







目录
一、遗传算法是什么
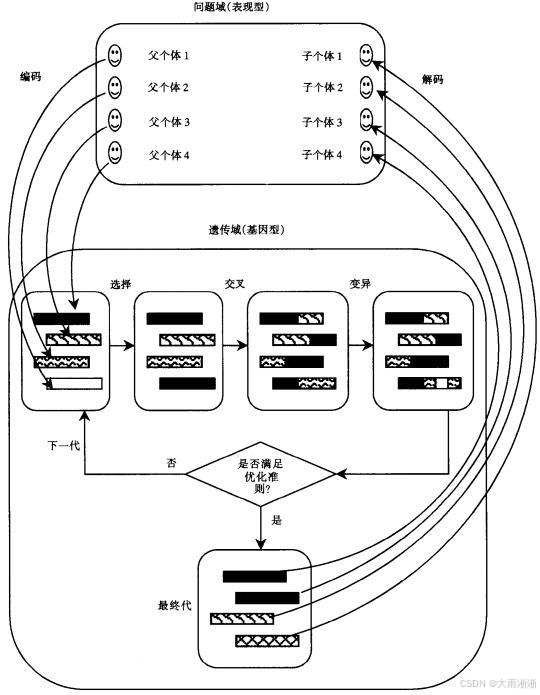
遗传算法(Genetic Algorithm,GA)是一种受自然进化启发的优化算法 ,由美国的 John holland 于 20 世纪 70 年代提出。它模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程,是一种通过模拟自然进化过程搜索最优解的方法。该算法将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程,通过数学方式和计算机仿真运算,在求解较为复杂的组合优化问题时,相对一些常规的优化算法,通常能够较快地获得较好的优化结果。目前,遗传算法已被广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。
为了更好地理解遗传算法,我们可以将其与生物进化过程进行类比。在自然界中,生物通过遗传将自身的基因传递给后代,同时基因会发生变异,产生新的特征。在生存竞争中,适应环境的生物能够生存下来并繁衍后代,不适应环境的生物则逐渐被淘汰。经过漫长的进化,生物种群逐渐适应环境,向着更优的方向发展。
遗传算法正是基于这样的思想,将问题的解看作生物个体,通过模拟遗传、变异和选择等操作,在解空间中搜索最优解。在遗传算法中,每个解被编码成一个染色体,染色体上的基因代表解的各个参数。通过适应度函数评估每个染色体的优劣,适应度高的染色体有更大的概率被选择进行遗传操作,从而产生更优的后代。经过多代的进化,算法逐渐收敛到最优解或近似最优解。
二、遗传算法为何强大
(一)传统方法的困境
在优化问题的求解中,传统方法常常面临诸多挑战。以梯度下降法为例,这是一种常用的传统优化算法,它通过计算目标函数的梯度,沿着梯度的反方向逐步更新解,以达到最小化目标函数的目的 。在处理简单的凸函数优化时,梯度下降法能够快速收敛到全局最优解。例如,对于函数\(f(x) = x^2\),其梯度为\(f'(x) = 2x\),从任意初始点出发,梯度下降法都能顺利地找到最小值点\(x = 0\)。
然而,当面对复杂的非凸函数时,梯度下降法就容易陷入局部最优解。例如,在函数\(f(x) = \sin(x)/x + (x - 2)^2\)的优化中,该函数存在多个局部最小值点。梯度下降法在迭代过程中,一旦进入某个局部最优解的吸引域,就会停止搜索,无法找到全局最优解 。
再比如,在旅行商问题(TSP)中,传统的枚举法需要计算所有可能的路径组合,随着城市数量的增加,计算量呈指数级增长。当城市数量为 10 时,可能的路径组合就有\(9! = 362880\)种,这对于计算机的计算能力和时间成本都是巨大的挑战。
(二)遗传算法的优势
遗传算法具有许多独特的优势,使其在复杂问题的求解中表现出色。遗传算法具有强大的全局搜索能力,它从多个初始解(种群)出发,通过选择、交叉和变异等操作,在解空间中进行广泛的搜索,能够有效避免陷入局部最优解 。
遗传算法对于复杂问题的适应性强,无论是函数优化、组合优化还是机器学习中的参数优化等问题,都能通过合理的编码和适应度函数设计来求解。例如,在背包问题中,遗传算法可以通过将物品的选择情况编码为染色体,以背包的总价值作为适应度函数,来寻找最优的物品组合 。
遗传算法还具有天然的并行性。其操作可以并行执行,这意味着在多核处理器的环境下,能够充分利用处理器资源,加速搜索过程。比如在大规模的函数优化问题中,可以将种群中的不同个体分配到不同的处理器核心上进行适应度评估和遗传操作,大大提高了算法的效率 。
为了更直观地感受遗传算法的优势,我们将其与传统的爬山算法在求解复杂函数\(f(x) = 10\sin(5x) + 7\cos(4x)\)(\(x \in [0, 10]\))的最大值问题上进行对比。爬山算法从一个初始解开始,每次只考虑当前解的邻域,选择邻域中最优的解作为下一个解,直到找不到更好的解为止。这种方法很容易陷入局部最优解。而遗传算法从一组随机生成的初始解出发,通过不断地进化,能够在更广泛的解空间中搜索,最终找到更接近全局最优解的值 。从实验结果来看,在多次运行中,爬山算法常常陷入局部最优,找到的最大值平均为 15 左右,而遗传算法找到的最大值平均能达到 17 以上,明显优于爬山算法 。
三、用 Python 实现遗传算法
(一)准备工作
在使用 Python 实现遗传算法之前,我们需要安装一些必要的库。其中,NumPy 是一个非常重要的库,它提供了高效的多维数组操作和数学函数,能够大大简化遗传算法中的矩阵运算和数值计算。例如,在初始化种群时,我们可以使用 NumPy 的random模块来快速生成随机数数组,作为初始种群的个体 。可以使用以下命令安装 NumPy:
pip install numpy
(二)关键步骤
初始化种群:初始化种群是遗传算法的第一步,我们需要随机生成一组初始解,构成初始种群。每个初始解就是种群中的一个个体,个体的编码方式根据问题的不同而有所差异,常见的有二进制编码、实数编码等 。以二进制编码为例,下面是使用 Python 生成初始种群的代码:
import numpy as np
def generate_population(population_size, chromosome_length):
"""
生成初始种群
:param population_size: 种群大小
:param chromosome_length: 染色体长度
:return: 初始种群
"""
return np.random.randint(2, size=(population_size, chromosome_length))
# 示例:生成10个个体,每个个体的染色体长度为5
population = generate_population(10, 5)
print("初始种群:\n", population)适应度评估:适应度函数用于评估每个个体的优劣,它是遗传算法中选择操作的依据。适应度函数的设计需要根据具体问题来确定,其值越大(或越小,根据问题是最大化还是最小化而定),表示个体越优 。例如,我们要最大化函数\(f(x) = x^2\),其中\(x\)是一个二进制编码的整数,下面是计算适应度的 Python 代码:
def fitness_function(chromosome):
"""
计算适应度
:param chromosome: 染色体
:return: 适应度值
"""
x = int(''.join(map(str, chromosome)), 2)
return x ** 2
# 计算种群中每个个体的适应度
fitness_values = [fitness_function(individual) for individual in population]
print("适应度值:", fitness_values)选择操作:选择操作是根据个体的适应度,从当前种群中选择出一些个体,作为下一代种群的父代。常见的选择方法有轮盘赌选择、锦标赛选择等 。轮盘赌选择的基本思想是,个体被选中的概率与其适应度成正比,适应度越高的个体被选中的概率越大。以下是轮盘赌选择的 Python 代码实现:
def roulette_wheel_selection(population, fitness_values):
"""
轮盘赌选择
:param population: 种群
:param fitness_values: 适应度值列表
:return: 选择后的种群
"""
total_fitness = sum(fitness_values)
selection_probabilities = [fitness / total_fitness for fitness in fitness_values]
selected_indices = np.random.choice(len(population), size=len(population), p=selection_probabilities)
return population[selected_indices]
# 进行轮盘赌选择
selected_population = roulette_wheel_selection(population, fitness_values)
print("选择后的种群:\n", selected_population)交叉操作:交叉操作是将两个父代个体的部分基因进行交换,从而产生新的子代个体。常见的交叉方法有单点交叉、多点交叉等 。单点交叉是在两个父代个体中随机选择一个交叉点,将交叉点之后的基因进行交换。以下是单点交叉的 Python 代码示例:
def single_point_crossover(parent1, parent2):
"""
单点交叉
:param parent1: 父代1
:param parent2: 父代2
:return: 子代1, 子代2
"""
crossover_point = np.random.randint(1, len(parent1) - 1)
child1 = np.concatenate((parent1[:crossover_point], parent2[crossover_point:]))
child2 = np.concatenate((parent2[:crossover_point], parent1[crossover_point:]))
return child1, child2
# 示例:进行单点交叉
parent1 = selected_population[0]
parent2 = selected_population[1]
child1, child2 = single_point_crossover(parent1, parent2)
print("交叉产生的子代:\n", child1, "\n", child2)- 变异操作:变异操作是对子代个体的某些基因进行随机改变,以增加种群的多样性,避免算法陷入局部最优解 。以位变异为例,即随机选择个体的某个基因位,将其值取反(0 变为 1,1 变为 0)。以下是位变异的 Python 代码实现:
def mutation(individual, mutation_rate=0.01):
"""
变异操作
:param individual: 个体
:param mutation_rate: 变异率
:return: 变异后的个体
"""
for i in range(len(individual)):
if np.random.random() < mutation_rate:
individual[i] = 1 - individual[i]
return individual
# 示例:对个体进行变异
mutated_child1 = mutation(child1)
print("变异后的子代1:", mutated_child1)- 迭代进化:通过不断迭代选择、交叉、变异操作,生成新的种群,直到满足停止条件(如达到最大迭代次数、适应度不再提升等) 。以下是完整的迭代进化的 Python 代码:
def genetic_algorithm(population_size, chromosome_length, generations, mutation_rate):
"""
遗传算法主函数
:param population_size: 种群大小
:param chromosome_length: 染色体长度
:param generations: 迭代次数
:param mutation_rate: 变异率
:return: 最优个体, 最优适应度
"""
population = generate_population(population_size, chromosome_length)
best_fitness = -1
best_individual = None
for generation in range(generations):
fitness_values = [fitness_function(individual) for individual in population]
current_best_fitness = max(fitness_values)
if current_best_fitness > best_fitness:
best_fitness = current_best_fitness
best_individual = population[np.argmax(fitness_values)]
selected_population = roulette_wheel_selection(population, fitness_values)
new_population = []
for i in range(0, population_size, 2):
parent1 = selected_population[i]
parent2 = selected_population[i + 1] if i + 1 < population_size else selected_population[0]
child1, child2 = single_point_crossover(parent1, parent2)
mutated_child1 = mutation(child1, mutation_rate)
mutated_child2 = mutation(child2, mutation_rate)
new_population.extend([mutated_child1, mutated_child2])
population = np.array(new_population)
return best_individual, best_fitness
# 运行遗传算法
best_individual, best_fitness = genetic_algorithm(population_size=50, chromosome_length=10, generations=100,
mutation_rate=0.01)
print("最优个体:", best_individual)
print("最优适应度:", best_fitness)四、案例实战:函数优化
(一)问题描述
我们以寻找函数\(f(x) = -x^2 + 10x\)在区间\([0, 10]\)内的最大值为例。这个函数是一个二次函数,其图像是一个开口向下的抛物线,理论上在\(x = 5\)时取得最大值\(f(5) = 25\)。我们的目标是使用遗传算法来逼近这个最优解。
(二)代码实现
import numpy as np
import matplotlib.pyplot as plt
# 目标函数
def objective_function(x):
return -x ** 2 + 10 * x
# 初始化种群
def initialize_population(population_size, chromosome_length, lower_bound, upper_bound):
return np.random.uniform(lower_bound, upper_bound, size=(population_size, chromosome_length))
# 适应度评估
def evaluate_fitness(population):
return np.array([objective_function(individual[0]) for individual in population])
# 轮盘赌选择
def roulette_wheel_selection(population, fitness):
total_fitness = sum(fitness)
selection_probabilities = fitness / total_fitness
selected_indices = np.random.choice(len(population), size=len(population), p=selection_probabilities)
return population[selected_indices]
# 单点交叉
def single_point_crossover(parent1, parent2):
crossover_point = np.random.randint(1, len(parent1))
child1 = np.concatenate((parent1[:crossover_point], parent2[crossover_point:]))
child2 = np.concatenate((parent2[:crossover_point], parent1[crossover_point:]))
return child1, child2
# 变异操作
def mutation(individual, mutation_rate, lower_bound, upper_bound):
for i in range(len(individual)):
if np.random.random() < mutation_rate:
individual[i] = np.random.uniform(lower_bound, upper_bound)
return individual
# 遗传算法主函数
def genetic_algorithm(population_size, chromosome_length, generations, mutation_rate, lower_bound, upper_bound):
population = initialize_population(population_size, chromosome_length, lower_bound, upper_bound)
best_fitness_history = []
for generation in range(generations):
fitness = evaluate_fitness(population)
best_fitness_history.append(max(fitness))
selected_population = roulette_wheel_selection(population, fitness)
new_population = []
for i in range(0, population_size, 2):
parent1 = selected_population[i]
parent2 = selected_population[i + 1] if i + 1 < population_size else selected_population[0]
child1, child2 = single_point_crossover(parent1, parent2)
mutated_child1 = mutation(child1, mutation_rate, lower_bound, upper_bound)
mutated_child2 = mutation(child2, mutation_rate, lower_bound, upper_bound)
new_population.extend([mutated_child1, mutated_child2])
population = np.array(new_population)
best_individual = population[np.argmax(evaluate_fitness(population))]
return best_individual, best_fitness_history
# 参数设置
population_size = 50
chromosome_length = 1
generations = 100
mutation_rate = 0.01
lower_bound = 0
upper_bound = 10
# 运行遗传算法
best_individual, best_fitness_history = genetic_algorithm(population_size, chromosome_length, generations,
mutation_rate, lower_bound, upper_bound)
print("最优解 x:", best_individual[0])
print("最优适应度 f(x):", objective_function(best_individual[0]))
# 绘制适应度变化曲线
plt.plot(range(generations), best_fitness_history)
plt.xlabel('迭代次数')
plt.ylabel('最优适应度')
plt.title('遗传算法适应度变化曲线')
plt.show()
代码关键部分注释说明:
-
目标函数:objective_function定义了我们要优化的函数\(f(x) = -x^2 + 10x\) 。
-
初始化种群:initialize_population函数使用np.random.uniform在指定区间内随机生成初始种群,每个个体的染色体长度为 1 。
-
适应度评估:evaluate_fitness函数计算种群中每个个体的适应度,即目标函数的值 。
-
轮盘赌选择:roulette_wheel_selection实现了轮盘赌选择方法,根据个体的适应度计算选择概率,适应度越高的个体被选中的概率越大 。
-
单点交叉:single_point_crossover进行单点交叉操作,随机选择一个交叉点,交换两个父代个体在交叉点后的基因 。
-
变异操作:mutation函数以一定的变异率对个体进行变异,随机改变个体的基因值 。
-
遗传算法主函数:genetic_algorithm整合了遗传算法的各个步骤,包括初始化种群、适应度评估、选择、交叉、变异和迭代进化,同时记录每一代的最优适应度,用于后续绘制适应度变化曲线 。
(三)结果分析
运行上述代码后,我们可以得到遗传算法找到的最优解和最优适应度。从结果中可以看到,随着迭代次数的增加,遗传算法逐渐逼近最优解。
通过绘制适应度变化曲线(如图 1 所示),我们可以更直观地观察遗传算法的收敛过程。在迭代初期,适应度值波动较大,这是因为种群中的个体差异较大,算法在解空间中进行广泛的搜索。随着迭代的进行,适应度值逐渐上升并趋于稳定,说明算法逐渐收敛到最优解附近。最终,遗传算法找到的最优解接近理论上的最大值,验证了遗传算法在函数优化问题上的有效性。
图 1:遗传算法适应度变化曲线
五、遗传算法的应用拓展
遗传算法在众多领域都有着广泛的应用,展现了其强大的优化能力。
在机器学习领域,遗传算法可以用于神经网络的结构优化和超参数调优 。神经网络的结构和超参数对其性能有着重要影响,传统的手动调参方式不仅耗时费力,而且难以找到最优的参数组合。遗传算法可以通过对神经网络的结构和超参数进行编码,将其作为个体进行进化,从而自动搜索到较优的神经网络结构和超参数配置。例如,在图像识别任务中,使用遗传算法优化卷积神经网络的层数、滤波器数量等超参数,可以显著提高模型的准确率 。在神经网络结构搜索中,遗传算法能够探索不同的网络连接方式和神经元数量,找到更适合特定任务的网络结构 。
在组合优化领域,旅行商问题(TSP)是一个经典的应用场景 。假设有一个旅行商需要拜访多个城市,每个城市之间的距离已知,旅行商需要找到一条最短的路径,使得他能够遍历所有城市且每个城市只访问一次。遗传算法可以将城市的访问顺序编码为染色体,通过选择、交叉和变异等操作,不断优化路径,最终找到近似最优的旅行路线。当城市数量为 20 时,使用遗传算法能够在合理的时间内找到接近最优解的路径,大大提高了求解效率 。
背包问题也是组合优化中的常见问题 。给定一个背包和一些物品,每个物品都有自己的重量和价值,背包有一定的容量限制,目标是选择一些物品放入背包,使得背包内物品的总价值最大,同时总重量不超过背包容量。遗传算法通过将物品的选择情况编码为染色体,以背包的总价值作为适应度函数,能够有效地找到最优的物品组合 。
在工程设计领域,遗传算法同样发挥着重要作用 。以飞机翼结构优化设计为例,工程师需要在满足结构强度要求的前提下,最小化飞机翼的重量,以提高飞机的性能和燃油效率 。遗传算法可以将飞机翼的形状参数、材料参数等编码为染色体,通过模拟进化过程,不断调整这些参数,最终找到既满足强度要求又重量较轻的飞机翼设计方案 。在电力系统规划中,遗传算法可以用于优化发电厂的选择、变电站的布置和输电线路的规划,以最小化总系统成本,同时满足供电可靠性和其他约束条件 。
六、总结与展望
遗传算法作为一种强大的优化算法,从生物进化中汲取灵感,通过模拟自然选择和遗传过程,为解决复杂问题提供了高效的解决方案。在本文中,我们深入探讨了遗传算法的原理,详细介绍了如何使用 Python 实现遗传算法,并通过函数优化的案例实战展示了其实际应用效果,还拓展了遗传算法在机器学习、组合优化和工程设计等领域的应用 。
随着科技的不断发展,遗传算法有望在更多领域发挥重要作用。在人工智能领域,遗传算法可以与深度学习相结合,用于优化神经网络的结构和参数,提高模型的性能和泛化能力。在复杂系统的优化中,如交通流量优化、能源分配优化等,遗传算法可以帮助我们找到更优的解决方案,提高系统的效率和可持续性 。
希望读者通过本文对遗传算法有更深入的了解,并尝试将其应用到实际问题中。遗传算法的世界充满了无限的可能性,期待大家在实践中不断探索和创新,发现遗传算法更多的潜力 。


















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











