










在写爬虫的时候遇到需要登录才能访问的网站往往很令人头疼,伪装成浏览器访问神马的也许又会遇到网站采取的加密措施,不胜麻烦!然而,如果换一种思路,先用浏览器登录你想访问的网站,再在浏览器的控制台里找到该网站的cookie,然后利用这个cookie进行带cookie的访问,无疑是短时间内解决此问题的好办法。但是我们都知道cookie的有效期并不长,所以可能第二天你就必须重新查看新的cookie。
下面以登录豆瓣为例。。。
- #coding=gbk
- import urllib2
- HEADERS = {"cookie": ''}#里面写你在www.douban.com的cookie
- url = 'http://www.douban.com/'
- req = urllib2.Request(url, headers=HEADERS)
- text = urllib2.urlopen(req).read()
- if "首页设置".decode("gbk").encode("utf8") in text and "说句话".decode("gbk").encode("utf8") in text:
- print "登陆成功!"
- else:
- print "登录失败!"
关于cookie怎么查看,请看下图:
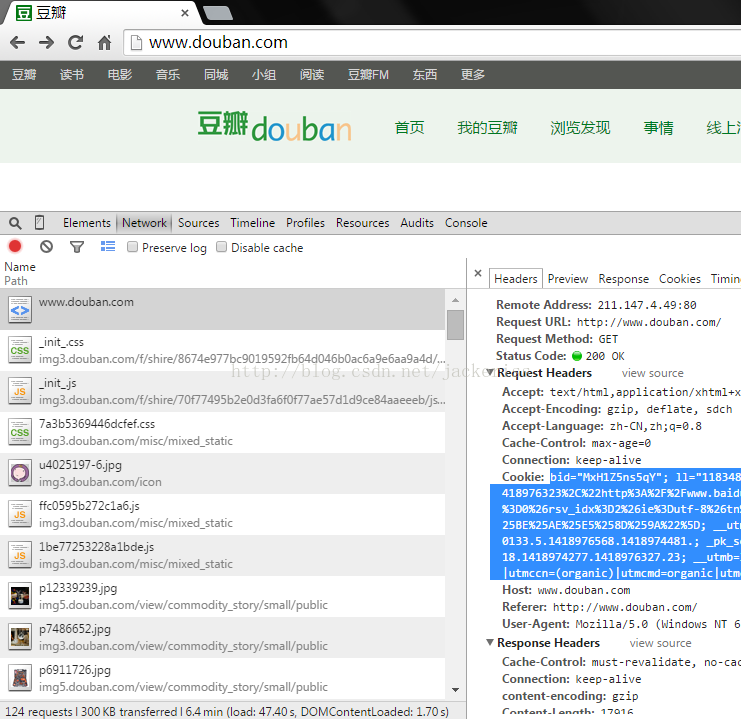
首先登录豆瓣首页,然后按F12调出浏览器的控制台,点击Network这一项。这时候你按F5刷新一下页面,就会发现有好多东西在传来传去的。到最上面找到www.douban.com这一项,会发现里面就有cookie这一项(就是蓝色的我选中的部分,这些信息有些是隐私,绝对不能泄露),将这些复制到你的程序中即可。(我使用的是Chrome浏览器,其他浏览器查看cookie的方式可能都大同小异)















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









