









1. 需求分析
1.1. 概述
基于Flask、Pika、Multiprocessing、Thread搭建一个架构,完成多线程、多进程工作。具体需求如下:
- 并行计算任务:使用
multiprocessing模块实现并行计算任务,提高计算效率、计算能力。 - 消息侦听任务:使用
threading模块完成RabbitMQ消息队列的侦听任务,将接收到的数据放入multiprocessing.Queue中,以便并行计算任务处理。 - Web服务:使用
Flask框架实现Web API服务,提供启停消息侦听任务、启停并行计算任务以及动态调整参数的功能。 - 任务交互:通过
multiprocessing.Queue实现消息侦听任务与并行计算任务之间的资源交互。 - 非阻塞运行:使用
threading模块非阻塞地运行Flask Web服务。
1.2. 多线程与多进程
在Python环境中,多线程和多进程的区别主要体现在并发模型、资源利用、数据共享、以及适用场景等方面。
1.2.1. 并发模型
多线程 (Threading):
- 并发性: 多线程是一种并发模型,多个线程共享同一进程的资源和内存空间,能够在单个进程内并发执行。
- GIL 限制: 由于 Python 的全局解释器锁 (Global Interpreter Lock, GIL),同一时刻只有一个线程在执行 Python 字节码。这限制了多线程在 CPU 密集型任务中的并行性。
- 适用任务: 适用于 I/O 密集型任务,如网络请求、文件操作等。
多进程 (Multiprocessing):
- 并行性: 多进程是一种并行模型,每个进程都有独立的内存空间和资源,可以在多个 CPU 核心上并行执行。
- 无 GIL 限制: 每个进程有自己的 Python 解释器和 GIL,能够真正实现并行计算,充分利用多核 CPU。
- 适用任务: 适用于 CPU 密集型任务,如计算密集型数据处理。
1.2.2. 资源利用
多线程:
- 内存利用: 线程共享同一进程的内存空间,内存开销较小。创建和销毁线程的成本较低。
- CPU 利用: 由于 GIL 限制,多线程在 Python 中无法充分利用多核 CPU,尤其是在 CPU 密集型任务中。
多进程:
- 内存利用: 每个进程有独立的内存空间,内存开销较大。创建和销毁进程的成本较高。
- CPU 利用: 无 GIL 限制,可以充分利用多核 CPU,适合并行处理 CPU 密集型任务。
1.2.3. 数据共享和通信
多线程:
- 数据共享: 线程共享同一进程的全局变量和内存空间,数据共享容易。
- 同步机制: 由于共享内存,线程之间需要使用锁 (Lock)、条件变量 (Condition) 等同步机制来避免竞争条件和数据不一致。
多进程:
- 数据共享: 进程间不共享内存,数据共享复杂。需要使用进程间通信 (IPC) 机制,如管道 (Pipe)、队列 (Queue)、共享内存 (Shared Memory) 等。
- 同步机制: 使用 IPC 机制进行数据传递和同步。
1.2.4. 适用场景
多线程:
- I/O 密集型任务: 例如网络爬虫、文件读写、数据库操作等。这些任务在等待 I/O 操作完成时可以切换到其他线程继续执行,提高效率。
- 轻量级任务: 由于线程的创建和销毁成本较低,适合处理大量短时任务。
多进程:
- CPU 密集型任务: 例如科学计算、图像处理、大数据分析等。这些任务需要大量计算资源,多进程可以充分利用多核 CPU 并行处理。
- 隔离性要求高的任务: 进程间独立运行,互不影响,适合需要高隔离性的任务。
1.2.5. 常见问题与解决
多线程:
- 死锁: 当多个线程互相等待对方释放锁时,会出现死锁情况。需要设计合理的锁机制或使用死锁检测工具。
- GIL 限制: 对于 CPU 密集型任务,GIL 限制了多线程的并行性。可以通过多进程绕过 GIL 实现并行计算。
多进程:
- 高内存消耗: 每个进程有独立的内存空间,内存使用较高。可以通过共享内存或减少进程数量优化内存使用。
- 进程间通信复杂: 需要使用 IPC 机制进行进程间数据传递,设计和实现较为复杂。可以使用 Python 的 multiprocessing 模块提供的队列、管道等工具简化实现。
1.2.6. 总结
- 多线程: 适合 I/O 密集型任务,内存使用高效,但受 GIL 限制。
- 多进程: 适合 CPU 密集型任务,可以充分利用多核 CPU,但内存消耗较大,进程间通信复杂。
根据任务性质选择合适的并发模型,可以提高程序的效率和性能。
2. 我初步实现多线程多进程核心代码
2.1. 程序结构及代码说明
程序结构原理图:
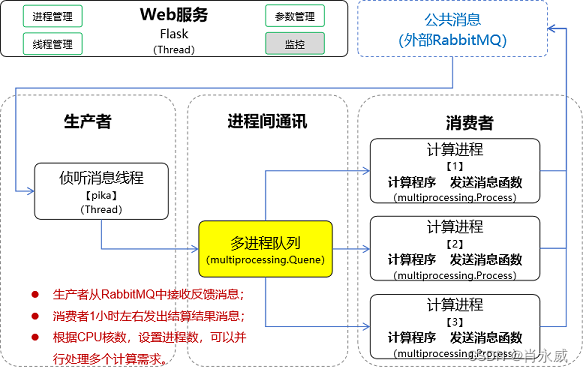
函数说明:
| 序号 | 名称 | 说明 | 备注 |
|---|---|---|---|
| 1 | compute_result | 计算函数,例如你的优化算法 | 需要并行处理 |
| 2 | send_result_to_rabbitmq | 发送消息到RabbitMQ | |
| 3 | consume_from_rabbitmq_and_enqueue | 侦听RabbltMQ消息 | |
| 4 | worker | 工作进程函数 | |
| 5 | start_listening | 启动消息侦听函数 | Web API |
| 6 | stop_listening | 停止消息侦听函数 | Web API |
| 7 | start_worker | 启动工作函数 | Web API |
| 8 | stop_worker | 停止工作函数 | Web API |
2.2. 示例代码
from flask import Flask, jsonify
from threading import Thread, Event
import multiprocessing
import pika
import json
from loguru import logger
# 创建一个事件来控制侦听
stop_event = Event()
# 定义web服务
app = Flask(__name__)
# 假设这是你的计算函数
def compute_result(data, pso_params):
# 进行计算逻辑,这里简化为返回数据本身
return {"result": data}
# 发送结果到RabbitMQ的函数
def send_result_to_rabbitmq(channel, exchange_name, queue_name, routing_key, result):
try:
channel.queue_declare(queue=queue_name, durable=True)
# 初始化交换机
channel.exchange_declare(exchange=exchange_name, exchange_type='direct', durable=True)
channel.queue_bind(queue=queue_name, exchange=exchange_name, routing_key=routing_key)
channel.basic_publish(
exchange=exchange_name,
routing_key=routing_key,
body=json.dumps(result, ensure_ascii=False),
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
logger.info(f"发送结果消息:{result} 到RabbitMQ")
except pika.exceptions.AMQPError as e:
logger.error(f"Error sending result to RabbitMQ: {e}")
raise
# 从RabbitMQ接收数据并放入队列的函数(生产者)
def consume_from_rabbitmq_and_enqueue(rabbitmq_params, rabbitmq_queue, data_queue):
try:
rabbitmq_connection = pika.BlockingConnection(rabbitmq_params)
except pika.exceptions.AMQPError as e:
logger.error(f"Error connecting to RabbitMQ in main process: {e}")
exit(1)
try:
channel = rabbitmq_connection.channel()
channel.queue_declare(queue=rabbitmq_queue, durable=True)
def callback(ch, method, properties, body):
try:
data_queue.put(body.decode('utf-8'))
logger.info(f"接收到消息:{body.decode('utf-8')}")
except Exception as e:
logger.error(f"Error putting message into data_queue: {e}")
channel.basic_consume(queue=rabbitmq_queue, on_message_callback=callback, auto_ack=True)
try:
while not stop_event.is_set():
channel.connection.process_data_events(time_limit=1) # 非阻塞地处理事件
# 注意:这里使用了process_data_events()而不是start_consuming(),因为我们需要非阻塞地运行
except KeyboardInterrupt:
channel.stop_consuming()
finally:
rabbitmq_connection.close()
except pika.exceptions.AMQPError as e:
logger.error(f"Error consuming from RabbitMQ: {e}")
raise
# 工作进程函数
def worker(data_queue, rabbitmq_params, target_exchange, target_queue, routing_key, pso_params):
logger.info('Worker started')
while True:
try:
data = data_queue.get()
print(f'data_queue.get() is {data}')
if data is None:
break
result = compute_result(data, pso_params)
try:
workerconnection = pika.BlockingConnection(rabbitmq_params)
channel = workerconnection.channel()
except pika.exceptions.AMQPError as e:
logger.error(f"Error connecting to RabbitMQ in worker: {e}")
return
send_result_to_rabbitmq(channel, target_exchange, target_queue, routing_key, result)
except Exception as e:
print(f"An error occurred: {e}")
logger.info('Worker finished')
@app.route('/startlistening', methods=['GET'])
def start_listening():
if stop_event.is_set():
stop_event.clear()
if not hasattr(app, 'pika_thread') or not app.pika_thread.is_alive():
app.pika_thread = Thread(target=consume_from_rabbitmq_and_enqueue, args=(rabbitmq_params, rabbitmq_queue, data_queue))
app.pika_thread.start()
return jsonify({'status': 'listening'}), 200
else:
return jsonify({'status': 'already listening'}), 200
@app.route('/stoplistening', methods=['GET'])
def stop_listening():
if hasattr(app, 'pika_thread') and app.pika_thread.is_alive():
stop_event.set()
app.pika_thread.join()
del app.pika_thread
return jsonify({'status': 'stopped'}), 200
else:
return jsonify({'status': 'not running'}), 400
@app.route('/startworking', methods=['GET'])
def start_worker():
if len(processes) == 0:
for _ in range(3):
p = multiprocessing.Process(target=worker, args=(data_queue, rabbitmq_params, target_exchange, target_queue, routing_key, pso_params))
p.start()
processes.append(p)
print(f'process id = {p.pid}')
return jsonify({'status': 'started working'}), 200
else:
return jsonify({'status': 'already working'}), 202
@app.route('/stopworking', methods=['GET'])
def stop_worker():
for p in processes:
data_queue.put(None)
for p in processes:
p.join()
processes.clear()
return jsonify({'status': 'stopped working'}), 200
if __name__ == "__main__":
rabbitmq_queue = 'energyStorageStrategy.queue'
target_queue = 'energyStorageStrategy.queue.typc-fpd-tysh'
target_exchange = 'energyStorageStrategy.direct'
routing_key = 'typc-fpd-tysh'
pso_params = {} # 假设你的PSO参数
credentials = pika.PlainCredentials('rabbit', '****') # mq用户名和密码
rabbitmq_params = pika.ConnectionParameters('192.168.*.*', port=5671, virtual_host='/typc-fpd-dev', credentials=credentials)
# 创建一个multiprocessing.Queue用于进程间通信
data_queue = multiprocessing.Queue()
# 创建工作进程列表
processes = []
print(' [*] Waiting for messages. To exit press CTRL+C')
flask_thread = Thread(target=lambda: app.run(host='0.0.0.0', port=5002, debug=True))
flask_thread.start()
start_worker()
start_listening()
3. 代码中问题及其他
3.1. 重新启动侦听线程失败
程序没有报错,但是,没有启动侦听服务线程。
详见后续文章,主题是消息侦听与线程。
3.2. 重新启动工作进行报错
AttributeError: Can’t get attribute ‘worker’ on <module ‘main’ (built-in)>
详见后续文章。
3.3. Flask 应用上下文之外操作问题
问题描述:
site-packages\werkzeug\local.py", line 508, in _get_current_object
raise RuntimeError(unbound_message) from None
RuntimeError: Working outside of application context.
问题解析:
这个错误 RuntimeError: Working outside of application context. 通常发生在 Flask 应用中,当你尝试在 Flask 应用上下文之外执行某些操作时。在 Flask 中,应用上下文是一个用于存储当前应用相关信息的对象,比如配置和 URL 映射。当你调用 jsonify 或其他依赖于应用上下文的函数时,必须确保你处于应用上下文中。
在你的代码中,这个错误很可能是因为 start_listening 函数被设计为在 Flask 路由之外的地方被调用,或者是在 Flask 请求处理流程之外被调用。
解决办法:
with app.app_context():
start_worker()
start_listening()
使用 app.app_context() 来手动创建一个应用上下文。
3.4. Linux环境防火墙
在Linux环境中,别忘了打开防火墙的端口:
root@DeepLearning pvet]# sudo iptables -I INPUT -p tcp --dport 5003 -j ACCEPT
4. 总结
- 模块化:将不同的功能模块化,便于维护和扩展。
- 多进程与多线程结合:使用
multiprocessing实现并行计算任务,使用threading实现RabbitMQ消息侦听和Flask Web服务的非阻塞运行。 - 进程间通信:通过
multiprocessing.Queue实现消息侦听任务与并行计算任务之间的资源交互。 - 事件控制:通过
threading.Event控制消息侦听任务的启停。
这种架构设计能够满足需求,并且具有较好的扩展性和可维护性。如果有更多具体的需求或优化,可以在此基础上进一步完善。
















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











