







机器学习: KNN学习笔记
1. 1 numpy 库
数组:array
矩阵:matrix
array.shape 获取数组行列数
tile() 函数
a = [0, 1, 2]
b = tile(a, (3, 2)) #重复3行, 2列代码说明
#!/usr/bin/env python
# -*- coding: utf-8 -*
from numpy import *
import operator
from os import listdir
import matplotlib
import matplotlib.pyplot as plt
def createDataSet():
group = array([
[1.0, 1.1],
[1.0, 1.0],
[0, 0],
[0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #获取dataSet数据的行数
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # tile: 重复行列, diffMat 得到差值
#通过三角函数公式计算距离
sqDiffMat = diffMat**2 # X²
print sqDiffMat
sqDistances = sqDiffMat.sum(axis = 1) # X² + Y²
print sqDistances
#开根获取所有点的距离
distances = sqDistances**0.5 #
print distances
#排序获取距离值从小到大的索引
sortedDistIndicies = distances.argsort()
print sortedDistIndicies
#根据距离和类别,计算出以类别key,距离为value的字典,确定出类别的频率
classCount = {}
print "---------------------------"
for i in range(k):
votellabel = labels[sortedDistIndicies[i]]
classCount[votellabel] = classCount.get(votellabel, 0) + 1
print classCount
#按照距离排序类别字典,
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
print sortedClassCount
print sortedClassCount[0][0]
return sortedClassCount[0][0]
if __name__ == "__main__":
group, labels = createDataSet()
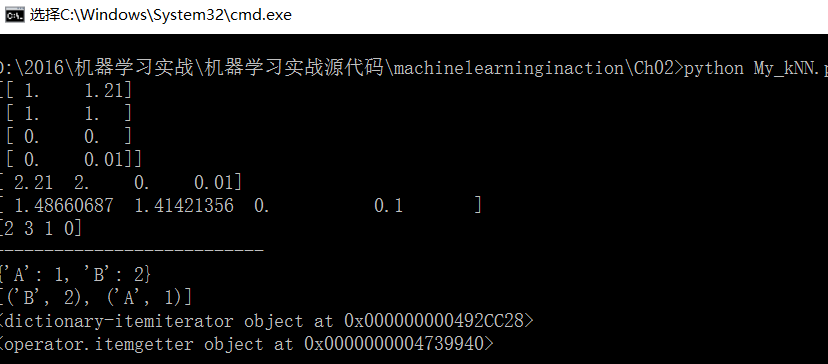
classify0([0,0], group, labels, 3)代码运行图示
第2节 数据准备
解析文本数据,输出训练样本矩阵和类标签向量
下面只是截取了部分数据
#!/usr/bin/env python
# -*- coding: utf-8 -*
# author: sfzoro@163.com
# KNN 从文件中解析海伦的约会数据
from numpy import *
import operator
from os import listdir
import matplotlib
import matplotlib.pyplot as plt
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numbersOfLine = len(arrayOLines)
returnMat = zeros((numbersOfLine, 3)) #构造空的array
print(returnMat)
classLabelVector = []
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3] #提取约会特征数据
classLabelVector.append(int(listFromLine[-1])) #提取分类标签
index += 1
print returnMat
print classLabelVector
return returnMat,classLabelVector
if __name__ == "__main__":
file2matrix("datingTestSet2_MyTest.txt")
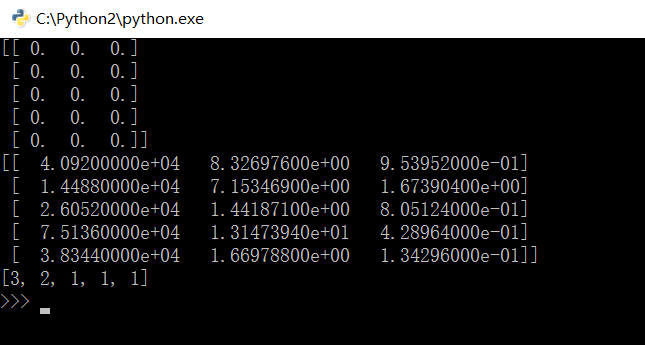
运行图示















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









