







第1章 深入Web请求过程
web2.0网络构架由C/S--B/S
B/S好处:
客户端:统一的浏览器
服务端:基于统一的HTTP
1.1B/S网络构架概述
目前的B/S网络构架:

过程简述:
在浏览器里输入网址,例如www.taobao.com——请求DNS解析对应的IP地址——根据IP地址找到服务器——像服务器发送get请求——服务器返回数据资源给用户。
一些原则:
1.互联网资源都要用URL表示
2.必须基于HTTP与服务器交互
3.数据展示必须在浏览器中进行
1.2如何发起一个请求
发起一个HTTP请求与建立一个Socket连接区别不大,只不过outputStream.write写的二进制字节数据格式要符合HTTP。
有很多现成的工具包可以使用,比如Apache的HttpClient,下面是一个简单的爬虫案例,就用到了HttpClient
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.commons.httpclient.Header;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.PostMethod;
public class RetrivePage {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
// 设置代理服务器的IP地址和端口
httpClient.getHostConfiguration().setProxy("172.17.18.84", 8080);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
InputStream input = null;
OutputStream output = null;
// 得到post方法
PostMethod postMethod = new PostMethod(path);
// 设置post方法的参数
/*
* NameValuePair[] postData = new NameValuePair[2]; postData[0] = new
* NameValuePair("name","lietu"); postData[1] = new
* NameValuePair("password","*****");
* postMethod.addParameters(postData);
*/
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
input = postMethod.getResponseBodyAsStream();
//得到文件名
String filename = path.substring(path.lastIndexOf('/')+1);
//获得文件输出流
output = new FileOutputStream(filename);
//输出到文件
int tempByte = -1;
while((tempByte=input.read())>0){
output.write(tempByte);
}
//关闭输入输出流
if(input!=null){
input.close();
}
if(output!=null){
output.close();
}
return true;
}
//若需要转向,则进行转向操作
if ((statusCode == HttpStatus.SC_MOVED_TEMPORARILY) || (statusCode == HttpStatus.SC_MOVED_PERMANENTLY) || (statusCode == HttpStatus.SC_SEE_OTHER) || (statusCode == HttpStatus.SC_TEMPORARY_REDIRECT)) {
//读取新的URL地址
Header header = postMethod.getResponseHeader("location");
if(header!=null){
String newUrl = header.getValue();
if(newUrl==null||newUrl.equals("")){
newUrl="/";
//使用post转向
PostMethod redirect = new PostMethod(newUrl);
//发送请求,做进一步处理。。。。。
}
}
}
return false;
}
/**
* 测试代码
*/
public static void main(String[] args) {
// 抓取lietu首页,输出
try {
RetrivePage.downloadPage("http://www.lietu.com");
} catch (HttpException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Linux中的curl命令也可以发起HTTP请求
1.3HTTP解析
B/S核心——HTTP
HTTP核心——HTTP Header
常见HTTP请求头:
| 请求头 | 说明 |
| Accept-Charset | 用于指定客户端接受的字符集 |
| Accept-Encoding | 用于指定可接受的内容编码,如Accept-Encoding:gzip.deflate |
| Accept-Language | 用于指定一种自然语言,如Accept-Language:zh-cn |
| Host | 用于指定被请求资源的Internet主机和端口号,如Host:www.taobao.com |
| User-Agent | 客户端将它的操作系统、浏览器和其他属性告诉服务器 |
| Connection | 当前连接是否保持,如Connection:Keep-Alive |
常见的HTTP响应头:
| 响应头 | 说明 |
| Server | 使用的服务器名称,如Server:Apache/1.3.4(Unix) |
| Content-Type | 用来指定发送给接收者的实体正文媒体类型,如Content-Type:text/html;charset=GBK |
| Content-Encoding | 与请求包头Accept-Encoding对应,告诉浏览器服务器端采用什么压缩编码 |
| Content-Language | 描述了资源所用的自然语言,与Accept-Language对应 |
| Content-Length | 说明实体正文长度,用以字节方式存储的十进制数字表示 |
| Keep-Alive | 保持连接世界,如Keep-Alive:timeout=5,max=120 |
常见的HTTP状态码
| 状态码 | 说明 |
| 200 | 客户端请求成功 |
| 302 | 临时跳转,跳转的地址通过Location指定 |
| 400 | 客户端请求有语法错误,不能被服务器识别 |
| 403 | 服务器接收到请求,但是拒绝提供服务 |
| 404 | 请求资源不存在 |
| 500 | 服务器发生不可预期的错误 |
1.3.1查看HTTP信息的工具
FireFox:firebug,httpfox
chrom:F12
IE:F12.httpFox的IE版
1.3.2浏览器缓存机制
Ctrl+F5:刷新,浏览器向服务器发送新的请求,而不是使用本地的缓存
这时,有可能会在请求头增加如下几种字段
1.Pragma/Cache-Control
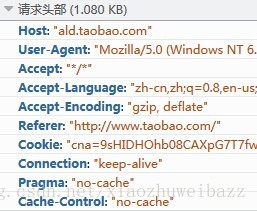
这两个字段的可选值如下
| 可选值 | 说明 |
| Public | 所有内容都被缓存,在响应头设置 |
| Private | 内容只缓存到私有缓存中,在响应头设置 |
| no-cache | 所有内容都不缓存,在请求头和响应头设置 |
| no-store | 所有内容都不会被缓存到缓存或者Internet临时文件,在响应头中设置 |
| must-revalidation/proxy-revalidation | 如果缓存的内容失效,请求必须发送到服务器/代理以进行重新验证,在请求头中设置 |
| max-age=xxx | 缓存的内容在xxx秒后失效,这个选项只有HTTP1.1可用,和Last-Modified一起使用时,优先级较高,在响应头中设置 |
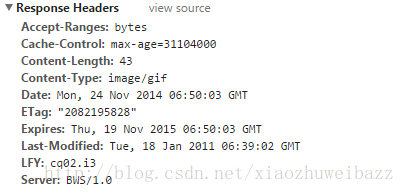
2.Expires
通常的使用格式为Expires:Sat,25 Feb 2014 14:35:12 GMT
超过这个时间后,缓存的内容将失效,浏览器在发送请求前,检查这个页面的该字段,查看页面是否过期,是否用重新像浏览器发送请求
3.Last-Modified/Etag
用于表示一个服务器上的资源的最后修改时间,资源可以是静态的(资源内容加上Last-Modified字段)或动态的(有方法可以检查某个动态内容是否已经更新,如Servlet的getLastModified),通过这个最后修改时间,判断请求的资源是否是最新的
一般响应头会返回该字段如Last-Modified:Sat,25 Feb 2014 14:35:12 GMT。浏览器再次请求时,请求头会有该字段Last-Modified:Sat,25 Feb 2014 14:35:12 GMT,从而询问服务器当前缓存的页面是否为最新,是的话返回304,告诉浏览器是最新的,服务器就不传输新数据了。
功能类似的还有Etag字段,该字段的作用是服务端为每个页面分配一个唯一的编号,通过这个编号来区分当前页面是否是最新的。
http协议相关博文:
HTTP详解(1)-工作原理
HTTP详解(2)-请求、响应、缓存
HTTP详解(3)-http1.0 和http1.1 区别
网站优化--让你的网页飞起来
让网站飞起来01---浏览器缓存技术
让网站飞起来02--服务器缓存技术
1.4DNS域名解析
1.4.1DNS域名解析过程
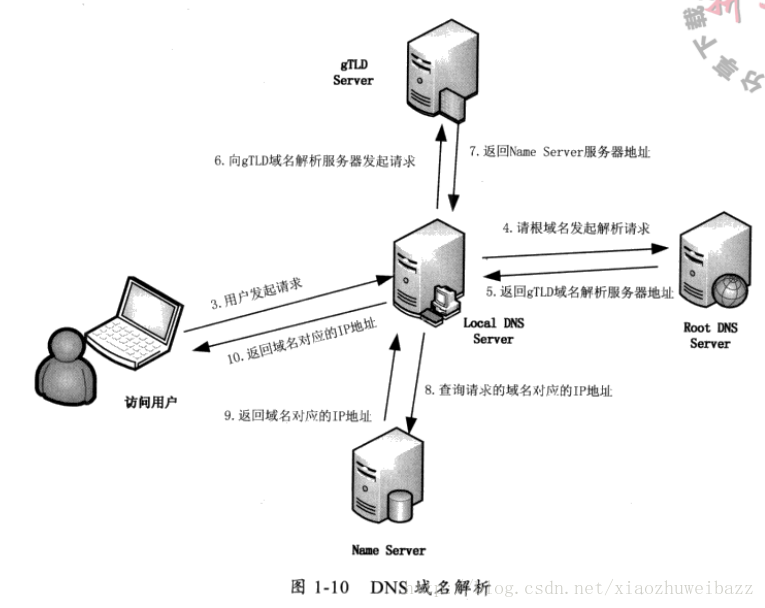
DNS解析过程:
1.用户在浏览器输入域名,浏览器首先检查自己的缓存中有没有这个域名对应的IP地址,有则DNS解析结束,无则继续
2.浏览器查找操作系统缓存中是否有这个域名对应的DNS解析结果。(在Windows下\etc\hosts文件就存储着域名对照表,所谓的域名劫持就是修改这个文件,指定某个域名对应的IP地址。Windows7以后这个文件为只读的。)有则DNS解析结束,无则继续
3.SPA通常会提供本地域名解析服务器,用户请求本地域名解析服务器LDNS解析,有则结束,无则继续
4.LDNS向Root Server域名服务器请求
5.Root Server返回给LDNS一个主域名服务器(gTLD)
6.LDNS根据上一步得到的gTLD,去请求gTLD
7.gTLD返回此域名对应的Name Server域名服务器地址(Name Server通常是该域名的注册商所提供的)
8.Name Server查询存储的域名和IP映射关系表,将IP与TTL值返回给LDNS
9.LDNS返回IP和TTL给用户,并缓存这个结果
10.用户根据TTL将IP缓存到本地
1.4.2跟踪域名解析过程
在Linux和Windows下可以通过命令nslookup来查询域名的解析结果
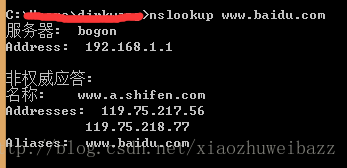
Linux下还可以使用dig命令查询DNS解析过程
1.4.3清楚缓存的域名
Windows下通过
ipconfig/flushdns清除
Linux下通过
/etc/init.d/nscd restart清除
java中JVM也会缓存DNS结果,在InetAddress类中完成,有两种策略
在%JAVA_HOME%\lib\security\java.security文件中配置
正确的解析结果:配置项为networkaddress.cache.ttl = -1(永不失效)
错误的解析结果:配置项为networkaddress.cache.negative.ttl = 10(缓存10秒)
修改方式:
1.直接修改上述文件
2.在java的启动参数中增加-Dsun.net.inetaddr.ttl = xxx来修改默认值
3.通过InetAddress类动态修改
注:InetAddress解析域名,必须是单例模式
1.4.4几种域名解析方式
A记录:用来指定一个IP地址的域名,可以将多个域名解析到一个IP地址
CNAME记录:别名解析,为一个域名再起其他的别名,实际上他们指向同一个IP
MX记录:将某个域名下的邮件服务器指向自己的Mail Server,如abc.com域名A记录的IP地址是114.231.11.33,如果将MX记录设置为114.231.11.33,DNS机会将发送给xxx@abc.com的邮件发送给114.231.11.33所在的服务器。
NS记录:为某个域名指定DNS解析服务器
TXT记录:设置的说明
1.5CDN工作机制
CDN:内容分布网络
将网站的内容发布到最接近用户的网络边缘,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。
CDN=镜像+缓存+整体负载均衡
目前CDN以缓存网站中静态数据为主,用户从主网站服务器请求到动态内容后,再从CDN上下载这些静态数据,从而加速
1.5.1CDN构架
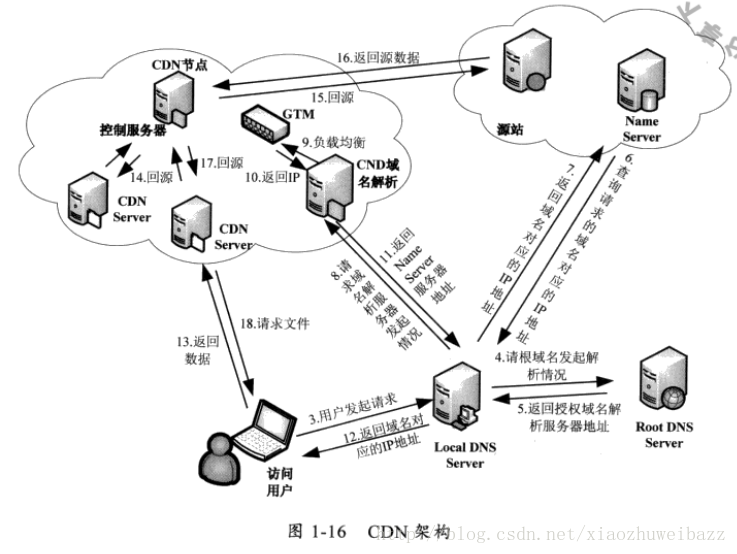
如图用户访问静态资源,加入这个静态资源的域名是abc.taobaqo.com,那么首先域名解析,指定到CDN全局中DNS负载均衡服务器,再由这个负载均衡服务器分配给用户距离他最近的CDN结点。用户会去这个CDN结点获取静态资源。
1.5.2负载均衡
负载均衡是由多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等价的地位,都可以单独对外提供服
务而无须其他服务器的辅助。通过某种负载分担技术,将外部发送来的请求均匀分配到对称结构中的某一台服务器上
,而接收到请求的服务器独立地回应客户的请求。均衡负载能够平均分配客户请求到服务器列阵,籍此提供快速获取
重要数据,解决大量并发访问服务问题。这种群集技术可以用最少的投资获得接近于大型主机的性能。
分为:链路负载均衡:
集群负载均衡
操作系统负载均衡
1.5.3CDN动态加速
CDN的DNS解析中通过动态的链路探测来寻找回源最好的一条路径,然后通过DNS的调度将所有请求调度到选定的这条路径上回源。
1.6总结
大致的介绍,具体细节需再查阅相关文献,关键是了解流程














 1982
1982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









