







summary
-
消息中间件作用:-
-
消息幂等性 -
-
三高一(高可用、高性能、高并发、一致性)
- rabbitMQ:主从模式下,使用镜像复制,让每个节点都有全量数据
- kafka:副本,ack
-
如何保证消息有序
-
如何保证消息不丢不乱不重不堆积,丢乱重堆
-
队列分类 -
-
不同消息中间件优缺点
消息中间件作用
-
- 解耦
- 削峰
- 异步通信
- 冗余(存储)
- 扩展性
- 可恢复性
- 顺序保证
- 缓冲
消息幂等性 -
对于确保消息在生产者和消费者之间进行传输而言一般有三种传输保障(delivery guarantee)
- At most once,至多一次,消息可能丢失,但绝不会重复传输;
- At least once,至少一次,消息绝不会丢,但是可能会重复;
- Exactly once,精确一次,每条消息肯定会被传输一次且仅一次。对于大多数消息中间件而言,一般只提供At most once和At least once两种传输保障,对于第三种一般很难做到,由此消息幂等性也很难保证。
Kafka自0.11版本开始引入了幂等性和事务,Kafka的幂等性是指单个生产者对于单分区单会话的幂等,而事务可以保证原子性地写入到多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚,这两个功能加起来可以让Kafka具备EOS(Exactly Once Semantic)的能力
如何保证高可用
rabbitMQ
主从模式下,使用镜像复制,让每个节点都有全量数据
kafka
副本,ack
其他
对账机制保证
如何保证消息有序 -
有序性分:全局有序和部分有序。
全局有序
如果要保证消息的全局有序,首先只能由一个生产者往Topic发送消息,并且一个Topic内部只能有一个队列(分区)。消费者也必须是单线程消费这个队列。这样的消息就是全局有序的!
不过一般情况下我们都不需要全局有序,即使是同步MySQL Binlog也只需要保证单表消息有序即可。

部分有序
因此绝大部分的有序需求是部分有序,部分有序我们就可以将Topic内部划分成我们需要的队列数,把消息通过特定的策略发往固定的队列中,然后每个队列对应一个单线程处理的消费者。这样即完成了部分有序的需求,又可以通过队列数量的并发来提高消息处理效率。
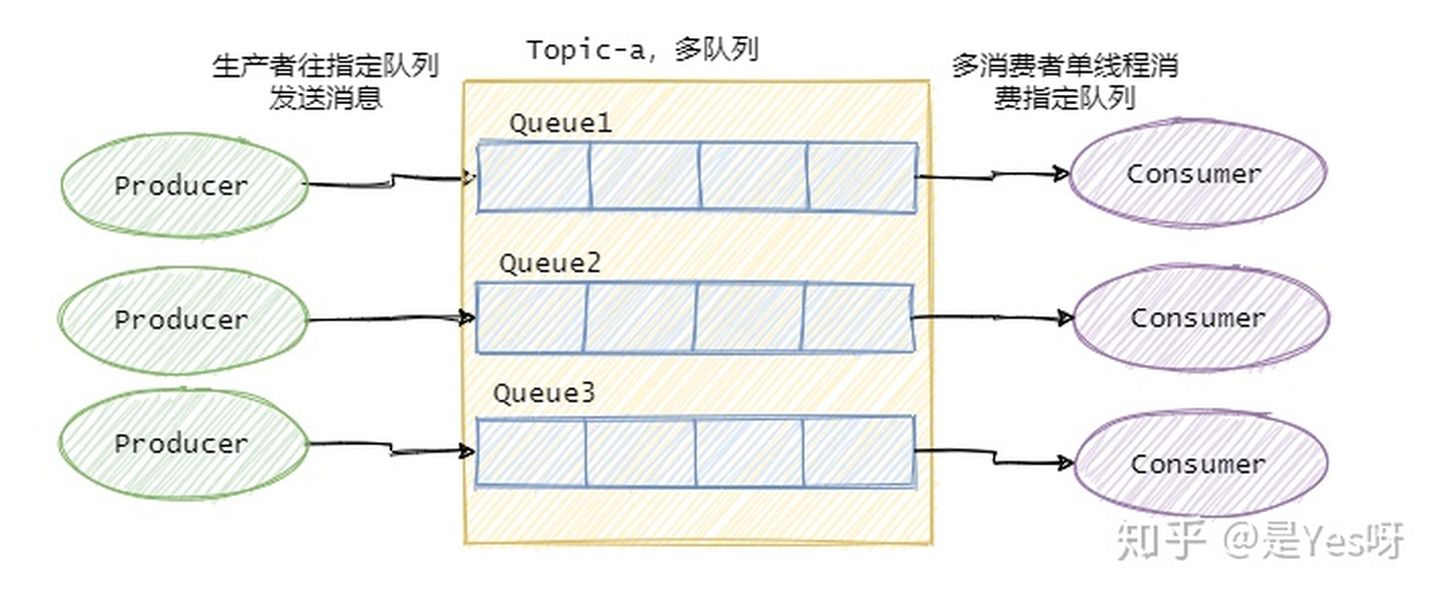
图中我画了多个生产者,一个生产者也可以,只要同类消息发往指定的队列即可
kafka如何保证消息有序
- Kafka 中发送1条消息的时候,可以指定(topic, partition, key) 3个参数。partiton 和 key 是可选的
- 如果你指定了 partition,那就是所有消息发往同1个 partition,就是有序的
- 并且在消费端,Kafka 保证,1个 partition 只能被1个 consumer 消费。或者你指定 key(比如 order id),具有同1个 key 的所有消息,会发往同1个 partition。也是有序的
队列分类 -
- 优先级队列
优先级队列不同于先进先出队列,优先级高的消息具备优先被消费的特权,这样可以为下游提供不同消息级别的保证。不过这个优先级也是需要有一个前提的:如果消费者的消费速度大于生产者的速度,并且消息中间件服务器(一般简单的称之为Broker)中没有消息堆积,那么对于发送的消息设置优先级也就没有什么实质性的意义了,因为生产者刚发送完一条消息就被消费者消费了,那么就相当于Broker中至多只有一条消息,对于单条消息来说优先级是没有什么意义的。
- 延迟队列
当你在网上购物的时候是否会遇到这样的提示:“三十分钟之内未付款,订单自动取消”?这个是延迟队列的一种典型应用场景。延迟队列存储的是对应的延迟消息,所谓“延迟消息”是指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。延迟队列一般分为两种:基于消息的延迟和基于队列的延迟。基于消息的延迟是指为每条消息设置不同的延迟时间,那么每当队列中有新消息进入的时候就会重新根据延迟时间排序,当然这也会对性能造成极大的影响。实际应用中大多采用基于队列的延迟,设置不同延迟级别的队列,比如5s、10s、30s、1min、5mins、10mins等,每个队列中消息的延迟时间都是相同的,这样免去了延迟排序所要承受的性能之苦,通过一定的扫描策略(比如定时)即可投递超时的消息。
由于某些原因消息无法被正确的投递,为了确保消息不会被无故的丢弃,一般将其置于一个特殊角色的队列,这个队列一般称之为死信队列。与此对应的还有一个“回退队列”的概念,试想如果消费者在消费时发生了异常,那么就不会对这一次消费进行确认(Ack),进而发生回滚消息的操作之后消息始终会放在队列的顶部,然后不断被处理和回滚,导致队列陷入死循环。为了解决这个问题,可以为每个队列设置一个回退队列,它和死信队列都是为异常的处理提供的一种机制保障。实际情况下,回退队列的角色可以由死信队列和重试队列来扮演。
- 重试队列
重试队列其实可以看成是一种回退队列,具体指消费端消费消息失败时,为防止消息无故丢失而重新将消息回滚到Broker中。与回退队列不同的是重试队列一般分成多个重试等级,每个重试等级一般也会设置重新投递延时,重试次数越多投递延时就越大。举个例子:消息第一次消费失败入重试队列Q1,Q1的重新投递延迟为5s,在5s过后重新投递该消息;如果消息再次消费失败则入重试队列Q2,Q2的重新投递延迟为10s,在10s过后再次投递该消息。以此类推,重试越多次重新投递的时间就越久,为此需要设置一个上限,超过投递次数就入死信队列。重试队列与延迟队列有相同的地方,都是需要设置延迟级别,它们彼此的区别是:延迟队列动作由内部触发,重试队列动作由外部消费端触发;延迟队列作用一次,而重试队列的作用范围会向后传递。
ActiveMQ、RabbitMQ、Kafka、RocketMQ 有什么优缺点?
ARKR
-
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 适用场景 | 最早,现在基本不用 | erlang 语言,中小型公司适用 | 大数据领域的实时计算、日志采集 | 大公司适用 |
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同ActiveMQ | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 | 10 万级,支撑高吞吐 |
| topic 数量对吞吐量的影响 | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | 延迟在 ms 级以内 | ms 级 |
| 可用性 | 高,基于主从架构实现高可用 | 高,主从 | 非常高,分布式 | 非常高,分布式 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 同 RocketMQ | 经过参数优化配置,可以做到 0 丢失 |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 | MQ 功能较为完善,还是分布式的,扩展性好 |
常见的几种分布式消息系统的对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OpXz6m7d-1622188450548)(https://segmentfault.com/img/remote/1460000037455378)]
消息丢失
消息














 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









