







Efficient semantic image segmentation with superpixel pooling
摘要
在这项工作中,我们评估了超像素池化层在深层网络结构中用于语义分割的应用。超像素池化是一种灵活有效的方法,可以替代其他包含空z间先验信息的池策略。我们提出了一个简单而高效的gpu层实现,并探讨了几种将该层集成到现有网络架构中的设计。我们在IBSR和Cityscapes数据集上提供了实验结果,表明可以利用超像素池化以最小的计算开销持续提高网络精度。源代码可从https://github.com/bermanmaxim/superpixPool获得。
1. 介绍
超像素是一种将空间先验与各种计算机视觉问题相结合的常用方法。这不仅影响结果统计模型偏向于空间平滑性,而且由于计算的原因。例如,对于基于图割的推理,超像素被广泛应用于减少立方倍最坏情况下的计算成本。随着深度神经网络在分类、分割和许多其他视觉任务上的普及,它们在某种程度上已经失宠。然而,超像素的统计和计算优势也可以应用于深层网络。
其中一个关键原因是,为计算机视觉任务设计的深度神经网络在过去几年变得越来越深、越来越复杂。虽然这可以提高对各种问题的准确性,但通常也会增加计算成本。因此,我们的目标是通过简化分割问题来提高网络的准确性,而不是建立更复杂的模型。我们建议通过一个超像素池化层来实现这一点。这样的层有两个主要好处:信息分组和对分割输出引入先验信息。此先验有助于分割由于超像素可以保留边缘信息。然而,信息分组和边缘保留是相互冲突的目标,因为较大的超像素包含更多的信息,但通常不会像较小的超像素那样遵守边界。在我们的实验中,我们试图深入了解这种权衡,看看它如何影响不同类型网络的分割精度。
我们通常用超像素这个词来表示二维图像分割,用超体素来表示立方图像分割。我们首先描述了超像素池化层,并提出了一个简单但有效的gpu实现用于前向和后向传递。然后,我们提出了几种将该层集成到现有CNN架构中的方法。最后,我们使用VoxResNet[2]和ENet[8]体系结构对这些修改进行了经验评估。
2. 相关工作
近年来,各种超像素分割算法相继问世。最近的一项基准测试研究[11]根据高级方法对24种最先进的方法进行了分类,并构建了算法的总体排名。这个基准测试中性能最好的候选项是高效拓扑保持分割(ETPS)[14]和通过能量驱动采样提取超像素(SEEDS)[12]。紧随其后的可能是最流行的超像素算法简单线性迭代聚类(SLIC)[1]。除了它的整体分割精度可以与SEEDS和ETPS拼一拼之外, SLIC有几个额外的好处。这包括它的简单性、对立体图像的原生支持以及它的并行性。后者导致了gSLICr[9],一个gpu实现的SLIC算法。这样的实现允许以最小的时间成本为网络提供超像素。我们在下面的实验中使用的第一个网络架构称为VoxResNet[2]。这是一个残差神经网络[4],旨在直接处理体积图像,并在MRI脑扫描解剖区域的分割方面达到了最先进的性能。我们使用这个网络和两个简化的变体来测试超体素池层在立体图像分割中的有效性。第二种网络结构是ENet[8],采用编解码器结构,用于实时分割。这个设计目标使它成为一个合适的测试用例,因为它很好地符合超像素池层的目的。
近年来,在半监督分割[6]和图像分类[13]等不同背景下,超像素池化的概念也得到了广泛的研究。我们建议将该技术直接应用于完全监督的语义分割设置中。此外,我们提供了一个完整的层描述,包括实现细节和广泛的经验评估的方法在二维和三维图像。这包括将超像素池层集成到现有CNN架构中的具体设计。
3. 超像素池化
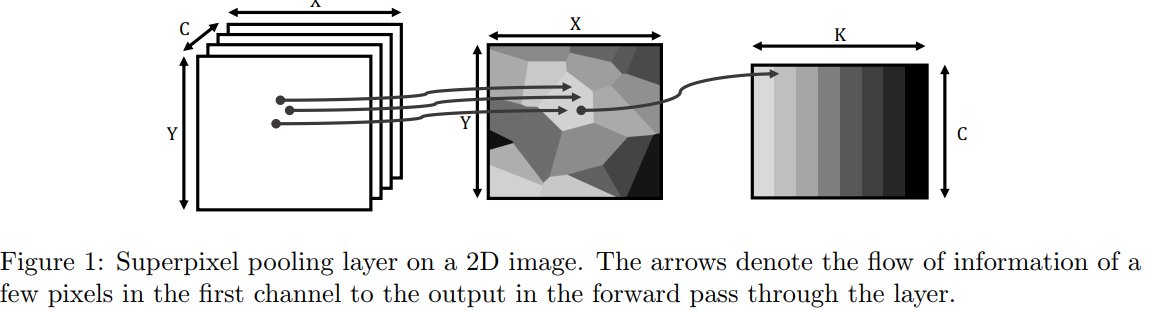
超像素池化的一般思想与常规池化非常相似。局部区域(即超像素)上的特征通过采样函数(如max(·)或avg(·)进行聚合。该步骤将图像中的信息从每个像素的一个特征向量减少到每个超像素的一个特征向量。考虑输入图像
I
∈
R
C
×
P
I \in R^{C \times P}
I∈RC×P,由
C
C
C个通道和
P
P
P个像素组成。超像素分割由单通道图像
S
∈
L
P
S \in L^P
S∈LP表示,其中
L
=
[
1
,
K
]
L = [1, K]
L=[1,K]是每个超像素的整数标签,如果
S
i
=
K
S_i = K
Si=K,则像素
i
i
i属于超像素
K
K
K。给定这些输入之后,超像素池化层返回一个数组
P
∈
R
C
×
K
P \in R^{C \times K}
P∈RC×K:
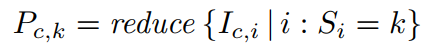
其中reduce是一个采样函数,如max(·)或avg(·)。
我们详细的计算通过超像素池化层与最大池化和平均池化的梯度的反向传播。
3.1 最大池化
用 i ∗ i^* i∗表示超像素中的最大值,
前向传播: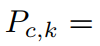
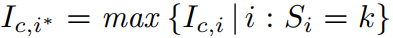
反向传播: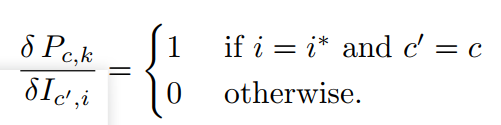
3.2 平均池化
前向传播: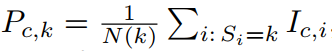
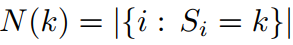
反向传播: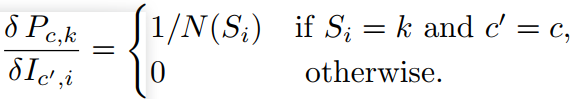
3.3 CPU实现
我们用两个CPU来测试超像素池化层。第一个实现基于用于Python的Scipy库[5]中的ndimage包。这导致了一个非常简单的实现,这对于验证该层的更优化版本非常有用。该层的第二个版本是用Python实现的,并通过使用Numba编译器[7]来加速。执行时间与池化层下面的像素数成线性关系。最大池化中的最大像素 i ∗ i^* i∗,或平均池化中的像素计数 N ( k ) N(k) N(k),并在前向传播过程中计算并存储起来。在后向传播中,根据式(2)和式(3)分别重用它们来计算梯度。
3.4 GPU实现
此外,我们还提出了一个并行gpu实现,这对于具有超像素池化层的CNN的有效训练和测试至关重要。在前向传递中,我们的实现旨在以以下方式利用并行性。(1)由于不同通道的输出是相互独立的,因此不需要共享任何内存。因此它们可以被单独的GPU块处理。(2)图像沿规则网格划分,GPU块的每个线程分配一个网格单元进行处理。块内的线程共享一个大小为K的同步读写数组,该数组跟踪每个超像素的计数(平均)或最大值(最大池)。图2以立体图像(超体素池化)为例说明了这个过程。
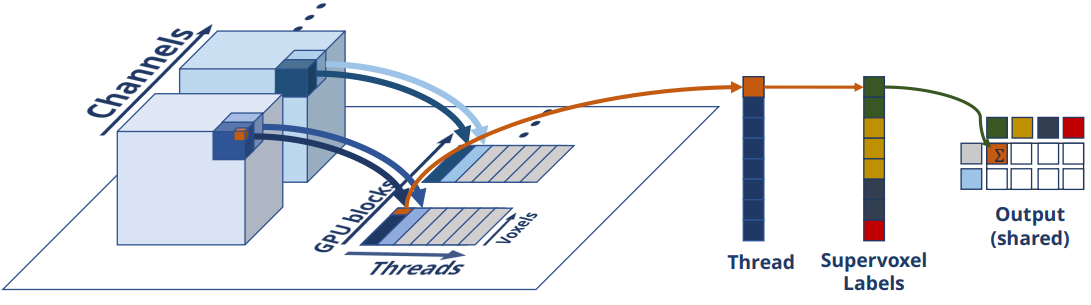
图2:超体素池层的GPU实现。GPU块处理输入立体块的不同通道,而块内的线程则沿规则网格分配一个图像立方体。每个线程遍历分配给它的多维数据集的像素(蓝色)和相关的超体素分配,更新超像素(共享输出)中运行的计数/最大值的共享副本。
为了避免写入输出数组时出现争用情况,我们使用原子函数。当线程对内存地址执行写操作时,这些函数会临时锁定内存地址。一般来说,原子函数会影响性能,因为它们会强制执行一定数量的序列化。当许多线程必须访问同一个地址时,这主要是一个问题。这里的情况并非如此:由于超像素在空间上是集中的,因此只有有限数量的线程将更新与每个超像素相关的条目。此外,我们还提出了一个并行gpu实现,这对于具有超像素池层的CNN的有效训练和推理至关重要。在前向传递中,我们的实现旨在以以下方式利用并行性。(1)由于不同通道的输出是相互独立的,因此不需要共享任何内存。因此它们可以被单独的GPU块处理。(2)图像沿规则网格划分,GPU块的每个线程分配一个网格单元进行处理。块内的线程共享一个大小为K的同步读写数组,该数组跟踪每个超像素的计数(平均)或最大值(最大池)。图2以体积图像(超体素池)为例说明了这个过程。
与在CPU中实现中一样,向后传递所需的信息在向前传递期间缓存,在向后传播期间重用。所有像素和通道组合的梯度都可以在GPU上并行计算。
3. 实验
3.1 超像素池化层的效率
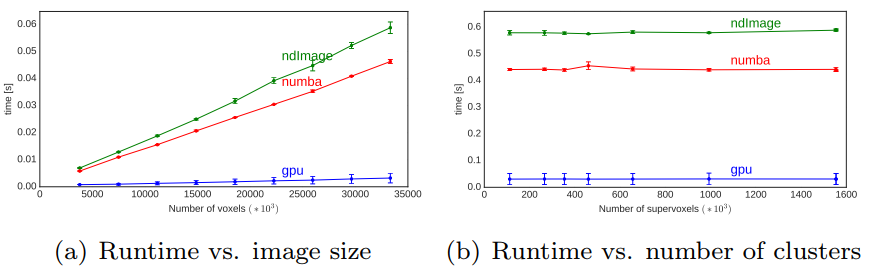
图3显示了我们的池化层实现的处理时间是像素数 P P P和聚类数 K K K的函数。GPU实现的性能大大优于CPU实现,处理时间减少了16倍。这三种方法都与P成线性关系,并且对于都不依赖于K。
3.2 聚合超像素池化和VoxResNet
3.2.1 实验设置
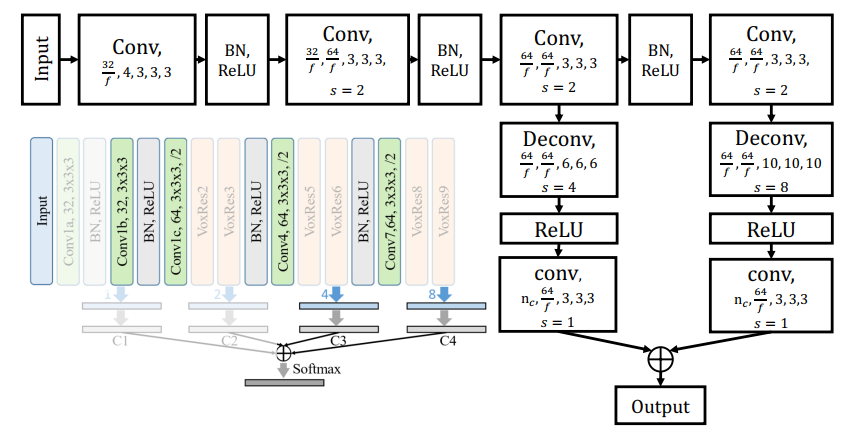
图4:简化后的VoxResNet[2]的详细架构。因子f可以通过降低特征空间的维数来进一步简化网络。在左下角,原始的架构被显示出来,省略的图层是灰色的。
在接下来的实验中,我们将考虑VoxResNet体系结构的三种变体。第一个是完整的体系结构,如[2]所述。另外两个是这个网络的简化版本(见图4)。在简化网络中,我们从网络中删除了大量的层,并将特征空间的维数降低了 1 / f 1/f 1/f。我们用"Reduce ( / f ) (/f) (/f)"表示这个网络的简化变体。这样做允许我们测试添加超像素池化层的效率而不增加网络复杂性。
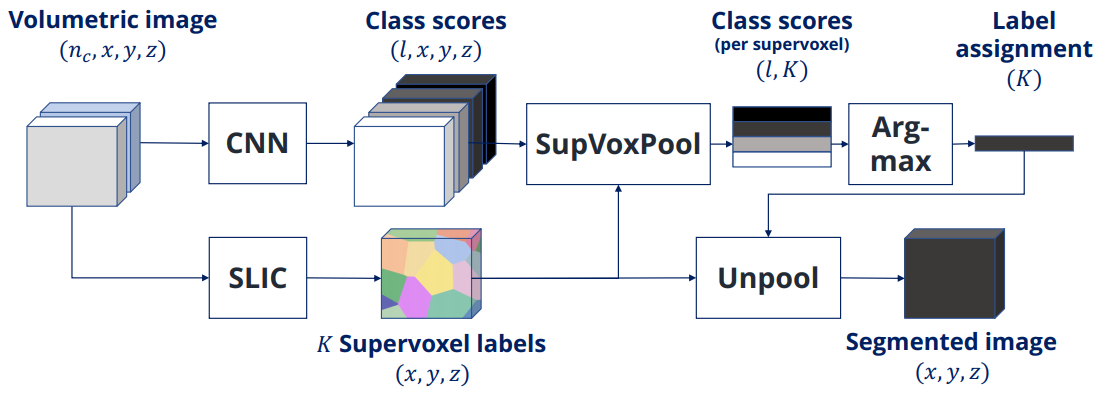
图5:分割流程展示(‘版本1’):使用SupVoxPool层作为后处理步骤。
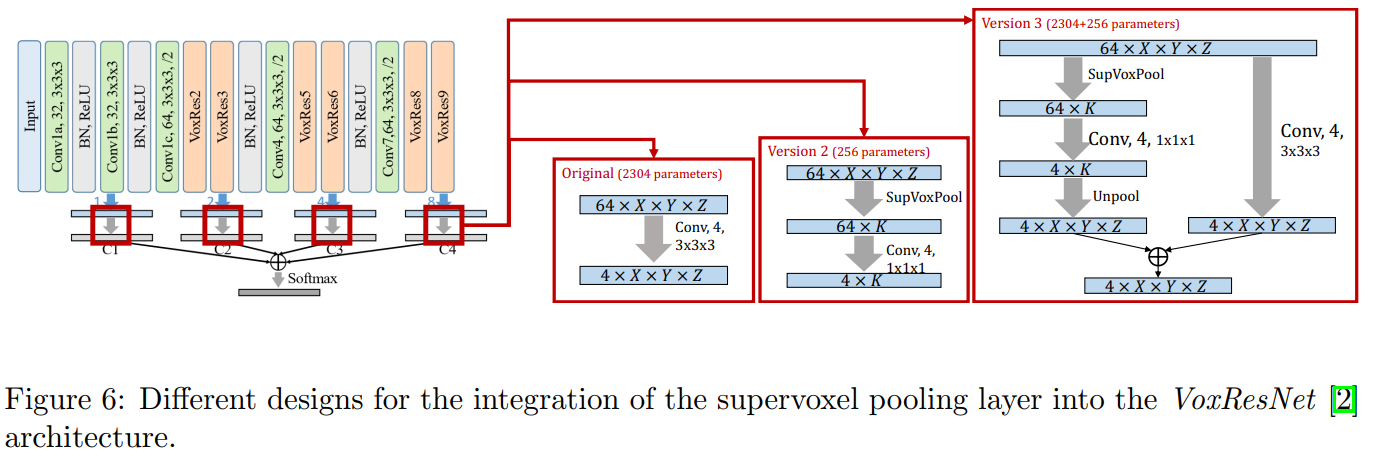
对于这三种基本网络,我们考虑将超体素池化(SupVoxPool)层集成到网络中的三种方法,分别表示为版本1、2和3。
版本1如图5所示。在该方案中,使用超体素池作为后处理步骤。网络本身保持不变。在这个方案中,只允许网络更新其权重,以便为SupVoxPool层提供更好的输入。
在版本2(图6)中,最后的3x3卷积被替换为SupVoxPool层并紧跟一个完全连接的层。这允许网络学习从超体素到类标签的映射。
版本3结合了这两种方法。最后一层被分成两个独立的分支。一个分支在超像素上运行,由与V2相同的组件组成。另一个分支在像素级运行,并保存在基本网络中。在这个设置中,网络可以学习超像素标签的像素级更正。
基线网络(不含超体素)全部从零开始在Internet Brain Segmentation Repository (IBSR)[10]上进行训练,分为4类(BG、CSF、WM、GM)。然后从基线网络中对超体素网络进行微调。所报道的结果是试验数据的骰子系数。它们平均经过3次交叉验证,其中12个立方体用于训练和模型选择。其余6个用于测试。我们在下面的结果中使用了max池,因为它在初始实验中始终优于平均池。
3.3 聚合超像素池化和ENet
我们演示了向ENet[8]添加超像素池化层的相关性,ENet[8]是一种根据速度调整的语义分割架构。我们证明,超像素池化层可以极大地提高分割结果的质量,以最小的测试开销。
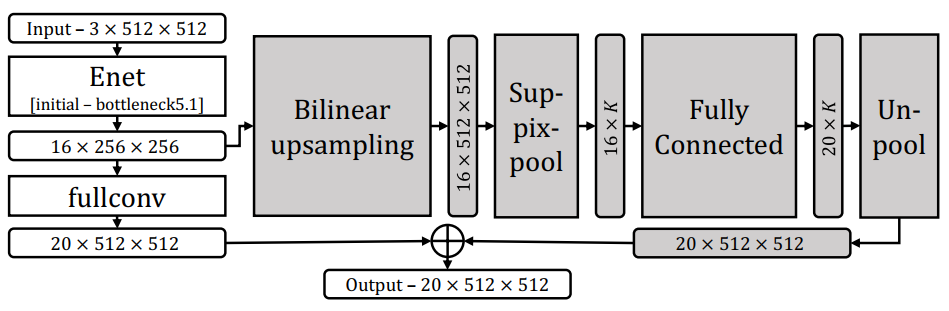
与VoxResNet体系结构的V3设置类似,我们通过在网络末端添加一个并行的超像素分支来修改ENet体系结构。我们再次将feature map中的激活在超像素上进行聚合(池化)。然后,我们添加一个完全连接的层来将超像素级的激活映射到输出空间。最后,将这两个分支的结果以像素级和的形式组合起来。设计的示意图如图10所示。图像预处理过程中,利用gSLICr[9]在GPU上进行超像素分割,实现了最小的开销。在我们的实验中,我们加载作者的原始参数,并在Cityscapes数据集[3]上对网络进行微调。
3.3.1 实验结果
我们使用SLIC超像素和矩形超像素对网络进行了finetune,超像素K在500、1000、5000和10000之间。根据验证数据,我们发现K = 1000时得到了最好的结果。表3给出了这个网络的准确性与在Cityscapes[3]测试数据上评估的原始ENet体系结构之间的比较。

表4显示了Cityscapes中定义的不同对象类别的IoU得分。虽然超像素在所有类别中都带来了改进,但我们观察到,对于细节更细、边缘清晰、背景鲜明的对象,效果最大,就像在物体和人类类别中一样。这一点在类别分数上得到了印证:交通灯、交通标志、骑车人的分数提高了8%以上,而其他类别的成绩提高了0.2% - 4%。由于超像素往往能够很好地保存高度对比的边缘,因此它们可以作为这些类的有效先验,并允许网络以更精细的细节恢复边缘。

使用Nvidia Titan X (Pascal) GPU,对于具有超像素的ENet,对分辨率为1024x512(在我们对cityscapes数据集的测试中使用)的图像的推断时间为13 ms。相比之下,基本网络是11毫秒。我们认为,进一步优化GPU上的超像素池层实现是可能的,并将进一步减少由超像素池层引起的开销。
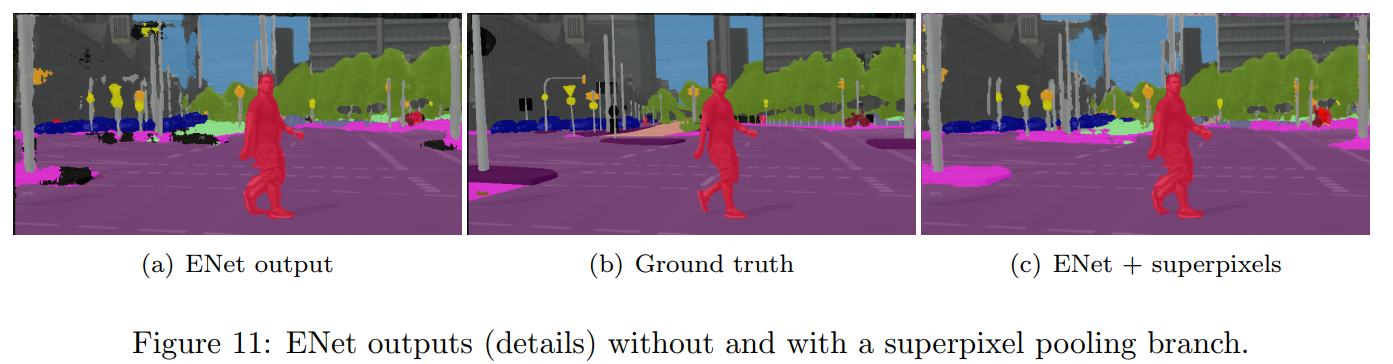
图11显示了没有和有超像素池分支的ENet输出分割的可视化比较。表4中的分类结果已经表明,它更接近硬边缘(例如注意行人的脚)。此外,我们还观察到,倾向于表示大的均匀区域的类,比如道路或人行道,从超像素池层中获益良多。例如,左边的伪未定义区域就证明了这一点,这些区域通过将这些区域分组为超像素来删除。在构成精细细节的硬而精确的边缘上的精确度的提高,以及较大区域的均匀性的提高,导致了表3-4所示的测试准确度的提高。
4. 总结
在本文中,我们提出了一种简单而高效的CNNs超像素(或超体素)池层gpu实现方法,并在现有的VoxResNet[2]和Enet[8]两个分割网络中提供了该层的实验结果。实验表明,当超像素池层与像素级分割相结合时,网络的分割精度不断提高。这允许网络使用来自超像素的上下文信息,但要在像素级别进行纠正。此外,我们发现使用超像素池层的好处随着网络的简化而增加。这就促使了实时分割应用程序使用超像素池化。源代码可从https://github.com/bermanmaxim/superpixPool获得。















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









