







从我前几天写的 python 基于次世代验证码识别系统的小demo 中大家可以得知,如果有antiVC.dll 和关于特定网站的字符库cds,我们就能够让浏览器自动识别验证码了。虽然网络有不少视频关于怎么训练cds,我还是总结下吧,哎,备忘。
自己训练数据相对于去购买什么超级鹰API啊,de-captcher啊这种验证码识别平台,有2个好处,一是不用考虑网络延迟,二是API都是收费的,小弟我也是Naive得贡献了10几刀的,╮(╯▽╰)╭
这里可以贡献下怎么用de-captcher的验证平台(前提是你先注册了de-captcher用户并且购买了次数):
#验证码在线验证
def getTextFromImg(img_file):
data = {
'username': 'your_user',
'password': 'your_pass',
'function': 'picture2',
'pict_to': '0',
'pict_type': '0',
'pict': img_file
}
keys = 'ResultCode|MajorID|MinorID|Type|Timeout|Text'.split('|')
de_captcher_server = "http://poster.de-captcher.com/"
try:
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
result = opener.open(de_captcher_server, urllib.urlencode(data))
data = result.read()
#print 'check_code:',data
return dict(zip(keys, data.split('|')))
except KeyError,e:
print str(e)
return result目标:http://jiaowu.dlufl.edu.cn/
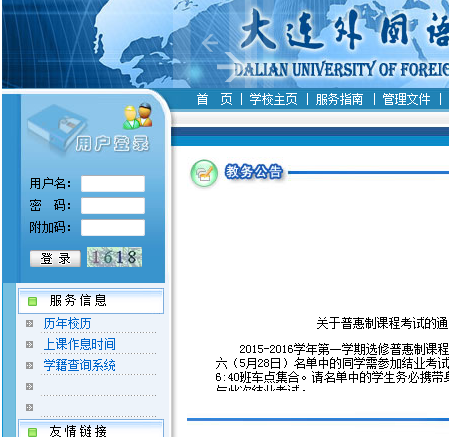
可以发现它的验证码地址是我们最喜欢的固定URL,每次F5都是新的验证码。
有些网站验证码动态URL,而且还是JS生成,我们需要JS解析器。
那个要自己写脚本跑,思路有两种:
一是浏览器截图,可参考我之前写的:Pyqt 浏览器截图小demo
二是通过selenium+PhantomJS,动态解析页面源代码下载下来,获取URL后通过访问下载图片,可参考我之前写的:selenium 操控浏览器
有些同学可能发现了,方法二得到的验证码是不同于第一次获得的验证码,毕竟每次访问都会更新,又有什么关系呢?
我们只要获得验证码图片用来训练就行了。
总之上面的情况暂时不考虑,我们现在遇到的是最简单的情况,同一URL可获取不同的验证码:

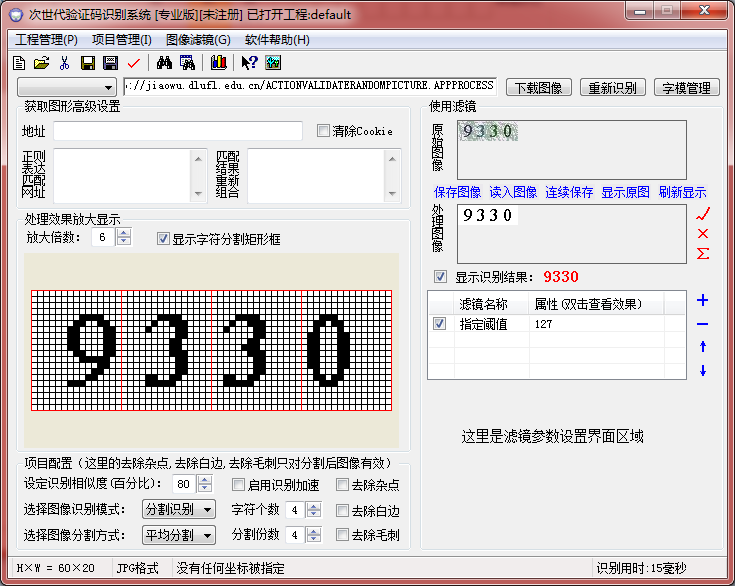
OK,打开次世代2.3,在地址栏输入:http://jiaowu.dlufl.edu.cn/ACTIONVALIDATERANDOMPICTURE.APPPROCESS,点击下载图像:
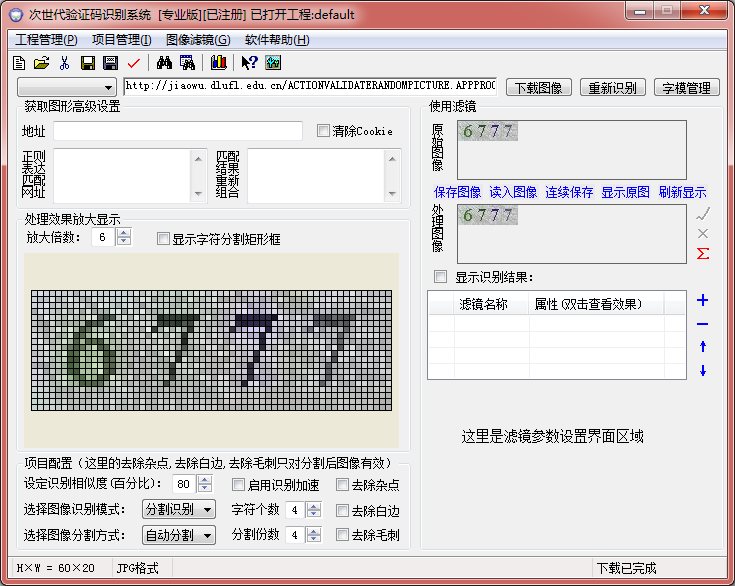
然后依次选择:分割识别、平均分割(因为看起来四四方方的很规整)、显示字符分割矩形框、显示识别结果、点击最右边的加号选择图像二值化:
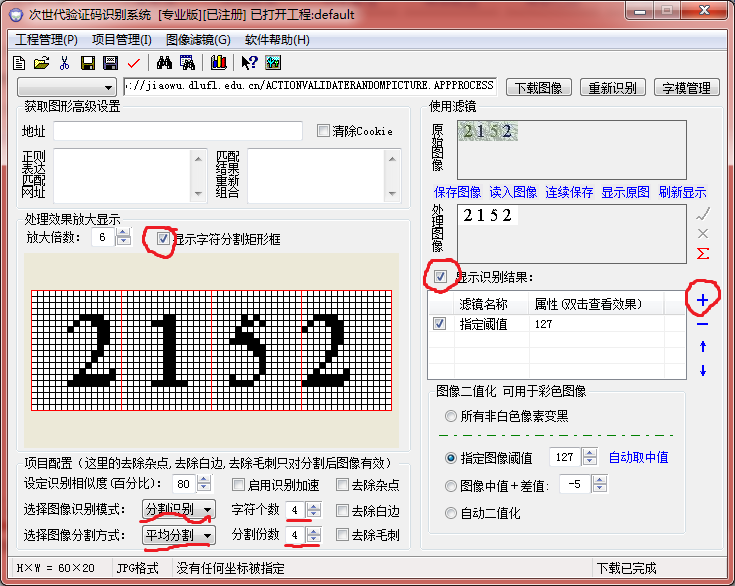
再点击字模管理,选中自动分割图像:
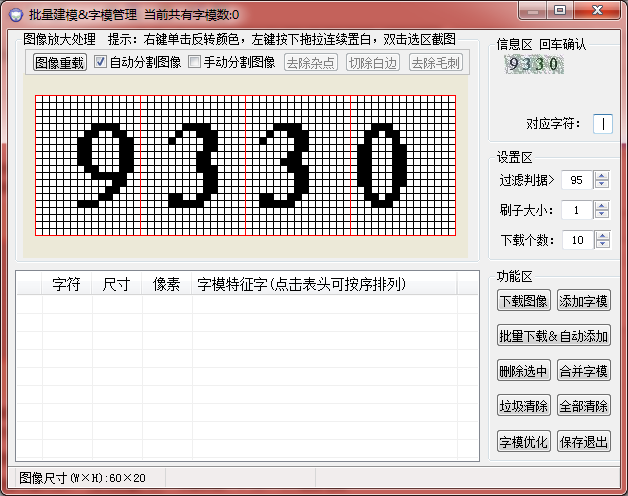
双击第一个矩形“9”:
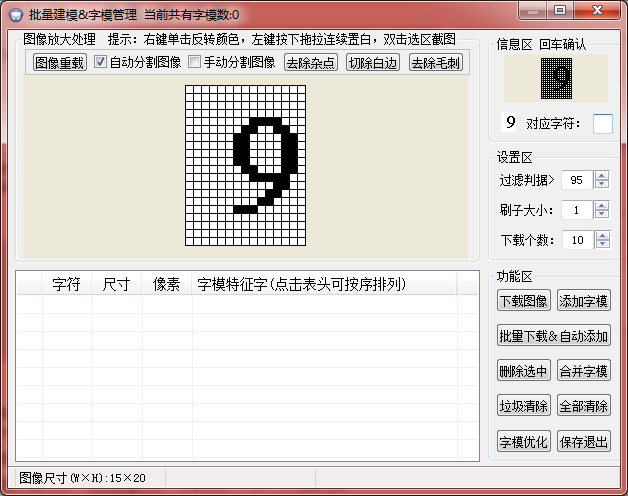
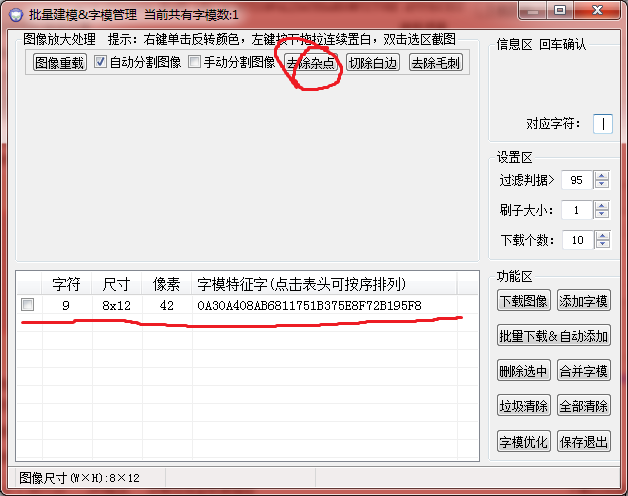
选择切除白边(有些杂点多的还要去除杂点),然后在右边对应字符填下:9,告诉程序,以后遇见这种字符它就是9:
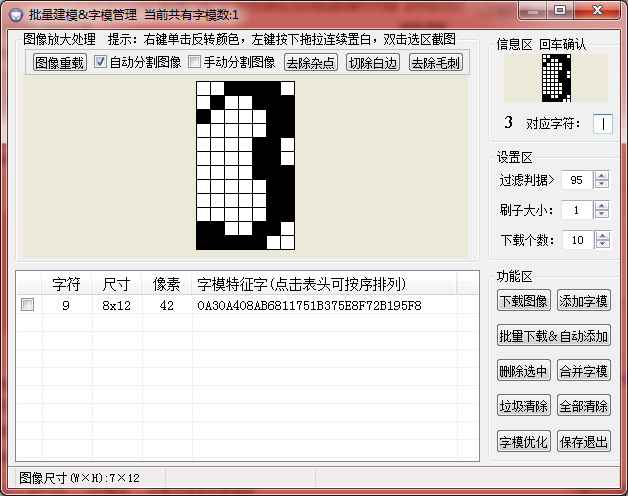
弄完一个后点击“图像重载”,对第二个矩形3,做同样的操作:
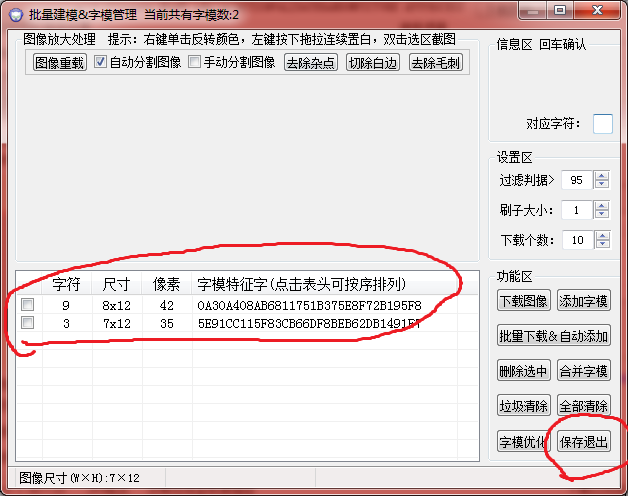
填入3后,我们可以看到已经有两个字模了,弄完这些就可以保存退出:
好的回到主界面,我们点击重新识别,可以看到喜人的结果:
好的,当你识别率很高很高的时候,点击项目管理,发布识别库,就能生存可爱的专属的cds啦,不过正版软件每次25软妹币,你舍得吗?
吐槽下:
这基本上是我遇到的最最简单的字模创建了,没任何杂点,验证码超级规整,和我攻克的网站一比较就是被吊打的存在。。
有些难的,2000个字模以下别想识别成功,2k个啊有木有!!
要做足足两天啊有木有!!!
难怪淘宝特定网站cds售价都是2k,3k软妹币啊有木有!!!
不是人干得的啊有木有!!!
而且你还以为有些网站验证码这么容易获得吗?还不是一个个用脚本去跑的啊有木有!!















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









