是单词 v 在文档 n 中出现的次数:
其中T是文档n的长度。我们现在可以将文档解释为中的向量。这被称为文本的向量空间模型[SWY75;TP10]。
[SWY75]:G Salton, A Wong, and C. S. Yang. “A vec- tor space model for automatic indexing”. In: Commun. ACM 18.11 (1975), pp. 613–620.
[TP10]:P. D. Turney and P. Pantel. “From Frequency to Meaning: Vector Space Models of Seman- tics”. In: JAIR 37 (2010), pp. 141–188.
通常,我们将输入数据存储在由X表示的N×D设计矩阵中,其中D是特征的数量。在向量空间模型的背景下,更常见的是将输入数据表示为D×N项频率矩阵,其中是文档j中项i的频率。见图1.15。

1.5.4.2 TF-IDF
将文档表示为词频向量的一个问题是,频繁使用的词可能会产生不当的影响,仅仅是因为它们的词频更高,即使它们并不携带太多语义内容。对此,常见的解决方法是通过取对数来转换计数,这样可以减少在单个文档中多次出现的词的影响。
为了减少在整个文档集中频繁出现的词的影响,我们计算了一个称为逆文档频率的量,其定义如下:,其中
是含有词i的文档数量。我们可以将这些转换组合起来计算TF-IDF矩阵,如下所示:
(我们也经常规范化每一行。)这提供了更有意义的文档表示,并且可以用作许多ML算法的输入。有关示例,请参见tfidf_demo.ipynb。链接
译者解释:
逆文档频率的解释如下:
如果一个术语在所有文档中都出现,即
等于 N,则其逆文档频率为 log(1)=0log(1)=0,表示这个术语在整个文档集中没有区分性,对文档的贡献较小。
如果一个术语只在很少的文档中出现,
然后将其作为权重,与词频向量相乘。上面例子中即
,这是对词频向量做了一定平滑处理。
1.5.4.3 词嵌入
尽管 TF-IDF 变换通过增加 "信息量大 "的词的权重,减少 "信息量小 "的词的权重,改进了原始词频向量,但它并没有解决one-hot编码的根本问题,即:语义相似的词,如 "男人 "和 "女人",可能并不比语义不同的词,如 "男人 "和 "香蕉 "更接近(在向量空间中)。因此,大多数预测模型暗含的假设:输入空间中相近的点应该有相似的输出,是无效的。
解决这一问题的标准方法是使用词嵌入,即使用将每个稀疏的one-hot向量
映射到一个低维的稠密向量
,其中
的学习方式是将语义相似的单词放在相近的位置。我们将在第20.5节中讨论,有很多方法可以学习这种嵌入。
有了嵌入矩阵后,我们就可以将长度可变的文本文档表示为一袋词嵌入。然后,我们可以通过求和(或求平均值)嵌入将其转换为固定长度的向量:
其中,是来自等式(1.37)的词袋表示。然后,我们可以在逻辑回归分类器中使用它,我们在第1.2.1.5节中简要介绍了这一点。整体模型具有以下形式:
我们通常使用预先训练好的词嵌入矩阵 E,在这种情况下,模型在 W 中是线性的,从而简化了参数估计(见第 10 章)。关于上下文词嵌入的讨论,另请参见第 15.7 节。
1.5.4.4 对新词的处理
在测试时,模型可能会遇到一个前所未见的单词。这被称为“词汇表外单词”或OOV问题。这样的新词必然会出现,因为这组词是一个开放的类。例如,专有名词(人名和地名)的集合是无界的。
解决这个问题的标准启发式方法是用代表“未知”的特殊符号UNK替换所有新词。然而,这会丢失信息。例如,如果我们遇到“athazagoraophobia”这个词,我们可能会猜测它的意思是“对某事的恐惧”,因为phobia是英语中一个常见的后缀(源自希腊语),意思是“害怕”。(事实证明,athazagoraophobia的意思是“害怕被遗忘或忽视”。)
我们可以在字符层面开展工作,但这需要模型学习如何将常见的字母组合成单词。更好的办法是利用单词具有子结构这一事实,然后将子单词单位或单词片段作为输入[SHB16; Wu+16];这些单词片段通常使用一种称为字节对编码[Gag94]的方法创建,这是一种数据压缩形式,它创建了新的符号来表示常见的子串。
[SHB16]:R. Sennrich, B. Haddow, and A. Birch. “Neu- ral Machine Translation of Rare Words with Subword Units”. In: Proc. ACL. 2016.
[Wu+16]:Y. Wu et al. “Google’s Neural Machine Trans- lation System: Bridging the Gap between Hu- man and Machine Translation”. In: (2016). arXiv: 1609.08144 [cs.CL].
[Gag94]:P. Gage. “A New Algorithm for Data Com- pression”. In: Dr Dobbs Journal (1994).
1.5.5 处理缺失数据
有时我们可能会丢失数据,其中输入x或输出y的一部分可能是未知的。如果在训练过程中输出未知,则示例未标记;我们将在第19.3节中考虑这种半监督学习场景。因此,我们将重点放在一些输入特征可能缺失的情况下,无论是在训练或测试时,还是两者兼而有之。
为了建立这个模型,让 M 成为一个 N × D 的二进制变量矩阵,其中,如果实例 n 中的特征 d 丢失,则 ,否则
。
是输入特征矩阵的可见部分,对应
;
是缺失部分,对应
。让
成为输出标签矩阵,我们假设它是完全可观测的。如果我们假设
,我们就说数据是完全随机缺失或 MCAR,因为缺失不依赖于隐藏特征或观测特征。如果我们假设
,我们就说数据是随机缺失或 MAR,因为缺失率不取决于隐藏特征,但可能取决于可见特征。如果这两个假设都不成立,我们就说数据不是随机缺失或 NMAR。
译者解释:
完全随机缺失:指不依赖任何部分的缺失。即缺失矩阵M的出现不依赖任何输入输出。
随机缺失:指数据的缺失是随机的,但是它和观测的数据有关,比如
.但是和没有观察的数据无关,如
不随机缺失:指数据的缺失是因为某些具体的缺失导致的,如
。
在 MCAR 和 MAR 模型中,我们可以忽略缺失机制,因为它不会告诉我们任何关于隐藏特征的信息。但是,在 NMAR 情况下,我们需要对缺失数据机制进行建模,因为缺失信息可能是有价值的。例如,某人没有填写调查表中敏感问题的答案(如 "您是否有 COVID?有关缺失数据模型的更多信息,请参阅 [LR87; Mar08] 等。
[LR87]:R. J. Little and D. B. Rubin. Statistical Anal- ysis with Missing Data. Wiley and Son, 1987.
[Mar08]:B. Marlin. “Missing Data Problems in Ma- chine Learning”. PhD thesis. U. Toronto, 2008.
在这本书中,我们将始终进行MAR假设。然而,即使有了这个假设,当我们缺少输入特征时,我们也不能直接使用判别模型,例如DNN,因为输入x将具有一些未知值。
一种常见的启发式方法叫做均值估算,即用经验均值替换缺失值。更一般地说,我们可以对输入数据拟合一个生成模型,然后用它来填补缺失值。我们将在第 20 章简要讨论一些适用于这一任务的生成模型,并在本书的续篇[Mur23]中进行更详细的讨论。
[Mur23]:K. P. Murphy. Probabilistic Machine Learning: Advanced Topics. MIT Press, 2023.
1.6 讨论
在本节中,我们将ML和本书置于一个更大的背景中。
1.6.1 ML与其他领域的关系
有几个子社区致力于研究与 ML 相关的主题,每个社区都有不同的名称。预测分析领域类似于监督学习(特别是分类和回归),但更多地关注商业应用。数据挖掘涵盖了有监督和无监督的机器学习,但更多地关注结构化数据,通常存储在大型商业数据库中。数据科学利用机器学习和统计学的技术,但也强调其他主题,如数据集成、数据可视化以及与领域专家合作,通常在迭代反馈循环中进行(参见例如,[BS17])。这些领域之间的区别通常只是术语上的不同。
[BS17]:D. M. Blei and P. Smyth. “Science and data science”. en. In: Proc. Natl. Acad. Sci. U. S. A. (2017).
ML也与统计学领域密切相关。事实上,斯坦福大学著名统计学教授Jerry Friedman说:
[如果统计领域]从一开始就将计算方法作为一种基本工具,而不仅仅是将其视为应用现有工具的一种方便方式,那么许多其他与数据相关的领域(如机器学习)就不需要存在——它们本应是统计学的一部分。——Jerry Friedman[Fri97b]
[Fri97b]:J. H. Friedman. “Data mining and statis- tics: What’s the connection”. In: Proceed-
ings of the 29th Symposium on the Inter- face Between Computer Science and Statis- tics. 1997.
1.6.2 本书结构
我们已经看到,ML与数学、统计学、计算机科学等许多其他学科密切相关。很难知道从哪里开始比较合适。
在这本书中,我们使用概率论作为我们的统一视角,在这个相互关联的视角下走一条特定的路线。我们在第一部分中涵盖了统计基础,在第二部分-第四部分中涵盖监督学习,在第五部分中涵盖无监督学习。有关这些(和其他)主题的更多信息,请参阅本书的续集[Mur23]
[Mur23]:K. P. Murphy. Probabilistic Machine Learning: Advanced Topics. MIT Press, 2023.
除了这本书,你可能会发现这本书附带的在线Python Botebook很有帮助。有关详细信息,请参阅probml.github.io/book1。链接
1.6.3 注意事项
在这本书中,我们将看到如何使用机器学习来创建能够(尝试)预测给定输入的系统。然后可以使用这些预测来选择行动,从而最大限度地减少预期损失。在设计这样的系统时,很难设计一个能正确指定所有偏好的损失函数;这可能导致“奖励欺骗”,即机器优化我们给定的奖励函数,但随后我们意识到该函数未捕捉到我们忘记指定的各种约束或偏好 [Wei76; Amo+16; D’A+20]。(当需要在多个目标之间进行权衡时,这一点尤为重要。)
[Wei76]:J. Weizenbaum. Computer Power and Hu- man Reason: From Judgment to Calculation. en. 1st ed. W H Freeman & Co, 1976.
[Amo+16]:D. Amodei, C. Olah, J. Steinhardt, P. Chris- tiano, J. Schulman, and D. Mané. “Concrete Problems in AI Safety”. In: (2016). arXiv: 1606.06565 [cs.AI].
[D'A+20]:A. D’Amour et al. “ Underspecification Presents Challenges for Credibility in Modern Machine Learning”. In: (2020). arXiv: 2011. 03395 [cs.LG].
奖励欺骗是一个更大问题的示例,被称为“对齐问题”[Chr20],它指的是我们要求算法优化的内容与我们实际希望优化的内容之间可能存在的差异;这在人工智能伦理和人工智能安全的背景下引发了各种关注(参见,[KR19; Lia20; Spe+22])。Russell [Rus19] 提出通过不明确指定奖励函数来解决这个问题,而是通过观察人类行为来迫使机器推断奖励,这一方法被称为逆强化学习。然而,过于密切模仿当前或过去的人类行为可能是不可取的,并且可能受到用于训练的数据的影响(参见,[Pau+20])。
[Chr20]:B. Christian. The Alignment Problem: Ma- chine Learning and Human Values. en. 1st ed. W. W. Norton & Company, 2020.
[KR19]:M. Kearns and A. Roth. The Ethical Algo- rithm: The Science of Socially Aware Algo- rithm Design. en. Oxford University Press, 2019.
[Lia20]:S. M. Liao, ed. Ethics of Artificial Intelli- gence. en. 1st ed. Oxford University Press, 2020.
[Spe+22]:A. Z. Spector, P. Norvig, C. Wiggins, and J. M. Wing. Data Science in Context: Foundations, Challenges, Opportunities. en. New edition. Cambridge University Press, Oct. 2022.
[Rus19]:S. Russell. Human Compatible: Artificial In- telligence and the Problem of Control. en. Kindle. Viking, 2019.
[Pau+20]:A. Paullada, I. D. Raji, E. M. Bender, E. Denton, and A. Hanna. “Data and its (dis)contents: A survey of dataset develop-ment and use in machine learning research”. In: NeurIPS 2020 Workshop: ML Retrospec- tives, Surveys & Meta-analyses (ML-RSA). 2020.
上述人工智能观点认为,"智能 "系统会在没有人类参与的情况下自行做出决策,许多人认为这是通往 "通用人工智能"(AGI)的道路。另一种方法是将人工智能视为 "增强智能"(有时称为智能增强或 IA)。在这一范式中,人工智能是一种创造 "智能工具 "的过程,如自适应巡航控制或搜索引擎中的自动完成;这些工具在决策环中保留了人类。在这种框架下,包含人工智能/人工智能组件的系统与其他复杂的、半自主的人工制品并无太大区别,例如带有自动驾驶仪的飞机、在线交易平台或医疗诊断系统(参见 [Jor19; Ace])。当然,随着人工智能工具变得越来越强大,它们最终可以独立完成越来越多的工作,从而使这种方法与 AGI 相似。不过,在增强智能中,我们的目标不是模仿或超越人类在某些任务中的行为,而是帮助人类更轻松地完成任务;这也是我们对待大多数其他技术的方式[Kap16]。
[Jor19]:M. Jordan. “ Artificial Intelligence — The Revolution Hasn’t Happened Yet”. In: Har- vard Data Science Review 1.1 (2019).
[Ace]:“The Turing Test is Bad for Business”. In: (2021).
[Kap16]:J. Kaplan. Artificial Intelligence: What Ev- eryone Needs to Know. en. 1st ed. Oxford University Press, 2016.
本章完。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









