






刚才写了半天的文章,因为不小心点了舍弃,一切都要重来。怪自己不小心,不过这CSDN的自动保存功能做的有点弱。
迅速进入正题。这些天在研究CRF的东西,由于之前对机器学习的方面接触比较少,看CRF比较费力,现在把看到的一些想法分享出来,理解不到位的地方希望大牛过来指点指点。
一、CRF的概念和原理
参考《条件随机场理论综述》(韩冬雪、周彩根),这篇文章里面对CRF的基本理论都做了介绍,主要包括了以下一些问题。
1.离散马尔科夫过程,即当前所处的状态仅与它之前的一条状态有关。
2.隐马尔科夫五个要素:N、M、A、B、PI。一个完整的马尔科夫模型要求两个具体的模型参数N和M,三个概率矩阵A、B、PI。
3.隐性马尔科夫模型的三个基本问题:
1)给定一个模型λ =(N、M、A、B、PI),如何高效的计算某一输出字符序列O=O1O2O3…Ot的概率P(O|λ)。可以采用forward-backward算法,迭代求出alpha和beta,然后求得P(O|λ)(公式9)。
2)给定一个模型λ =(N、M、A、B、PI)和一个输出字符O=O1O2O3…Ot,如何找到产生这一序列的最大状态序列Q。这个可以通过viterbi算法来求解。
3)给定一个模型λ =(N、M、A、B、PI)和一个输出字符O=O1O2O3…Ot,如何调整模型的参数使得产生这一序列的的概率最大。这个可以通过参数估计来计算。
4.最大熵模型:最大熵模型的实质是,在已知部分知识的前提下,关于未知分布最合理的推断是符合已知知识的最不确定或最随机的推断,这是我们可以做出的唯一一个不偏不倚的选择。
1)最大熵模型的约束条件,即经验期望等于模型期望(公式22)。
2)根据最大熵模型构造关于p和λ 的拉格朗日函数,求得p(公式29)以及模型估计的经验分布p的对数似然(公式34)。
5.条件随机场
1)根据Hammersley-Clifford定理和最大熵模型,可以得到条件随机场的联合概率公式(公式37,39)。λ 为特征权重,f为特征函数。
2)根据对数似然函数,可以得到(公式49),求偏导数得到(公式52)。
3)由于学习过度的问题,引入了罚函数,形成(公式53和54)。但54中p不好计算,所以采用矩阵的形式来计算。p的计算(公式61)包括了上面提到的alpha 和 beta。
我的理解是,上面的整个过程都是为了求得目标函数(49),偏导数(52),然后设定初始的λ ,放到参数优化函数中去优化,求得最佳的λ 。
二、CRF++程序
1.这个程序的总体流程可以用下面这张图来表示,包括学习和解码两个过程。学习的过程会产生特征、特征权重,编码的过程是利用这些特征权重来标记待标记的字符序列。
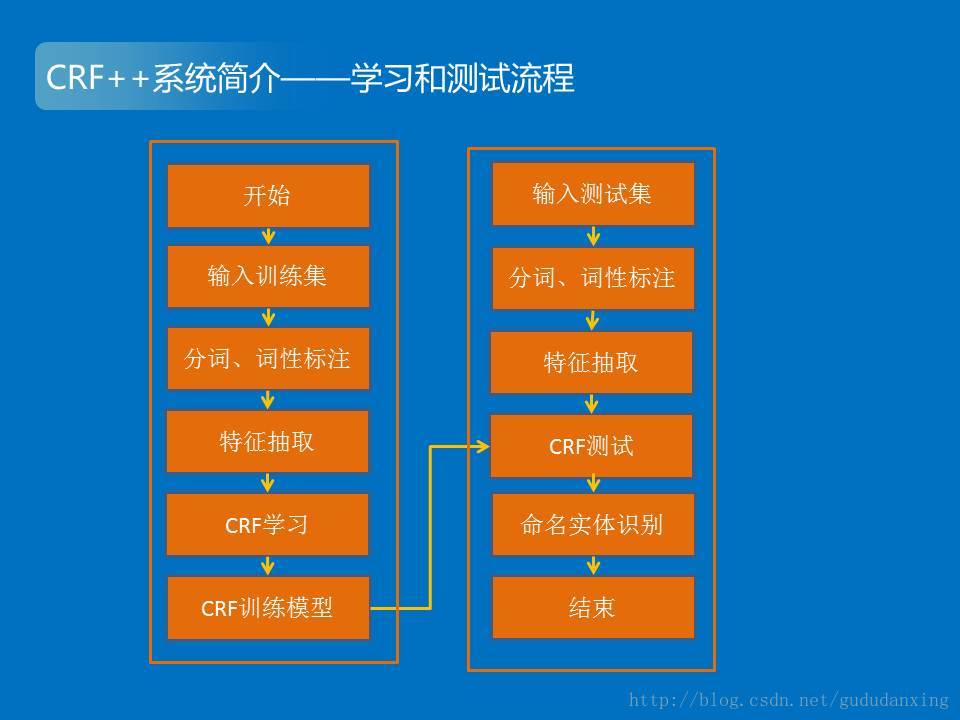
2.学习过程的基本过程如下图
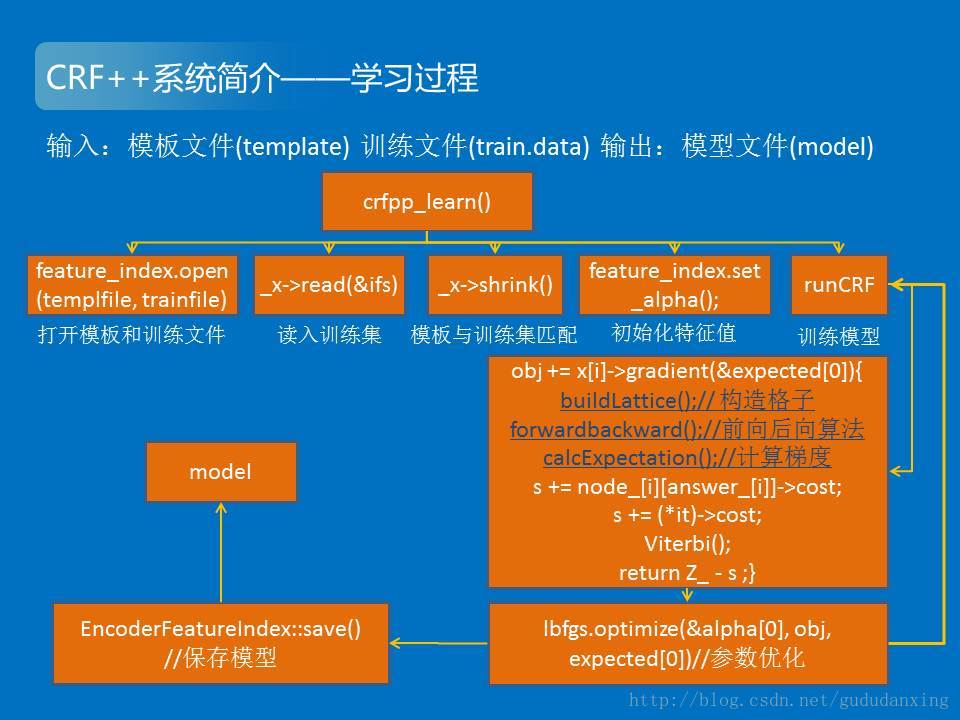
1)feature_index.open函数用来打开模板和训练文件。shrink()用来形成模板和训练集的匹配。
程序中,对于训练集中的每个单词都包括三个标记符号(B I O ),并且每个单词都会和模板文件中的20个模板相结合,因此形成60个特征。特征的格式为:
(“特征”,(特征序号,特征出现次数))。
关于conference和in两个单词的匹配结果如下:
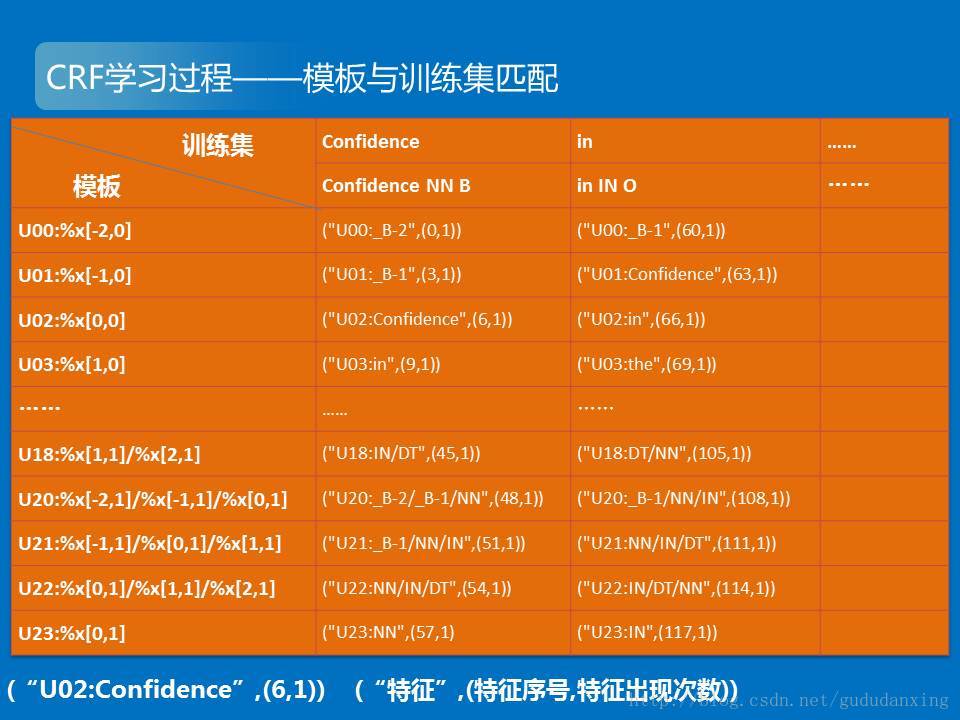
然后进行CRF算法。下面这些解释来自于:http://blog.sina.com.cn/s/blog_5980285201018ijz.html
2)其中的重点是obj += x[i]->gradient(&expected[0])函数。首先使用buildLattice()函数来构造格子。同时求得每个节点的cost的值,这里的求解过程calcCost()和(公式55)相对应。
3)forward-backward算法。calcAlpha, calcBeta和(公式59,60)相对应。
4)expectation与论文中(公式61)相对应。(公式52)来计算梯度,公式中的第一项已经在代码的calcExpectation中加上去了
公式中的第二项体现在gradient函数中的两个地方:
--expected[*f + answer_[i]]; //对应于unigram
--expected[*f +(*it)->lnode->y * ysize_ +(*it)->rnode->y]; //对应于bigram
5)接下来调用viterbi函数。
6)Z_-S与(公式49)相对应。这里和expected的计算,我还不是很明白。根据后面对罚函数的计算,这里的Z和S应该正好和论文公式中的前后相是颠倒的。
7)计算完这些之后,程序中还有关于罚函数的计算。整个计算完之后吧obj,expected,alpha(也就是λ)带入到LBFGS中去优化。通过迭代计算最后获得model文件。
8)model文件中主要包括了模板文件、所有的特征、所有特征的权重等信息。至此,学习算法结束。
3.CRF++解码过程。
解码过程是从mode读取模板、特征和特赠权重(λ),然后根据对每个解码文件中的单词构建lattice,求得cost,然后再利用viterbi算法来求得最佳路劲。
关于解码过程http://www.52nlp.cn 中的“初学者报道3-crf-中文分词解码过程理解”有形象的解释。
文章就写到这里吧。关于文章的PPT和资料可以在这里下载:http://pan.baidu.com/share/link?shareid=1886870677&uk=654680323















 5827
5827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









