







一:我对SVM的理解
先介绍一些简单的基本概念
分隔超平面:将数据集分割开来的直线叫做分隔超平面。
超平面:如果数据集是N维的,那么就需要N-1维的某对象来对数据进行分割。该对象叫做超平面,也就是分类的决策边界。
间隔:
一个点到分割面的距离,称为点相对于分割面的距离。
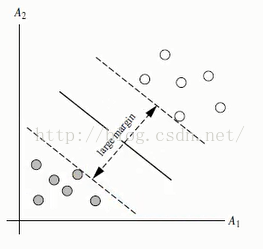
数据集中所有的点到分割面的最小间隔的2倍,称为分类器或数据集的间隔。
最大间隔:SVM分类器是要找最大的数据集间隔。
支持向量:坐落在数据边际的两边超平面上的点被称为支持向量
1:超平面
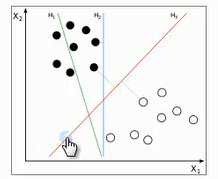
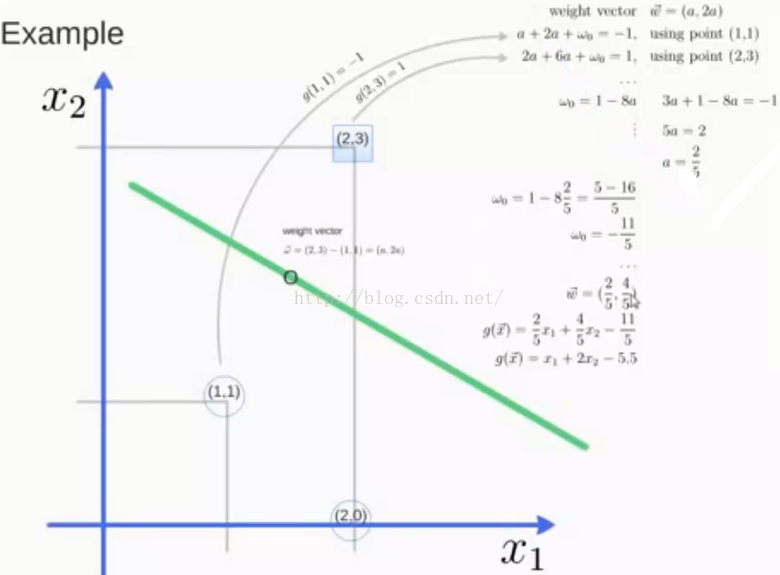
对于上图直观的理解是红线的分类效果最好,为什么?
由此便引出了超平面的定义,SVM的目标就是寻找区分两类的超平面(hyper plane),使边际(margin)最大化。
那么如何选择超平面?超平面到一侧最近点的距离等于另一侧最近点的距离,两个超平面平行,如下图。
2:线性可区分(linear separable)和线性不可区分(linear inseparable)
上面显示的两个图都是线性可区分的,就是说很容易找到一个超平面将数据分割成两类
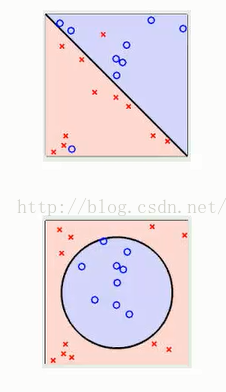
上图中的两个图形都是线性不可区分的,这种情况下,我们就需要用到核函数,将数据映射到高维空间中,寻找可区分数据的超平面
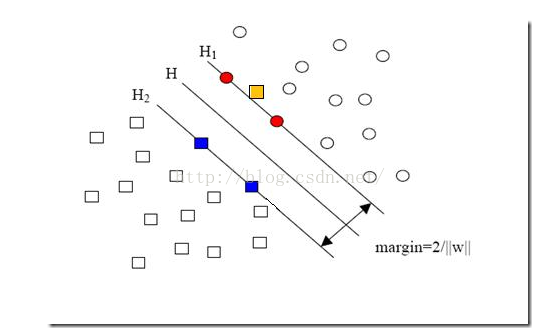
对于这幅图来说,就是图中黄色那个点,它是方形的,因而它是负类的一个样本,这单独的一个样本,使得原本线性可分的问题变成了线性不可分的。这样类似的问题(仅有少数点线性不可分)叫做“近似线性可分”的问题。对于这类问题的处理就引入了一个松弛变量,当然随之而来的便是惩罚因子了,具体他们是什么请参考:点击阅读 , 这里不做解释
3:针对线性可区分,求超平面推导
超平面的公式可以定义为 : W * X + b = 0 W表示权重向量 W= {w1,w2,w3,w4.....,wn},n为特征值的个数 , X为训练实例, b表示偏移量
在这里假设二维特征向量X=(x1,x2)
做另外一个假设就是把b看作是另外一个weight,那么超平面就可以更新为:w0 + w1 * x1 +w2 * x2 = 0
所有超平面右上方的点满足: w0 + w1 * x1 +w2 * x2 > 0
所有超平面左下方的点满足: w0 + w1 * x1 +w2 * x2 < 0
调整weight,使超平面定义边际的两边:
H1:H1:w0 + w1 * x1 +w2 * x2 > 1 for yi=+1
H2:w0 + w1 * x1 +w2 * x2 =< -1 for yi=-1
综合上边两个公式得到:
(1): yi (w0 + w1 * x1 +w2 * x2) >= 1 ,对于所有的i来说
所有坐落在数据边际的两边超平面上的点被称为支持向量
分界的超平面H1和H2任意一点的距离为 1/||W|| , ||W||表示向量的范数
W= sqrt(W1^2 + W2^2 + ... + Wn^2)
所以两边最大距离为 2/||W||
利用一些数学公式的推导,以上公式(1)可以变为有限制的凸优化问题,利用KKT条件和拉格朗日公式,可以推出MMH(最大超平面)表示为以下决策边界:
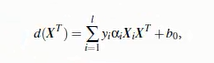
yi是支持向量点Xi的类别标记
X^T是要测试的实例
ai和b0都是单一数值型参数
l是支持向量点的个数
下面看一张示例图片:
特性:训练好的模型算法复杂度是由支持向量的个数决定的,而不是 数据的纬度决定的,所以SVM不太容易产生OverWriting
SVM训练出的模型完全依赖于支持向量,即使所有训练集里所有非支持向量的点都被去除,重复训练过程,结果仍会得到一个完全一模一样的模型
一个SVM如果训练得出的支持向量个数比较小,SVM训练出的模型也容易被泛化
4:针对线性不可区分,求超平面推导
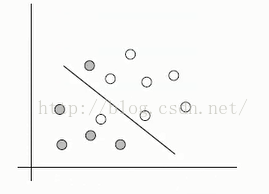
针对这种在空间中对应的向量不能被一个超平面划分开,用以下两个步骤来解决
1:利用一个非线性的映射把原数据集中的向量点转化到一个更高维的空间中
2:在这个高纬度的空间中找一个线性超平面来根据线性可分的情况处理
如下图示:
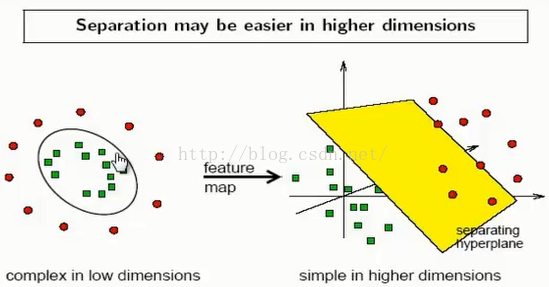
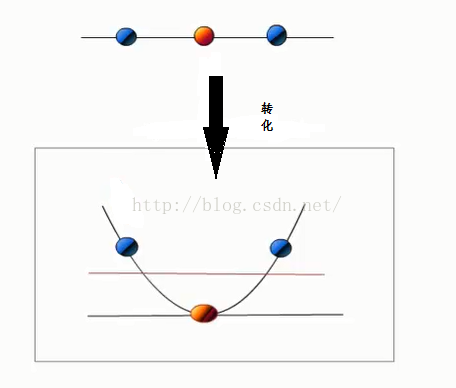
那么如何利用非线性映射把 转化到高维空间中
下面看一个小例子:

思考问题:如何选择合理的非线性转化把数据转到高维空间中?如何解决计算内积时算法复杂度高的问题?
答案是使用核函数
5:核函数



至此SVM已经被我描述的差不多,其中的两部分求超平面的具体数学推导和核函数的具体使用方法,我并没有写,第一是因为,对于非数学专业的人来讲确实麻烦了,其次是自己太菜,但是网上已经有很多写的很好的博客,大家可以参考,下面我们就来看看scikit-learn上SVM的具体使用吧
二:Scikit-learn上对SVM相关描述
1:Classification
首先我们来看看SVC,NvSVC,LinearSVC的区别和样例
SVC(C-Support Vector Classification):支持向量分类,基于libsvm实现的,数据拟合的时间复杂度是数据样本的二次方,这使得他很难扩展到10000个数据集,当输入是多类别时(SVM最初是处理二分类问题的),通过一对一的方案解决,当然也有别的解决办法,比如说(以下为引用)
========================================================================================
SVM解决多分类问题的方法
SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。目前,构造SVM多类分类器的方法主要有两类:一类是直接法,直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类。这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中;另一类是间接法,主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有one-against-one和one-against-all两种。
a.一对多法(one-versus-rest,简称1-v-r SVMs)。训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
b.一对一法(one-versus-one,简称1-v-1 SVMs)。其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。Libsvm中的多类分类就是根据这个方法实现的。
c.层次支持向量机(H-SVMs)。层次分类法首先将所有类别分成两个子类,再将子类进一步划分成两个次级子类,如此循环,直到得到一个单独的类别为止。
对c和d两种方法的详细说明可以参考论文《支持向量机在多类分类问题中的推广》(计算机工程与应用。2004)
d.其他多类分类方法。除了以上几种方法外,还有有向无环图SVM(Directed Acyclic Graph SVMs,简称DAG-SVMs)和对类别进行二进制编码的纠错编码SVMs。
=====================================================================================
svc使用代码示例(我演示的是最简单的,官网上还有很多看起来很漂亮的分类示例,感兴趣的可以自己参考下):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
<span style=
"font-family:Microsoft YaHei;"
><span style=
"font-family:Microsoft YaHei;font-size:14px;"
>
''
'
SVC参数解释
(
1
)C: 目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的,
default
C =
1.0
;
(
2
)kernel:参数选择有RBF, Linear, Poly, Sigmoid, 默认的是
"RBF"
;
(
3
)degree:
if
you choose
'Poly'
in param
2
,
this
is effective, degree决定了多项式的最高次幂;
(
4
)gamma:核函数的系数(
'Poly'
,
'RBF'
and
'Sigmoid'
), 默认是gamma =
1
/ n_features;
(
5
)coef0:核函数中的独立项,
'RBF'
and
'Poly'
有效;
(
6
)probablity: 可能性估计是否使用(
true
or
false
);
(
7
)shrinking:是否进行启发式;
(
8
)tol(
default
= 1e -
3
): svm结束标准的精度;
(
9
)cache_size: 制定训练所需要的内存(以MB为单位);
(
10
)class_weight: 每个类所占据的权重,不同的类设置不同的惩罚参数C, 缺省的话自适应;
(
11
)verbose: 跟多线程有关,不大明白啥意思具体;
(
12
)max_iter: 最大迭代次数,
default
=
1
,
if
max_iter = -
1
, no limited;
(
13
)decision_function_shape : ‘ovo’ 一对一, ‘ovr’ 多对多 or None 无,
default
=None
(
14
)random_state :用于概率估计的数据重排时的伪随机数生成器的种子。
ps:
7
,
8
,
9
一般不考虑。
''
'
from sklearn.svm
import
SVC
import
numpy as np
X= np.array([[-
1
,-
1
],[-
2
,-
1
],[
1
,
1
],[
2
,
1
]])
y = np.array([
1
,
1
,
2
,
2
])
clf = SVC()
clf.fit(X,y)
print clf.fit(X,y)
print clf.predict([[-
0.8
,-
1
]])</span></span>
|
输出结果为:
第一个打印出的是svc训练函数的参数
最后一行打印的是预测结果
NuSVC(Nu-Support Vector Classification.):核支持向量分类,和SVC类似,也是基于libsvm实现的,但不同的是通过一个参数空值支持向量的个数
示例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<span style=
"font-family:Microsoft YaHei;"
><span style=
"font-family:Microsoft YaHei;font-size:14px;"
>
''
'
NuSVC参数
nu:训练误差的一个上界和支持向量的分数的下界。应在间隔(
0
,
1
]。
其余同SVC
''
'
import
numpy as np
X = np.array([[-
1
, -
1
], [-
2
, -
1
], [
1
,
1
], [
2
,
1
]])
y = np.array([
1
,
1
,
2
,
2
])
from sklearn.svm
import
NuSVC
clf = NuSVC()
clf.fit(X, y)
print clf.fit(X,y)
print(clf.predict([[-
0.8
, -
1
]]))
</span></span>
|
输出结果:

LinearSVC(Linear Support Vector Classification):线性支持向量分类,类似于SVC,但是其使用的核函数是”linear“上边介绍的两种是按照brf(径向基函数计算的,其实现也不是基于LIBSVM,所以它具有更大的灵活性在选择处罚和损失函数时,而且可以适应更大的数据集,他支持密集和稀疏的输入是通过一对一的方式解决的
代码使用实例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
<span style=
"font-family:Microsoft YaHei;"
>
''
'
LinearSVC 参数解释
C:目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的,
default
C =
1.0
;
loss :指定损失函数
penalty :
dual :选择算法来解决对偶或原始优化问题。当n_samples > n_features 时dual=
false
。
tol :(
default
= 1e -
3
): svm结束标准的精度;
multi_class:如果y输出类别包含多类,用来确定多类策略, ovr表示一对多,“crammer_singer”优化所有类别的一个共同的目标
如果选择“crammer_singer”,损失、惩罚和优化将会被被忽略。
fit_intercept :
intercept_scaling :
class_weight :对于每一个类别i设置惩罚系数C = class_weight[i]*C,如果不给出,权重自动调整为 n_samples / (n_classes * np.bincount(y))
verbose:跟多线程有关,不大明白啥意思具体</span>
|
from sklearn.svm import SVC X=[[0],[1],[2],[3]] Y = [0,1,2,3] clf = SVC(decision_function_shape='ovo') #ovo为一对一 clf.fit(X,Y) print clf.fit(X,Y) dec = clf.decision_function([[1]]) #返回的是样本距离超平面的距离 print dec clf.decision_function_shape = "ovr" dec =clf.decision_function([1]) #返回的是样本距离超平面的距离 print dec #预测 print clf.predict([1])
random_state :用于概率估计的数据重排时的伪随机数生成器的种子。max_iter :'''import numpy as npX = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])y = np.array([1, 1, 2, 2])from sklearn.svm import LinearSVCclf = LinearSVC()clf.fit(X, y) print clf.fit(X,y)print(clf.predict([[-0.8, -1]]))
|
1
|
|
结果如下:

Multi-class classification(多类别分类)
SVC和NuSVC对于多分类问题采用的是一对一的方法,若n_class表示类别的数目,则需要构造n_class *(n_class - 1)/ 2个分类器,每一次训练集采用两类别,提供了一个与其它分类一致的接口,该decision_function_shape选项允许聚合结果的“一对一”的分类决策函数的形状,下边看一小例子
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
<span style=
"font-family:Microsoft YaHei;"
><span style=
"font-family:Microsoft YaHei;"
>#-*-coding:utf-
8
-*-
''
'
Created on
2016
年
4
月
29
日
@author
: Gamer Think
''
'
from sklearn.svm
import
SVC,LinearSVC
X=[[
0
],[
1
],[
2
],[
3
]]
Y = [
0
,
1
,
2
,
3
]
''
'
SVC and NuSVC
''
'
clf = SVC(decision_function_shape=
'ovo'
) #ovo为一对一
clf.fit(X,Y)
print
"SVC:"
,clf.fit(X,Y)
dec = clf.decision_function([[
1
]]) #返回的是样本距离超平面的距离
print
"SVC:"
,dec
clf.decision_function_shape =
"ovr"
dec =clf.decision_function([
1
]) #返回的是样本距离超平面的距离
print
"SVC:"
,dec
#预测
print
"预测:"
,clf.predict([
1
])
''
'</span></span>
|
LinearSVC'''lin_clf = LinearSVC()lin_clf.fit(X, Y) dec = lin_clf.decision_function([[1]])print "LinearSVC:",dec.shape[1]
|
1
|
|
结果显示:
红色字体暂时忽略
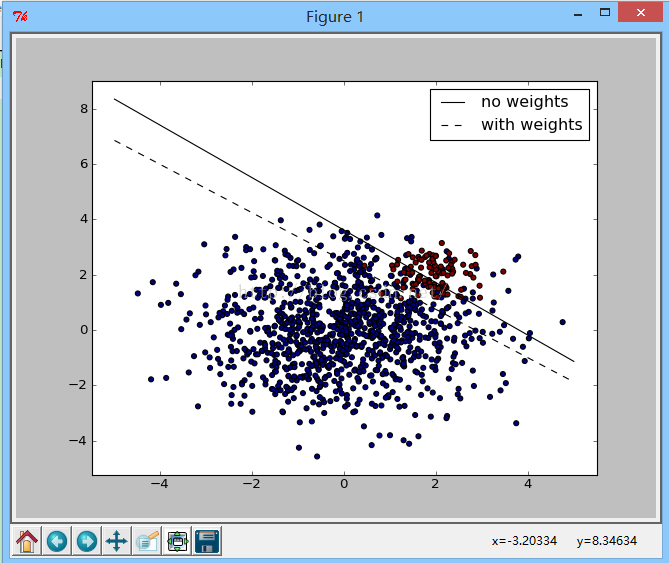
Unbalanced problems(数据不平衡问题)
对于非平衡级分类超平面,使用不平衡SVC找出最优分类超平面,基本的思想是,我们先找到一个普通的分类超平面,自动进行校正,求出最优的分类超平面
这里可以使用SGDClassifier(loss="hinge")代替SVC(kernel="linear")
针对下面的svc可以使用clf=SGDClassifier(n_iter=100,alpha=0.01) 代替
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
<span style=
"font-family:Microsoft YaHei;"
><span style=
"font-family:Microsoft YaHei;"
># -*-coding:utf-
8
-*-
''
'
Created on
2016
年
5
月
4
日
@author
: Gamer Think
''
'
import
numpy as np
import
matplotlib.pyplot as plt
from sklearn
import
svm
#from sklearn.linear_model
import
SGDClassifier
# we create
40
separable points
rng = np.random.RandomState(
0
)
n_samples_1 =
1000
n_samples_2 =
100
X = np.r_[
1.5
* rng.randn(n_samples_1,
2
),
0.5
* rng.randn(n_samples_2,
2
) + [
2
,
2
]]
y = [
0
] * (n_samples_1) + [
1
] * (n_samples_2)
print X
print y
# fit the model and get the separating hyperplane
clf = svm.SVC(kernel=
'linear'
, C=
1.0
)
clf.fit(X, y)
w = clf.coef_[
0
]
a = -w[
0
] / w[
1
] #a可以理解为斜率
xx = np.linspace(-
5
,
5
)
yy = a * xx - clf.intercept_[
0
] / w[
1
] #二维坐标下的直线方程
# get the separating hyperplane using weighted classes
wclf = svm.SVC(kernel=
'linear'
, class_weight={
1
:
10
})
wclf.fit(X, y)
ww = wclf.coef_[
0
]
wa = -ww[
0
] / ww[
1
]
wyy = wa * xx - wclf.intercept_[
0
] / ww[
1
] #带权重的直线
# plot separating hyperplanes and samples
h0 = plt.plot(xx, yy,
'k-'
, label=
'no weights'
)
h1 = plt.plot(xx, wyy,
'k--'
, label=
'with weights'
)
plt.scatter(X[:,
0
], X[:,
1
], c=y)
plt.legend()
plt.axis(
'tight'
)
plt.show()</span></span>
|
运行结果截图
2:Regression
支持分类的支持向量机可以推广到解决回归问题,这种方法称为支持向量回归
支持向量分类所产生的模型仅仅依赖于训练数据的一个子集,因为构建模型的成本函数不关心在超出边界范围的点,类似的,通过支持向量回归产生的模型依赖于训练数据的一个子集,因为构建模型的函数忽略了靠近预测模型的数据集。
有三种不同的实现方式:支持向量回归SVR,nusvr和linearsvr。linearsvr提供了比SVR更快实施但只考虑线性核函数,而nusvr实现比SVR和linearsvr略有不同。
作为分类类别,训练函数将X,y作为向量,在这种情况下y是浮点数
|
1
2
3
4
5
6
7
8
9
|
<span style=
"font-family:Microsoft YaHei;"
><span style=
"font-family:Microsoft YaHei;"
>>>> from sklearn
import
svm
>>> X = [[
0
,
0
], [
2
,
2
]]
>>> y = [
0.5
,
2.5
]
>>> clf = svm.SVR()
>>> clf.fit(X, y)
SVR(C=
1.0
, cache_size=
200
, coef0=
0.0
, degree=
3
, epsilon=
0.1
, gamma=
'auto'
,
kernel=
'rbf'
, max_iter=-
1
, shrinking=True, tol=
0.001
, verbose=False)
>>> clf.predict([[
1
,
1
]])
array([
1.5
])</span></span>
|
下面看一个使用SVR做线性回归的例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
<span style=
"font-family:Microsoft YaHei;"
><span style=
"font-family:Microsoft YaHei;"
>#-*-coding:utf-
8
-*-
''
'
Created on
2016
年
5
月
4
日
@author
: Gamer Think
''
'
import
numpy as np
from sklearn.svm
import
SVR
import
matplotlib.pyplot as plt
###############################################################################
# Generate sample data
X = np.sort(
5
* np.random.rand(
40
,
1
), axis=
0
) #产生
40
组数据,每组一个数据,axis=
0
决定按列排列,=
1
表示行排列
y = np.sin(X).ravel() #np.sin()输出的是列,和X对应,ravel表示转换成行
###############################################################################
# Add noise to targets
y[::
5
] +=
3
* (
0.5
- np.random.rand(
8
))
###############################################################################
# Fit regression model
svr_rbf = SVR(kernel=
'rbf'
, C=1e3, gamma=
0.1
)
svr_lin = SVR(kernel=
'linear'
, C=1e3)
svr_poly = SVR(kernel=
'poly'
, C=1e3, degree=
2
)
y_rbf = svr_rbf.fit(X, y).predict(X)
y_lin = svr_lin.fit(X, y).predict(X)
y_poly = svr_poly.fit(X, y).predict(X)
###############################################################################
# look at the results
lw =
2
plt.scatter(X, y, color=
'darkorange'
, label=
'data'
)
plt.hold(
'on'
)
plt.plot(X, y_rbf, color=
'navy'
, lw=lw, label=
'RBF model'
)
plt.plot(X, y_lin, color=
'c'
, lw=lw, label=
'Linear model'
)
plt.plot(X, y_poly, color=
'cornflowerblue'
, lw=lw, label=
'Polynomial model'
)
plt.xlabel(
'data'
)
plt.ylabel(
'target'
)
plt.title(
'Support Vector Regression'
)
plt.legend()
plt.show()</span></span>
|
运行结果:















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









