







开篇
几个问题:
1、MySQL和Innodb有哪些级别的锁?
2、表锁和行锁的区别有哪些?从以下结果方面:加锁效率,加锁粒度,实现复杂度,占用空间,并发度、超时时间
3、行锁加到什么对象上?唯一索引和非唯一索引加锁时有什么区别,如果没有索引呢?
4、等值查询和范围查询加锁的区别,等值查询如果没有命中会怎么样?
几条语句:
- show process list 线程执行状态
- select * from performance_schema.data_locks。查看行锁和意向锁 字段描述
- select * from performance_schema.metadata_locks 查看元数据锁 字段描述
几个参数:
- autocommit:事务是否自动提交 默认 1
- innodb_lock_wait_timeout :DML行锁超时时间。默认50s
- lock_wait_timeout :FWTRL、MDL、DDL超时时间。默认一年
- innodb_locks_unsafese_for_binlog :0是否关闭间隙锁。默认开启。等同于隔离界别设为RC
- innodb_deadlock_detect:死锁检测开关,默认为on
一个前提
如未做特别声明,以下默认MySQL 8.0 Innodb引擎 可重复读(RR)隔离级别 auto-commit=false
|
|
几种类型的锁
按模式区分:
LOCK_IS(⼗进制的0):表示共享意向锁,也就是IS锁。
LOCK_IX(⼗进制的1):表示独占意向锁,也就是IX锁。
LOCK_S(⼗进制的2):表示共享锁,也就是S锁。
LOCK_X(⼗进制的3):表示独占锁,也就是X锁。
LOCK_AUTO_INC(⼗进制的4):表示AUTO-INC锁。
按类型:
LOCK_TABLE 表示表级锁。
LOCK_REC 表示⾏级锁。
⾏锁的具体类型:
LOCK_ORDINARY:表示next-key锁。
LOCK_GAP:表示gap锁。
LOCK_REC_NOT_GAP:表示记录锁。
LOCK_INSERT_INTENTION:表示插⼊意向锁
全局锁
使用场景
全库逻辑备份时,使用全局锁使用方式
加锁:Flush tables with read lock (FTWRL)
解锁:unlock tables 或者session结束或者kill thread_id
加锁之后
1、整库进入只读状态,DML写操作和DDL都会被阻塞
2、如果在主库上加全局锁,则业务的写操作需要停摆
3、如果在从库上加全局锁,则binlog的就会出现延迟
备份时替代方案
1、mysqldump使用参数–single-transaction 确保拿到一致性视图,此时不会阻塞读写操作
限制:当前存储引擎支持事务,且支持MVCC
2、set global readonly=true
限制:1、readonly一版用于判断主库还是从库,修改后库的性质发生变化
2、FTWRL客户端session结束会释放锁,readonly必须手动修改
3、readonly=true把普通用户设置为只读操作,但不会阻塞binglog
表级锁
表锁:
加锁语句:
lock tables t1 read/write
解锁语句:
unlock tables ;
加表锁注意事项:
1、表锁与表锁之间、表锁与行锁之间的兼容关系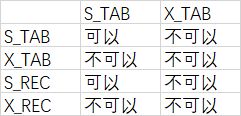
注:首行表示已加的锁,首列表示待加的锁
2、同一个session内,可以对多个表加表锁,解锁时会把session内所有的表锁全部释放(锁是与trx_id相关联的)。
3、事务的提交、回滚不会真正释放锁(虽然performance_schema.data_locks已查不到)。unlock tables 或者线程结束都才可以释放。
问题一:什么场景下用表锁效率更高?
1、大部分SQL都是读请求
2、读写混合的SQL,但写请求都是单行的update和delete
update user set age = age+1 where id = 1001;
delete from user where id = 1002;
3、读写混合的SQL,但写请求是高并发insert,较少有update和delete
4、sql会扫描大量的行记录,且会有大量group by
问题二:lock tables t read/write会不会造成死锁?
| session A | session B |
|---|---|
lock tables t write | |
lock tables t1 write | |
lock tables t1 write //blocking | |
lock tables t write //是否死锁 |
结论:同一个线程,lock tables会释放之前加成功的锁
元数据锁(metadata lock MDL)
1、不需要显示的使用,访问一个表时是自动加上,事务提交时释放
2、执行DML时加MDL读锁,执行DDL是假MDL写锁。延伸:MDL
3、读-读之间不互斥,读-写、写-写之间互斥。
4、mysql5.6 之后引入online DDL,在DDL的同时可以进行DML。延伸:Online DDL
auto-inc锁
1、当执行insert时,有自增列时,数据库自动生成自增值,此时加auto-inc。
2、此时阻塞其他的插入操作,以此保证自增值唯一。
3、自增值一旦分配了就会+1,插入失败或事务回滚不会减回去,可能因此不连续。
延伸:auto-inc锁
意向锁
意向锁是表级别的锁,用来标识该表上有数据被锁住或即将被锁对于表级别的请求(LOCK TABLE…),就可以直接判断是否有锁冲突,不需要逐行检查锁的状态目的是为了提高表锁的加锁效率
读意向锁(IS)
select * from t where id = 1 lock in share mode写意向锁
select * from t where id = 1 for update 锁兼容矩阵

总结起来:
1、意向锁之间互不冲突
2、S锁只和S/IS兼容,和其他锁冲突
3、X锁和所有的锁都冲突
行级锁
两阶段锁协议
1、行锁是在需要的时候加上的,但并不是使用完之后马上释放
2、而是等到事务结束(提交或回滚)的时候才会释放
加行锁的方法
加读锁:
select * from t1 where id=10 lock in share mode
select * from t1 where id=10 for share(MySQL 8)
加写锁:
select * from t1 where id = 10 for update
update t1 set name = 'lxz' where id = 10;锁定对象
-
使用聚簇索引,则只会在聚簇索引上加锁- 使用二级索引,会在二级索引和聚簇索引上都加锁(lock in share mode 模式下,覆盖索引除外)
- 未命中索引则锁定所有的行
行级锁算法
记录锁(Record Lock)
SELECT * FROM table WHERE id = 10 FOR UPDATE/SHARE;
锁类型:LOCK_REC_NOT_GAP
记录锁只锁住行。RR隔离级别下,当对主键或者唯一索引进行等值查询且命中记录时,会加记录锁
间隙锁(Gap Lock)
select * from table where id = 12 for update/share锁类型:LOCK_GAP
锁住一个间隙,比如(10,15)。对于主键或唯一索引进行等值查询时,未命中记录会加间隙锁
间隙锁存在的目的阻止插入
临键锁(Next-key Lock)
select * from table where c = 10;
select * from table where id >=10;
锁类型:LOCK_ORDINARY
记录锁+间隙锁
临键锁是前开后闭区间
插入意向锁(Insert Intention Lock)
锁类型:LOCK_INSERT_INTENTION
1、一般插入不加锁
2、插入意向锁之间不会阻塞,只会和间隙锁、临键锁相互阻塞
3、执行insert时检查是否有间隙锁,有的话并阻塞等待
| session A | Session B |
|---|---|
| select * from t where id > 0 and id < 5 for update | |
| insert into t values(3,3,3); //阻塞X,GAP,INSERT_INTENTION |
问题:Session B是否会阻塞?阻塞在哪个对象上?
| session A | session B |
|---|---|
| insert into t values(3,3,3); | |
| select * from t where id > 0 for update //是否阻塞 |
隐式锁:
1、⼀个事务对新插⼊的记录可以不显式的加锁(⽣成⼀个锁结构),叫做隐式锁。
2、当其他事务要加读或者写锁的时候,会帮助加隐式锁的事务生成生成一个锁结构,然后再生成自己的锁结构并阻塞。
问题:怎么才能发现隐式锁的存在?
聚簇索引:通过当前记录的trx_id,在事务池里查看当前事务是否是活跃的
二级索引:通过页结构上PAGE_MAX_TRX_ID,如果PAGE_MAX_TRX_ID小于当前活跃的最小事务id,那么说明对该⻚⾯做修改的事务都已经提交了(无锁)。否则就需要通过二级索引定位到聚簇索引。使用聚簇索引的trx_id
行锁加锁规则总结
总结起来:两个原则,两个优化,一个bug
原则一:加锁基本单位是next-key lock ,临键锁前开后闭
原则二:查找过程中有访问到对象才会加锁
优化一:主键或唯一索引等值查询且命中对象,退化为记录锁
优化二:索引等值查询,查询到最后一个不满足条件的值时退化为间隙锁
bug一:索引范围查询,会访问到不满足条件的第一个值为止
几个案例分析加锁过程:
1、主键等值查询不命中的情况:
| session A | session B |
|---|---|
| select * from t where id = 12 for update | |
| insert into t select 11,11,11;//阻塞 |
2、主键或唯一索引不存在间隙的情况下,是否降级为行锁| session A | session B |
|---|---|
| insert into t values(6,6,6),(7,7,7); | |
| commit | |
| select * from t where id >5 and id <7 for update;//next-key lock | |
| select * from t where id = 5 for update//query ok | |
| select * from t where id = 6 for update//阻塞 |
3、二级索引等值查询
| session A | session B |
|---|---|
| select * from t where c = 10 for update //(5,10] (10,15) | |
| insert into t select 8,8,8;// 阻塞 | |
| insert into t select 11,11,11;//阻塞 |
| session A | session B | session C |
|---|---|---|
| select id from t where c = 5 lock in share mode | ||
| select * from t where id =5;//不阻塞 | ||
| insert into select 8,8,8 //阻塞 | ||
4、唯一索引范围查询
| session A | session B |
|---|---|
| select * from t where d <= 15 for update | |
| insert into t select 17,17,17;//是否阻塞 |
5、删除数据| session A | session B |
|---|---|
| select * from t where id > 10 and id < 15 for update; | |
| delete from t where id = 10; | |
| insert into t values(10,10,10);//是否阻塞 |
6、不同排序方式造成的锁定差异
| session A |
|---|
|
|
7、limit 优化
| session A | session B |
|---|---|
| select * from t where c = 10 limit 1 for update | |
| insert into t select 12,12,12 ;//不阻塞 | |
其他几种需要注意的情况:
1、间隙锁是为了解决幻读问题,update 、delete语句只会加行锁。
2、INSERT ... ON DUPLICATE KEY UPDATE 未碰到重复值则走insert。如果碰到重复键值则与Update语句一样
3、INSERT INTO T SELECT ... FROM S WHERE RR和serialize 加next-key读锁,RC隔离级别不加锁。
问题:是否每行记录都加一把锁?
满足以下条件,则会共用一把锁:
1、在同⼀个事务中进⾏加锁操作
2、被加锁的记录在同⼀个⻚⾯中
3、加锁的类型是⼀样的
4、等待状态是⼀样的
















 1645
1645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









