






抖音电商平台用户行为分析与个性化推荐项目报告(python+机器学习+tableau)
一. 项目简介
本项目旨在利用 Python 和机器学习技术对抖音电商平台用户数据集进行深入分析,并通过 Tableau 实现数据可视化,从而揭示用户行为模式,为个性化推荐和营销策略提供数据支持。
二. 数据来源与说明
数据集来源于 Kaggle 平台,链接:电商平台用户数据。
该数据集包含了抖音电商平台用户的基本信息、行为习惯和互动数据。详细字段说明如下:
| 排序 | 字段 | 备注 |
|---|---|---|
| 1 | User ID | 每个用户的唯一标识符,便于追踪和分析 |
| 2 | Age | 用户的年龄,提供对人口统计偏好的洞察 |
| 3 | Gender | 用户的性别,使能性别特定的推荐和定位 |
| 4 | Location | 用户所在地区:郊区、农村、城市,影响偏好和购物习惯 |
| 5 | income | 用户的收入水平,表明购买力和支付能力 |
| 6 | Interests | 用户的兴趣,如运动、时尚、技术等,指导内容和产品推荐 |
| 7 | Last Login_Days_Ago | 用户上次登录以来的天数,反映参与频率 |
| 8 | Purchase Frequency | 用户进行购买的频率,表明购物习惯和忠诚度 |
| 9 | Average Order Value | 用户下单的平均价值,对定价和促销策略至关重要 |
| 10 | Total Spending | 用户消费的总金额,表明终身价值和购买行为 |
| 11 | Product_Category_Preference | 用户偏好的特定产品类别 |
| 12 | Time_Spent on Site Minutes | 用户在电子商务平台上花费的时间,表明参与程度 |
| 13 | Pages_Viewed | 用户在访问期间浏览的页面数量,反映浏览活动和兴趣 |
| 14 | Newsletter Subscription | 用户是否订阅了营销活动通知 |
三. 研究问题
- 对用户进行购买行为分析
- 进行 RFM 分析
- 对用户活跃度进行分析
- 进行个性化推荐预测
四. 数据预处理
1. 数据导入
import pandas as pd
import numpy as np
df = pd.read_csv(r"D:\Downloads\data\user_personalized_features.csv")
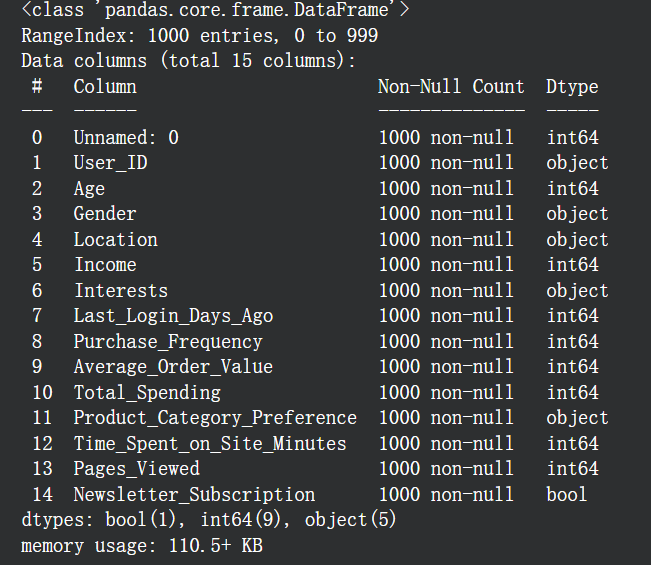
2. 查看字段类型
# 查看各字段信息,并输出字段,字段类型等,最后输出各种类型的数量
df.info()
3. 数据清洗
1)删除多余列
# 删除多余列
df.drop('Unnamed: 0',axis=1,inplace=True)# 注释:Unnamed 和 0 之间有空格,axis=1 即为列删除
df.head()

2)数据去重
# 对数据去重
df.drop_duplicates(subset=None,inplace=True)
3)过滤无效的值
df=df[df['Income']>0]
4)删除缺失值
# 删除缺失值
df.dropna(subset=None,how='any',axis=0,inplace=True) # 注释:对所有列处理,只要一行有缺失值就删除这行
五. 数据分析
1. 购买行为分析
- 分析购买频率、平均订单价值、总消费金额的分布。
- 探索不同用户群体(如不同性别、地区、年龄段)的购买行为差异。
- 识别高价值用户和低价值用户。
# 按性别统计平均购买频率和总消费金额
purchase_by_gender = df.groupby('Gender').agg(
avg_purchase_freq=('Purchase_Frequency', 'mean'),
total_spending=('Total_Spending', 'sum')
).reset_index()
print("按性别统计的购买行为:")
purchase_by_gender
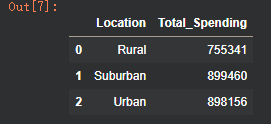
# 按地区统计总消费金额
spend_by_location = df.groupby('Location')['Total_Spending'].sum().reset_index()
print("\n按地区统计的总消费金额:")
spend_by_location
2. RFM 分析
1)RFM 模型介绍
RFM 模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的最近一次消费时间(Recency)、消费频率(Frequency)、消费金额(Monetary)三项指标来描述该客户的价值情况。在电商领域,RFM 模型可以帮助企业了解客户的购买行为和购买偏好,从而识别高价值顾客、潜在回头客或者低活跃用户,这有助于电商企业定制个性化的营销策略。
RFM 模型通过三个关键指标来描述客户的价值状况:
- R(Recency):最近一次消费时间。 它表示用户最后一次下单时间距今天有多长时间。这个指标与用户流失和复购直接相关,如果客户最近消费过,那么他们更有可能再次消费。
- F(Frequency):消费频率。 它表示用户在固定的时间段内消费了多少次。这个指标反映了用户的消费活跃度,消费频率越高的客户,对商家的忠诚度通常也越高。
- M(Monetary):消费金额。 它表示用户在固定的周期内在平台上花费了多少钱。这个指标直接反映了用户对公司贡献的价值,消费金额越高的客户,通常被认为价值越大。
这三个指标共同构成了 RFM 模型,帮助商家更好地理解和评估客户的价值,从而制定更加精准的营销策略,提高客户留存率,促进客户消费,最终实现业务的增长。同时,通过 RFM 模型,企业可以将客户进行细分,针对不同群体的客户采取不同的营销策略,实现精准营销。
2)RFM 分析实现
- RFM 计算:最近一次登录、购买频率、总消费金额。
- 用户分群:高价值客户、潜力客户、一般客户、流失风险客户。
3)对数据进行分类
替换列名
# 准备 RFM 分析所需的数据
# 选取用户 ID、上次登录天数、购买频率和总消费金额列
rfm_df = df[["User_ID", "Last_Login_Days_Ago", "Purchase_Frequency", "Total_Spending"]].copy() # 使用 .copy() 避免 SettingWithCopyWarning
# 重命名列,使其符合 RFM 模型指标的命名习惯
# Recency: 最近一次登录的天数(越小越好)
# Frequency: 购买频率(越大越好)
# Monetary: 总消费金额(越大越好)
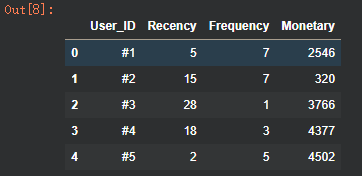
rfm_df.columns = ["User_ID", "Recency", "Frequency", "Monetary"]
# 打印 RFM 数据框的前几行,查看重命名结果
rfm_df.head()
数据复制
在 pandas 里,当你对一个 DataFrame 进行切片操作后得到的对象,可能是原 DataFrame 的视图(view),而非独立的副本(copy)。视图是对原数据的一种引用,对视图进行赋值等修改操作时,会出现一些难以预期的情况。
rfm = rfm.copy() 这行代码通过创建独立副本,确保后续对 rfm 的修改操作清晰明确,避免了在对 DataFrame 切片进行赋值等操作时出现的警告和潜在的数据不一致问题。
rfm_df = rfm_df.copy() # 注释:为避免 A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
a. 对 Recency 分箱评分
# a. 对 Recency 进行分箱评分(越小分数越高)
# 定义 Recency 的分箱阈值(示例:根据业务需要调整)
# 边界值:0-7天得5分,8-14天得4分,15-21天得3分,22-28天得2分,29天及以上得1分
recency_bins = [0, 7, 14, 21, 28, float('inf')]
# 对应的分数(与分箱阈值一一对应)
recency_labels = [5, 4, 3, 2, 1]
# 新建 'R_Score' 列,并初始化为 0
rfm_df['R_Score'] = 0
# 遍历分箱阈值,为 Recency 值落在不同区间的用户赋予相应的分数
for i in range(len(recency_bins) - 1):
lower = recency_bins[i] # 当前区间的下限
upper = recency_bins[i+1] # 当前区间的上限
# 使用 .loc[] 进行条件筛选和赋值,避免 SettingWithCopyWarning
# 筛选出 Recency 大于下限且小于等于上限的用户
rfm_df.loc[(rfm_df['Recency'] > lower) & (rfm_df['Recency'] <= upper), 'R_Score'] = recency_labels[i]
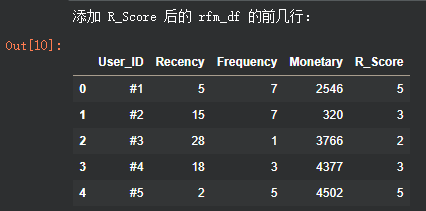
# 打印更新后的 rfm_df 数据框的前几行,查看 R_Score 列
print("添加 R_Score 后的 rfm_df 的前几行:")
rfm_df.head()
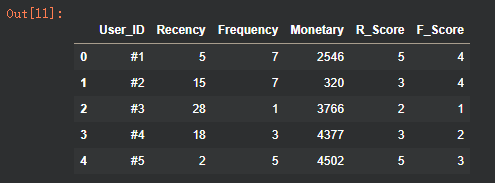
b. 对 Frequency 分箱评分
# b. 对 Frequency 进行分箱评分 (越大得分越高)
# 定义 Frequency 的分箱阈值(示例:根据业务需要调整)
# 边界值:0-2次得1分,3-4次得2分,5-6次得3分,7-8次得4分,9次及以上得5分
frequency_bins = [0, 2, 4, 6, 8, float('inf')]
# 对应的分数(与分箱阈值一一对应)
frequency_labels = [1, 2, 3, 4, 5]
# 新建 'F_Score' 列,并初始化为 0
rfm_df["F_Score"] = 0
# 遍历分箱阈值,为 Frequency 值落在不同区间的用户赋予相应的分数
for i in range(len(frequency_bins) - 1):
lower = frequency_bins[i] # 当前区间的下限
upper = frequency_bins[i+1] # 当前区间的上限
# 使用 .loc[] 进行条件筛选和赋值,避免 SettingWithCopyWarning
# 筛选出 Frequency 大于下限且小于等于上限的用户
rfm_df.loc[(rfm_df["Frequency"] > lower) & (rfm_df["Frequency"] <= upper), "F_Score"] = frequency_labels[i]
# 打印更新后的 rfm_df 数据框的前几行,查看 F_Score 列
print("添加 F_Score 后的 rfm_df 的前几行:")
rfm_df.head()
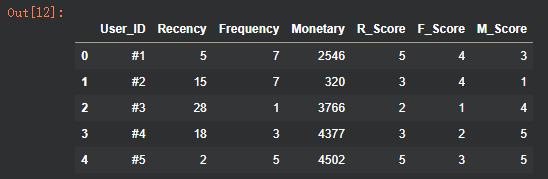
c. 对 Monetary 分箱评分
# c. Monetary 分箱评分(越大得分越高)
# 定义 Monetary 的分箱阈值(示例:根据业务需要调整)
# 边界值:0-1000 得1分,1001-2000 得2分,2001-3000 得3分,3001-4000 得4分,4001及以上得5分
monetary_bins = [0, 1000, 2000, 3000, 4000, float('inf')]
# 对应的分数(与分箱阈值一一对应)
monetary_labels = [1, 2, 3, 4, 5]
# 新建 'M_Score' 列,并初始化为 0
rfm_df["M_Score"] = 0
# 遍历分箱阈值,为 Monetary 值落在不同区间的用户赋予相应的分数
for i in range(len(monetary_bins) - 1):
lower = monetary_bins[i] # 当前区间的下限
upper = monetary_bins[i+1] # 当前区间的上限
# 使用 .loc[] 进行条件筛选和赋值,避免 SettingWithCopyWarning
# 筛选出 Monetary 大于下限且小于等于上限的用户
rfm_df.loc[(rfm_df["Monetary"] > lower) & (rfm_df["Monetary"] <= upper), "M_Score"] = monetary_labels[i]
# 打印更新后的 rfm_df 数据框的前几行,查看 M_Score 列
print("添加 M_Score 后的 rfm_df 的前几行:")
rfm_df.head()
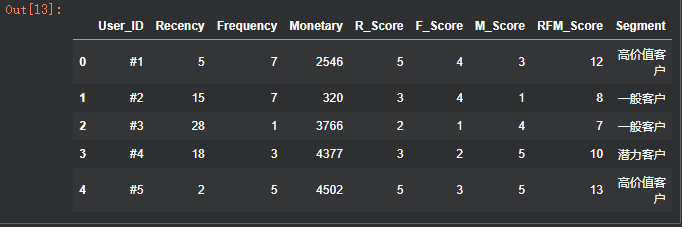
d. 客户分类
# d. 用户分类
# 计算 RFM 总分
rfm_df["RFM_Score"] = rfm_df["R_Score"] + rfm_df["F_Score"] + rfm_df["M_Score"]
# 根据 RFM 总分对用户进行分类
# 初始化 'Segment' 列为默认类别
rfm_df["Segment"] = "客户类别"
# 使用 .loc[] 进行条件筛选和赋值,避免 SettingWithCopyWarning
# 分类规则(示例:根据业务需要调整阈值)
rfm_df.loc[rfm_df["RFM_Score"] >= 12, "Segment"] = "高价值客户"
rfm_df.loc[(rfm_df["RFM_Score"] >= 9) & (rfm_df["RFM_Score"] < 12), "Segment"] = "潜力客户"
rfm_df.loc[(rfm_df["RFM_Score"] >= 6) & (rfm_df["RFM_Score"] < 9), "Segment"] = "一般客户"
rfm_df.loc[rfm_df["RFM_Score"] < 6, "Segment"] = "流失风险客户"
rfm_df.head()
3. 用户活跃度分析
要求:
- 高活跃用户:最近七天内登录且网站停留时间 >= 300 分钟
- 低活跃用户:超过 30 天未登录且停留时间 < 100 分钟
- 普通用户:不满足以上条件的用户
# 3. 用户活跃度分析
# 初始化 'Active_Status' 列为默认类别
df["Active_Status"] = "普通用户"
# 使用 .loc[] 进行条件筛选和赋值,避免 SettingWithCopyWarning
# 定义高活跃用户的条件:最近七天内登录且网站停留时间 >= 300 分钟
df.loc[(df["Last_Login_Days_Ago"] <= 7) & (df["Time_Spent_on_Site_Minutes"] >= 300), "Active_Status"] = "高活跃用户"
# 定义低活跃用户的条件:超过 30 天未登录且停留时间 < 100 分钟
df.loc[(df["Last_Login_Days_Ago"] > 30) & (df["Time_Spent_on_Site_Minutes"] < 100), "Active_Status"] = "低活跃用户"
df
4. 个性化预测(K-相邻模型)
个性化预测可采用机器学习模型,根据用户的兴趣和产品类型偏好,预测他们可能感兴趣的其他产品类别。
做法:将用户兴趣和产品偏好转换为数值特征。
# 查找用户特征之间的最近邻
from sklearn.neighbors import NearestNeighbors # 注释:NearestNeighbors 是一个无监督学习算法,用于在特征空间中查找最近邻样本
# 构建用户特征矩阵(兴趣 + 产品偏好)
user_features = pd.get_dummies(df[["Interests", "Product_Category_Preference"]]) # 注释:用于将分类变量转换为哑变量(也称为独热编码)。
# 注释:独热编码会为每个分类变量的每个可能取值创建一个新的二进制列,其中 1 表示该样本具有该取值,0 表示不具有。
# 注释:通过这种方式,将分类数据转换为适合机器学习算法处理的数值数据。
model = NearestNeighbors(n_neighbors=5) # 注释:n_neighbors=5 是一个参数设置,表示在查找最近邻时,每个样本要找出 5 个最近的邻居。
model.fit(user_features) # 注释:使用 fit() 方法对模型进行训练,让模型学习 user_features 数据集中的样本分布。
# 为每个用户推荐相似兴趣的 Top 5 商品类别
_, indices = model.kneighbors(user_features) # 注释:model.kneighbors() 方法用于查找每个样本的最近邻。
# 注释:它返回两个数组:第一个数组是每个样本到其最近邻的距离,这里用下划线 _ 表示不使用该数组;
# 注释:第二个数组 indices 是每个样本的最近邻在原始数据集中的索引。
df["Recommended_Category"] = [df.iloc[i]["Product_Category_Preference"].mode()[0] for i in indices] # 注释:这里通过一个循环遍历 indices 数组。
# 注释:对于每个样本的最近邻索引 i,使用 df.iloc[i] 选取这些最近邻对应的行,然后提取 Product_Category_Preference 列的数据。
# 注释:mode() 方法用于找出这些数据中的众数(出现次数最多的值)。
# 注释:如果众数存在,就将其添加到 recommended_categories 列表中;若不存在众数(即 mode_result 为空),则添加 None 到列表中。
5. 导出数据
# 保存结果供 Tableau 可视化
df.to_csv("cleaned_user_data1.csv", index=False)
rfm_df.to_csv("rfm_segments1.csv", index=False) # 注释:index=False 说明导出的数据中不包含 DataFrame 的索引列
六. 数据可视化
1. 数据集的导入和连接
-
由于该数据为 csv 文件,因此导入时 Tableau,要选择 ‘文本文件’。
-
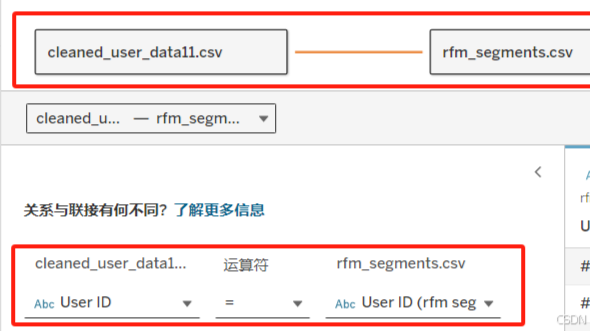
要将两个表进行连接,其中桥梁就是 User_ID。
2. 图形可视化
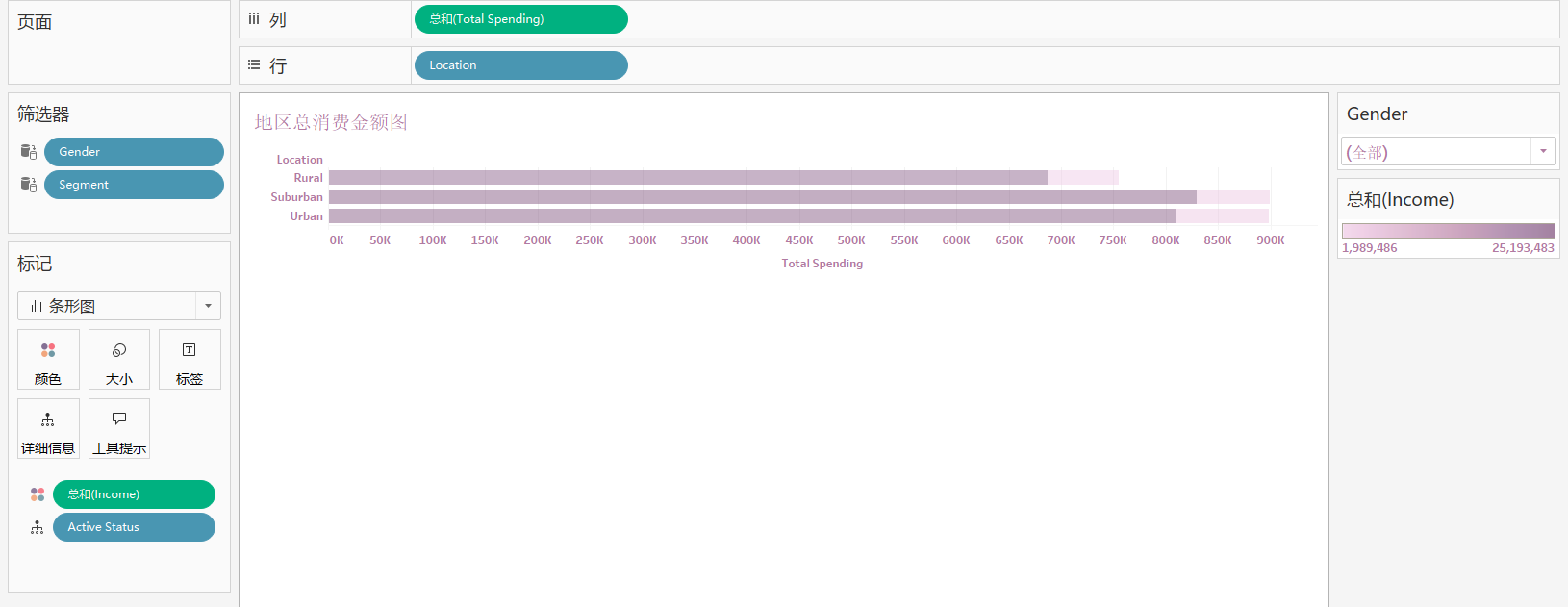
1. 地区总消费金额图 (水平条形图)
分析:不同性别的不同客户的在不同的地区的总消费金额情况
用到:‘Gender’,‘Segment’,‘Location’,‘Active Status’,‘Total Spending’
步骤:
- 将 ‘Total Spending’ 拖到列,‘Location’ 拖到行
- 将 ‘Active Status’ 拖至颜色,对用户进行区分
- 将 ‘Gender’,‘Segment’ 拖至筛选器,并右击后,点 ‘运用于工作表’ - 点 ‘使用相关数据源的所有项’
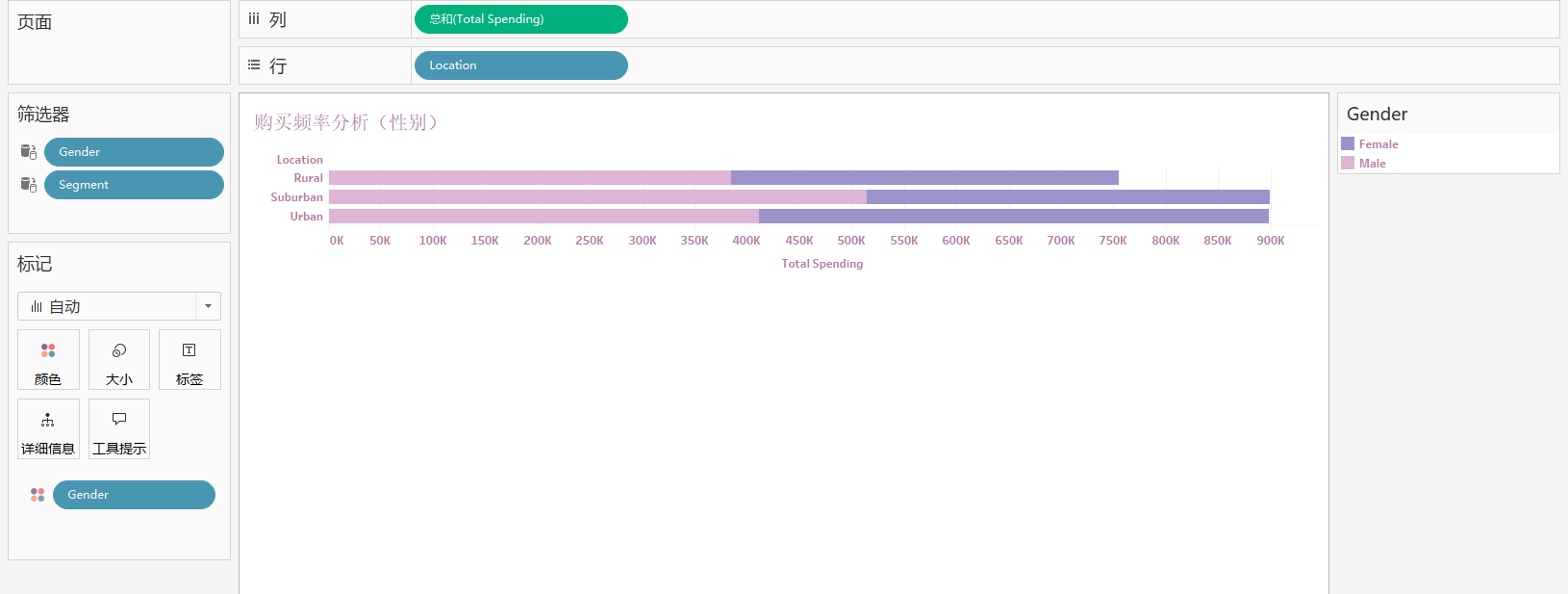
2. 购买频率分析 (性别) (水平条形图)
分析:不同地区的不同性别的总消费金额情况
用到:‘Location’,‘Total Spending’,‘Gender’
步骤:
- 将 ‘Total Spending’ 拖到列,‘Location’ 拖到行
- 将 ‘Gender’ 拖至颜色,对性别进行区分
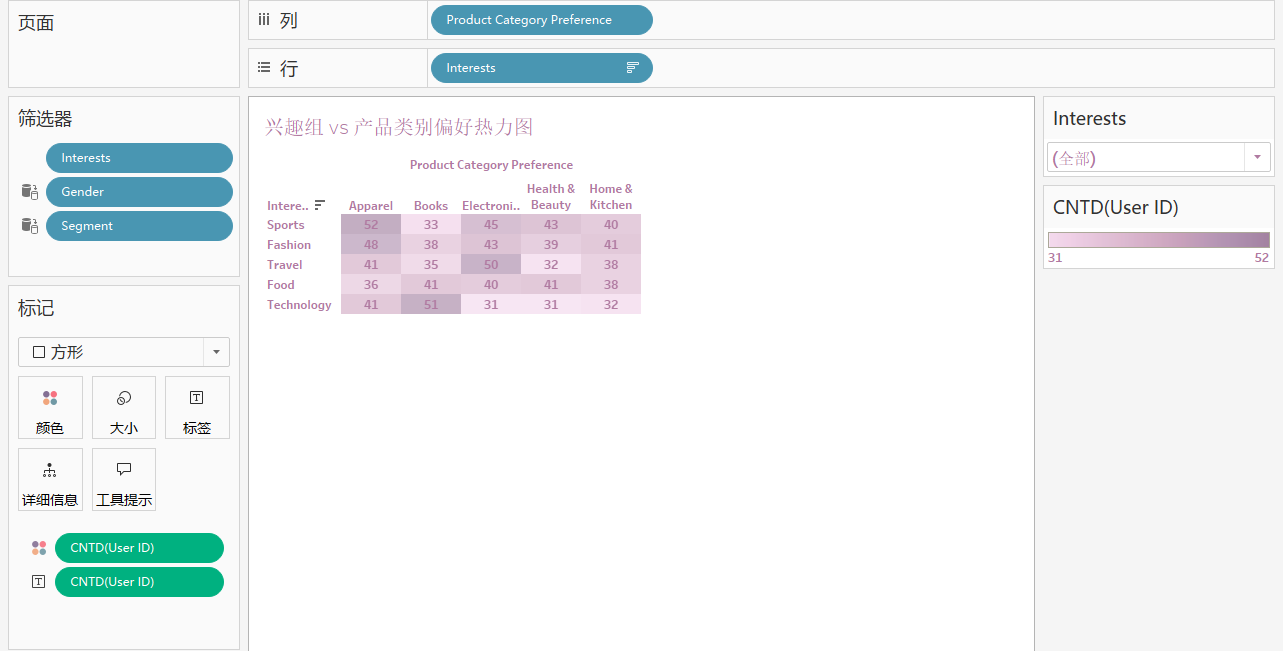
3. 兴趣组 VS 产品类别偏好 (热力图)
分析:不同兴趣下不同产品类别偏好下用户 Id 的计数
用到:‘Product Category Preference’,‘Interests’,‘User_ID’
步骤:
- 将 ‘Product Category Preference’ 拖到列,‘Interests’ 拖到行
- 将 ‘Interests’ 放入筛选器,对兴趣进行筛选
- 将 ‘User_ID’ 放到颜色上,后,右击 ‘User_ID’ - 度量 - 计数 (此处是将 ‘User_ID’ 转变为度量进行计数),复制 ‘User_ID’ 拖到标签里面,最后标记选方形!
4. 用户分群占比图 (环形图)
分析:不同用户分类下的用户 ID 数占比
用到:‘Segment’,‘User_ID’
步骤:
- 将 ‘Segment’ 拖到颜色,标记选饼图,将 ‘User_ID’ 拖到角度,右击 ‘User_ID’ - 度量 - 计数 (此处是将 ‘User_ID’ 转变为度量进行计数)
- 将按住 Shift 将标记中的 ‘Segment’,‘User_ID’ 分别拖到标签,右击标签的 ‘User_ID’ - 快速表计算 = 合计百分比
- 在行中双击输入两个 0,生成两个图形,后点双轴,将下个图层设置都去掉并设置白色,将上个图层放大
- 点 0 轴,取消显示显示标题,右击零值线,将零值线设为无

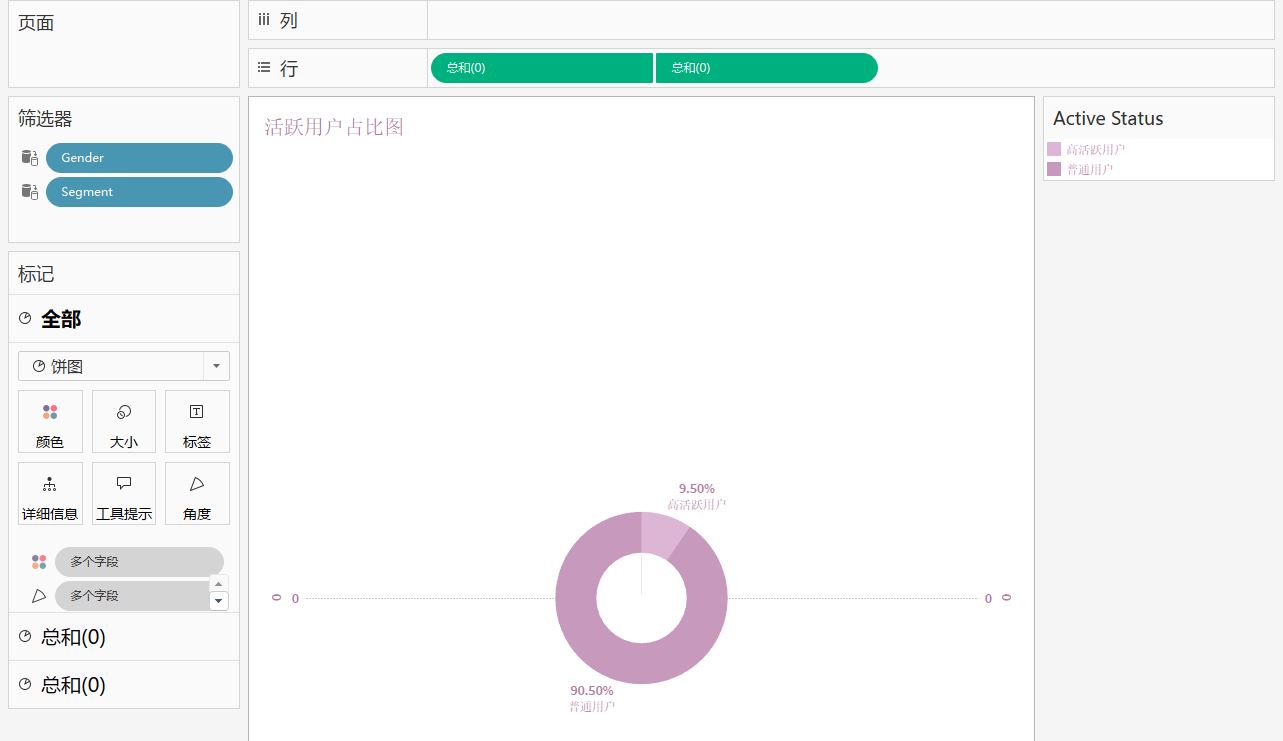
5. 活跃用户占比图 (环形图)
分析:不同活跃用户的的用户 ID 数占比
用到:‘User_ID’,‘Active Status’
步骤:
- 将上个图进行拷贝
- 将上个图中所有 ‘Segment’ 都替换成 ‘Active Status’
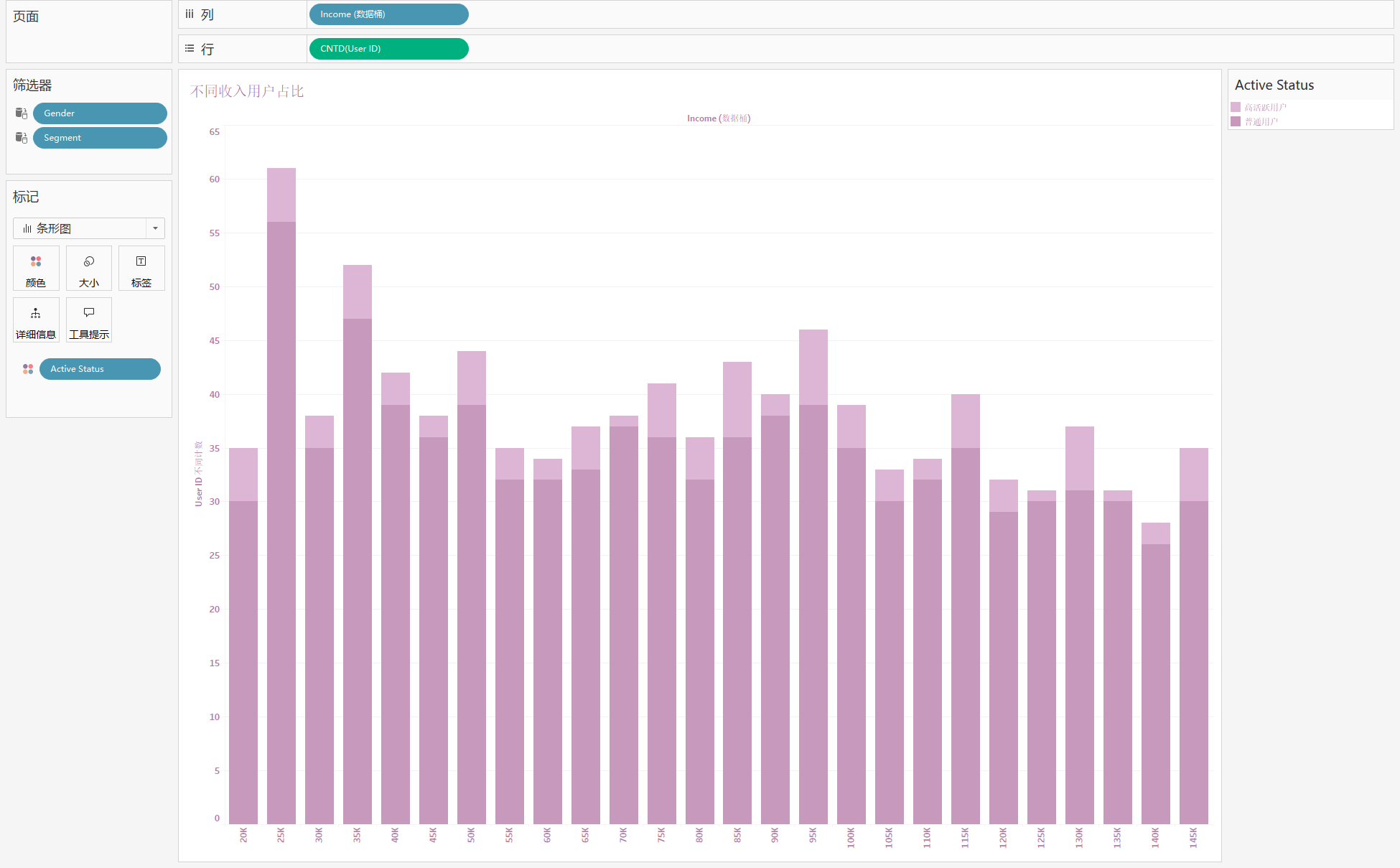
6. 不同收入用户情况分布 (直方图)
分析:不同收入下,不同活跃用户的计数情况
用到:‘Income’,‘User_ID’,‘Active Status’
步骤:
- 创建数据桶:选择 Income,右击 - 创建 - 数据桶,数据桶大小为 5000
- 将 ‘Income (数据桶)’ 拖到列,‘Use_ID’ 拖到行,并转换为计数类型
- 将 ‘Active Status’ 拖到颜色
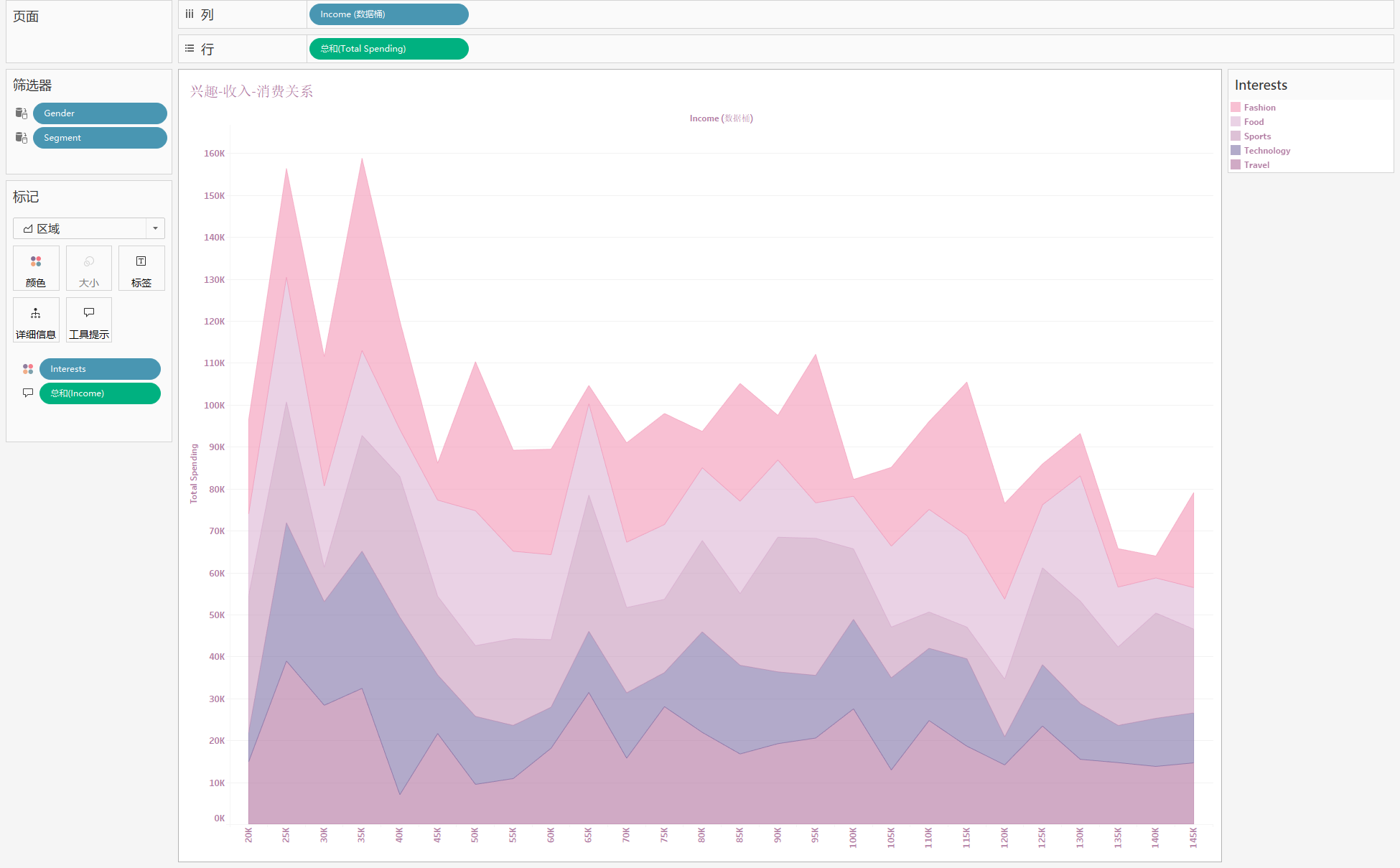
7. 兴趣-收入-消费关系图 (面积图)
分析:随着收入的增加,不同兴趣的总消费金额的变化
用到:‘Income (数据桶)’,‘Total Spending’,‘Interests’
步骤:
- 将 ‘Income (数据桶)’ 拖入列,‘Total Spending’ 拖入行
- ‘Interests’ 拖入颜色,进行区分,将 ‘Interests’ 拖入颜色,标记变为区域
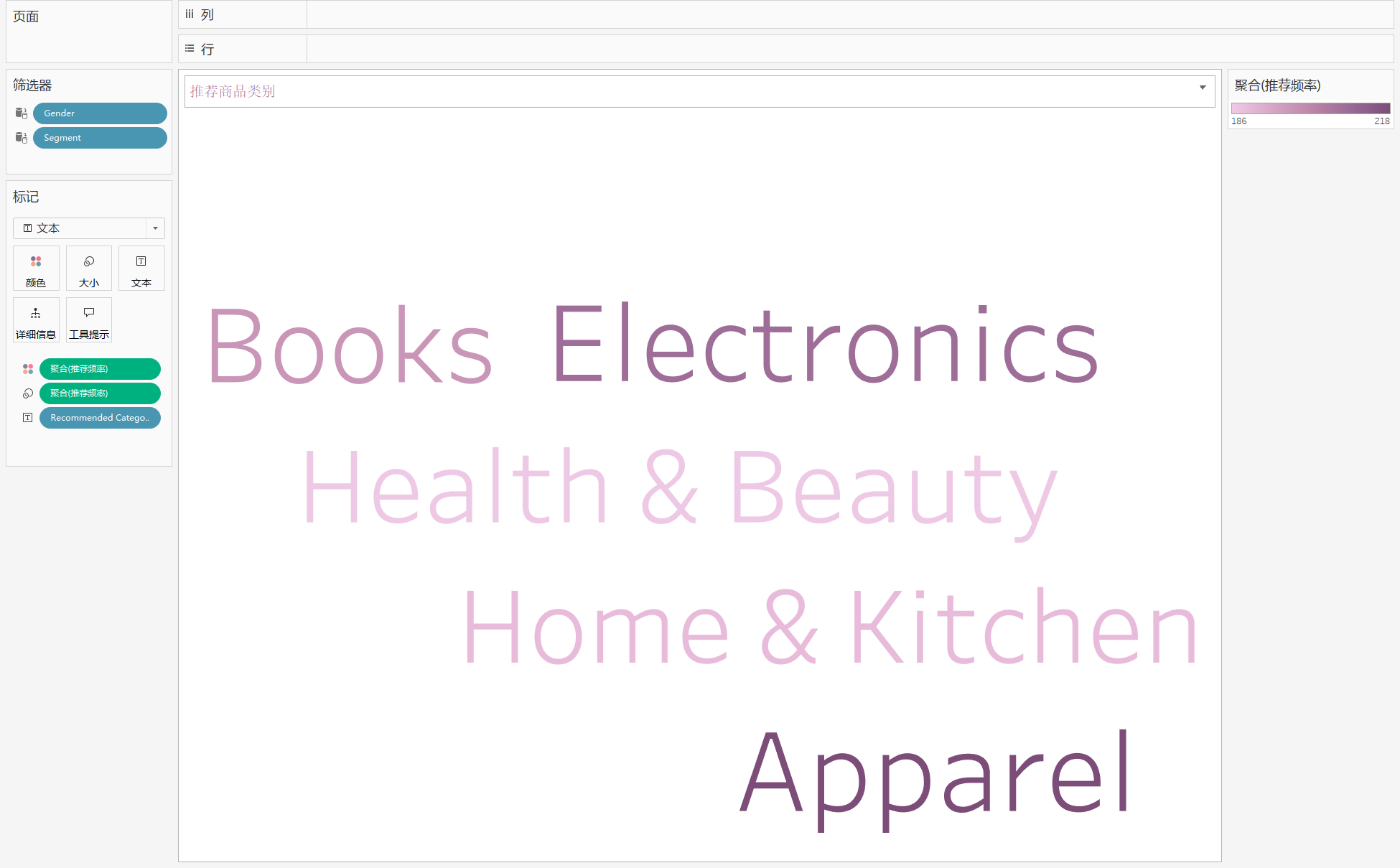
8. 推荐商品类别 (词云图)
分析:分析推荐商品类别的词云图 (无轴图形)
用到:‘User_ID’,‘Recommended Category’
步骤:
- 创建字段:推荐频率 = count([User_ID])
- 将 ‘Recommended Category’ 拖到文本,将 ‘推荐频率’ 拖到颜色卡,复制 ‘推荐频率’ 拖到大小,标记中选择文本
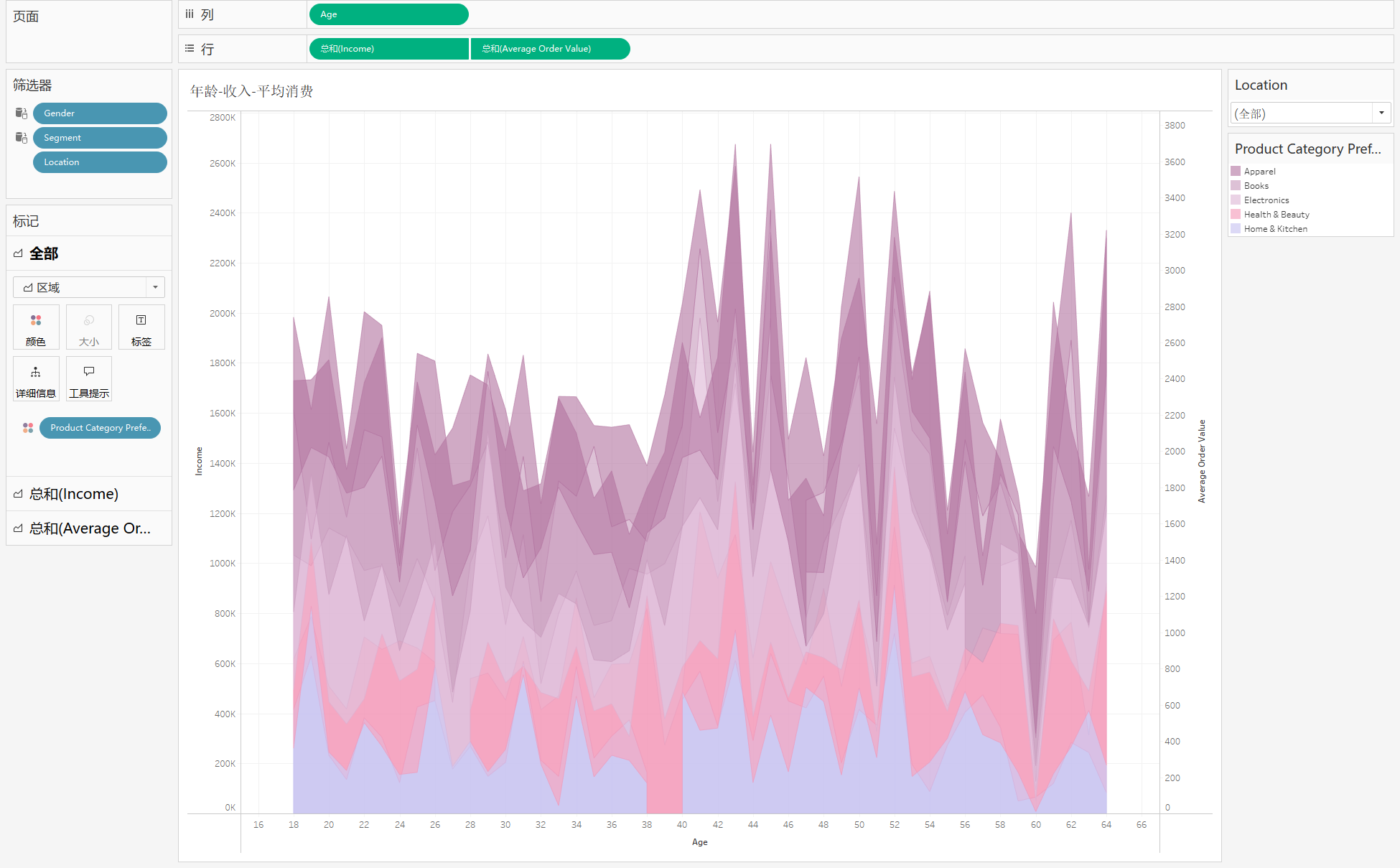
9. 年龄-收入-平均消费图 (面积图)
分析:随着年龄的增长,根据商品类别偏好的不同,分析收入和平均消费的情况
用到:‘Age’,‘Product Category Preference’,‘Average Order Value’,‘Income’
步骤:
- 将 ‘Age’ 拖入行,并转为维度,‘Income’,‘Average Order Value’ 分别放入列,并点双轴
- 在标记中选择全部,将 ‘Product Category Preference’ 放入颜色卡,标记选择区域
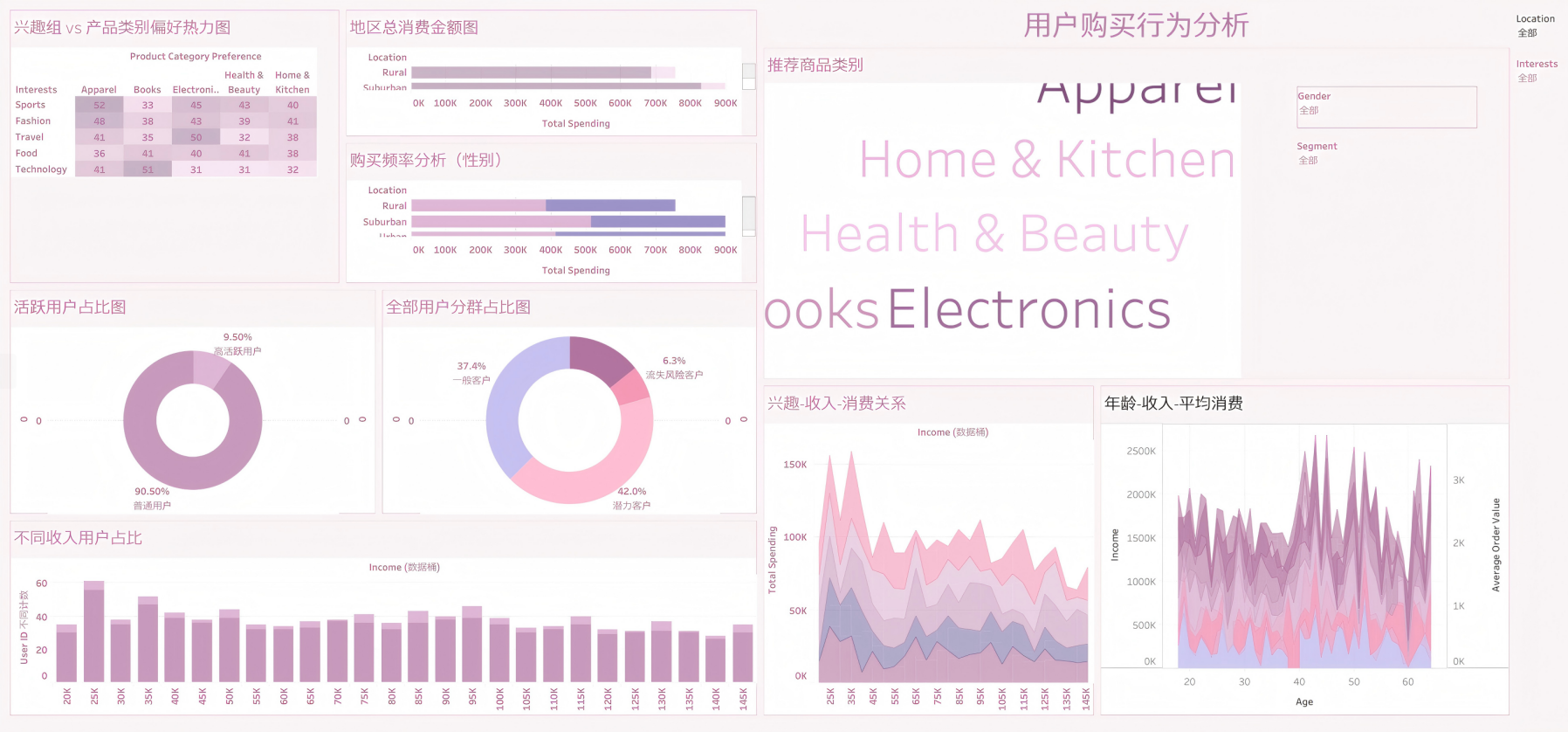
3. 仪表盘的搭建
七. 总结与建议
1. 关键发现
- 高价值客户集中在一线城市(Urban),偏好电子产品和服饰。
- 女性用户平均购买频率比男性高 15%,但男性总消费金额更高。
- 流失风险客户中,60% 超过 30 天未登录,且停留时间低于 100 分钟。
2. 行动建议
- 定向营销: 向高价值客户推送高端电子产品限时折扣。
- 召回策略: 对流失风险客户发送“回归奖励”(如优惠券)。
- 动态推荐: 在首页根据用户兴趣展示推荐商品类别(如 Sports 用户推荐 Apparel)。!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









