





一. sed命令
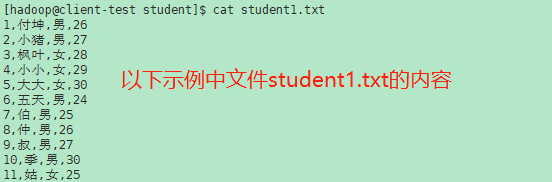
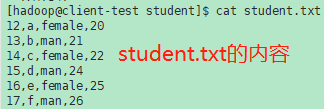
1. Name
sed - 用于过滤和转换文本的流编辑器
2. 简介
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
即,
sed [选项]... command [输入文件]...
3. 描述
Sed是一个流编辑器。流编辑器用于对输入流(文件或管道输入)执行基本的文本转换。虽然在某些方面类似于允许脚本编辑的编辑器(例如ed),但是sed只通过一次传递输入就可以工作,因此更高效。但是sed能够在管道中过滤文本,这是它不同于其他类型编辑器的特别之处。
处理时,把当前处理的行存储在临时缓冲区(并不是hold space)中,称为”模式空间”(pattern space),然后用sed命令处理缓冲区中的内容,处理成后,把缓冲区(即模式空间)的内容送往屏幕显示,同时清空模式空间。接着处理下一行,这样不断重复,直到文件末尾。文件内容没有改改变,除非使用了写入的命令(即-i选项),将内容更新。


定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。
sed 选项:
-n, --quiet, --slient
取消自动打印模式空间。默认是打印的。
-e script, --expression=script
添加script到要执行的命令中
-f script-file, --file=script-file
添加script-file的内容到要执行的命令中
--follow-symlinks
处理就绪时遵循符号链接
-i[SUFFIX], --in-place[=SUFFIX]
就地编辑文件(如果提供后缀,则对原文件进行备份后再进行编辑)。即,-i选项直接修改原文件内容。
示例:


-c, --copy
在 -i 模式下移动(shuffling)文件时,使用复制而不是重命名
-b, --binary
不进行任何操作;为了兼容WIN32/CYGWIN/MSDOS/EMX(以二进制模式打开文件(CR+LFs不作特殊处理))
-l N, --line-length=N
为“l”命令指定所需的换行长度
--posix
禁用所有GUN扩展
-r, --expression-extended
在脚本中使用扩展的正则表达式
-s, -separate
将文件视为单独的,而不是单个连续的长流。
-u, --unbuffered 备注:unbuffered-->无缓冲的
从输入文件中加载最小数量的数据,并更频繁地刷新输出缓冲区
-z, --null-data
使用空字符分割行
如果没有提供 -e、--expression、-f或--file选项,则将第一个非选项参数作为要解释的sed脚本。所有剩余的参数都是输入文件的名称;如果没有指定输入文件,则读取标准输入。
4. 命令简介
这只是sed命令的简要概述,以提醒那些已经了解sed的人;要获得更完整的描述,必须参考其他文档(如texinfo文档)。
- 0个地址的命令(Zero-address ``commands'')
: label
b、 t 和 T 命令的标签
示例:
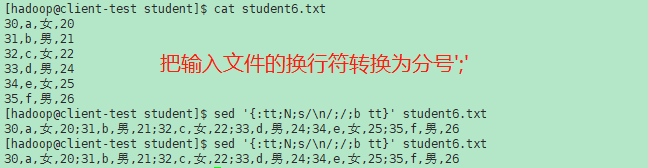
#comment
注释一直扩展到下一行(或 -e 脚本片段的末尾)。
示例:
} {}块的右括号。
- 0个或1个地址的命令(Zero- or One- address commands)
= 打印当前的行号。
示例:

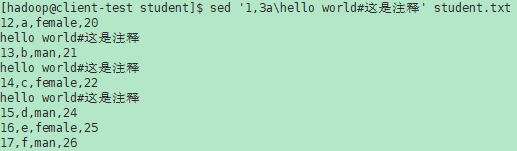
a\ text 在当前行后追加(text)一行或多行。多行时除最后一行外,每行末尾需用“\n”续行。备注:c与\之间可以有空格
示例:
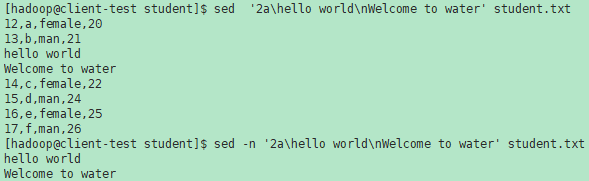
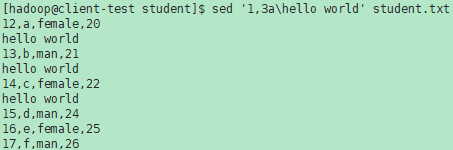
i \ text
在当前行之前插入text。多行时除最后一行外,每行末尾需用"\n"续行。备注:c与\之间可以有空格
示例:


q [exit-code]
立即退出sed脚本,不处理任何其他输入,除非没有禁用自动打印,否则将打印当前模式空间。exit code参数是一个GNU扩展。
示例:

Q [exit-code]
立即退出sed脚本,不处理任何其他输入。
示例:

r filename
追加从filename读取的文本。
示例:


R filename
追加从filename中读取的一行。该命令的每次调用都从文件中读取一行(备注:类似于迭代器)。这是一个GNU扩展。
示例:


- 接受地址范围的命令(Commands which accept address ranges)
{ 以命令块开头(以}结尾)。
示例:

b label
c\ text 用此符号后的text替换当前行中的文本。多行时除最后一行外,每行末尾需用"\"续行。备注:c与\之间可以有空格
示例:

d 删除模式空间,开始下一循环。即,删除(多)行
示例:
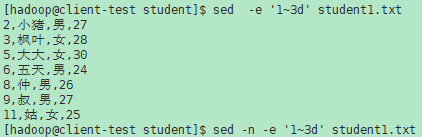
D 如果模式空间不包含换行符,则启动一个正常的新循环,就像发出了d命令一样。否则,删除模式空间中直到第一个换行之前的 文本,然后使用生成的模式空间重新启动循环,而不需要读取新的输入行。
h H 复制/追加模式空间到hold空间。即,把模式空间里的内容复制/追加到hold space
关于pattern space 和hold space的结合使用请参见:https://www.cnblogs.com/LiuYanYGZ/p/9710432.html
g G 把hold space 的内容复制/追加到模式空间,覆盖原有内容/追加到原有内容后面
l 以“视觉上清晰”的形式列出当前行。
l width
以“视觉上清晰”的形式列出当前行,在width字符处断开。这是一个GNU扩展。
n N 读入/追加 输入的下一行到模式空间,并从下一条命令而不是第一条命令开始对其的处理。
p 打印当前的模式空间
P 打印到当前模式空间的第一个内嵌换行
s/regexp/replacement/
尝试根据模式空间匹配regexp。如果成功,将匹配的部分替换为replacement。replacement可能包含特殊字符 & 来引用匹配的模式空间的那一部分,而特殊转义\1到\9来引用regexp中相应的匹配子表达式。
示例:


示例:获取本机ip
![]()
或
![]()
t label
从读取最后一个输入行开始,从最后一个t或t命令开始,如果s///没有成功执行替换,则分支到label;如果省略label,则转移到脚本的末尾。
T label
从读取最后一个输入行开始,从最后一个t或t命令开始,如果s///没有成功执行替换,则分支到label;如果省略label,则转移到脚本的末尾。这是一个GNU扩展。
w filename
把当前模式空间写入filename
示例:

x 交换暂存缓冲区和模式空间中的内容
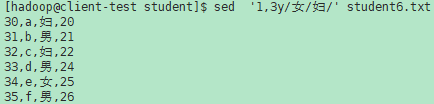
y/source/dest
将source中出现的模式空间中的字符转换为dest中相应的字符。
示例:
5. 地址(Address)
Sed命令可以没有地址,在这种情况下,命令将对所有输入行执行;只有一个地址,在这种情况下,命令只会对匹配该地址的输入行执行;或者使用两个地址,在这种情况下,命令将对所有匹配从第一个地址开始到第二个地址的包含范围的行执行。关于地址范围有三件事需要注意:语法是addr1,addr2(即,地址之间用逗号分隔);addr1匹配的行始终被接受,即使addr2选择较早的行;如果addr2是regexp,它将不会对根据addr1匹配的行进行测试。
在地址(或地址范围)之后,在命令之前,可以插入!,它指定仅当地址(或地址范围)不匹配时才执行该命令。
支持以下地址类型:
number 只匹配指定的行号(除非在命令行上指定了-s选项,否则该行号在文件之间累积递增)。
first~step
从第first行开始匹配步进(step)的每一行。例如,sed -n 1~2p 将打印输入流中的所有奇数行,地址2~5将从第二行开始,每五行匹配一次。first可以是零;在这种情况下,sed的操作方式就像它等于step一样。(这是扩展。)
$ 匹配最后一行
/regrep/
匹配 匹配正则表达式regexp的行。
示例:

\cregexpc
匹配 匹配正则表达式regexp的行,c可以是任何字符。
示例:

GNU sed 还支持一些特殊的2地址格式:
0,addr2
从“匹配的第一个地址”状态开始,直到找到addr2。这类似于1,addr2,除了如果addr2匹配输入的第一行,0,addr2形式将在其范围的末尾,而1,addr2形式仍然在其范围的开头。只有当addr2是正则表达式时,这才有效。
addr1,+N
将匹配addr1和addr1之后的N行。
addr1,~N
将匹配addr1和addr1之后的行,直到下一行(包括此行)的输入行号是N的倍数。
6. REGULAR EXPRESSIONS(正则表达式)
应该支持POSIX.2 BREs,但因为性能问题并不完全支持。正则表达式中的 \n 序列与换行符匹配,\a、\t 和其他序列也是如此。
sed 正则表达式元字符:
| 元字符 | 功 能 |
| ^ | 行首定位符 |
| $ | 行尾定位符 |
| . | 匹配除换行外的单个字符 |
| * | 匹配零个或多个前导字符 |
| [] | 匹配指定字符组内任一字符 |
| .... | 保存已匹配的字符 |
| & | 保存查找串以便在替换串中引用 |
| \< | 词首定位符,即匹配单词的开始 |
| \> | 词尾定位符,即匹配单词的结尾 |
| x\{m\} | 连续 m 个 x |
| x\{m,\} | 至少 m 个 x |
| x\{m,n\} | 至少 m 个 x,但不超过 n 个 x |















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









