







1 下一跳的分类
路由里的下一跳分种类,但是在这里,我们可以考虑废弃cookie功能。因此,真正的下一跳信息就是两种: 出接口索引和下一跳地址。大概为以下三种组合:
<1> 出接口
<2> 出接口 + 下一跳地址
<3> 下一跳地址
其中,接口路由和主机路由,其下一跳就是<1>,IGP路由通常是<2>,而BGP路由通常是<3>,对于静态路由,三种情况皆有可能。
如果为了支持路由泄露(即VRF-A里的前缀的下一跳在VRF-B里),那么,在上面的情况中,下一跳信息中还要增加VRF-ID信息。
2 原有路由组织架构

原有的结构中,每条路由通过Ptree进行组织,以前缀为key,每个节点为rn(route-node)。每个rn下挂接ri(route-info),ri代表各种类型 路由,比如BGP路由、IS-IS路由等,路由择优时根据优先级以及下一跳有效性选择不同的ri 。每个ri下挂接一个或多个(ECMP情况下)下一跳nexthop。
原先的路由迭代,在路由变化时,会设置迭代定时器,重新从头遍历整个路由表,如果有变化的路由,那么就继续启动定时器,直至没有变化。
3 分离后的数据结构
在分离之后,需要考虑一种合适的数据组织结构和算法,来实现路由迭代问题。目前考虑以下方案:
在下一跳分离中,我们要提供一个中间变量,方便对前缀和下一跳进行关联。这个我们称之为下一跳索引。这个索引用来连接前缀和分离后的下一跳信息。也就是原先的路由表变成了分离的两部分。
原有路由表信息:【前缀(key):多个下一跳信息(value)】 —— 一种表项。
分离后路由表信息:【前缀(key):+多个下一跳索引(value)】 + 【下一跳索引(key)+真正的下一跳信息(value)
前缀表组织结构:

原有的路由表称之为前缀表,每个rn下新增一个index,称之为rn-index,uint类型,用来唯一快速索引一条路由。每个下一跳中新增nh-index,此nh-index为下一跳表组织结构的下一跳索引,可以快速查找到下一跳表。注意,如果已经存在对应下一跳,那么直接通过下一跳信息查到后获取对应的索引。
下一跳表组织结构:
下一跳表和原有的路由表一样,首先按照VRF-ID分表。对于每一个分离的下一跳表项,需要两种Key进行查找,一种是下一跳索引,一种是下一跳信息。
管理结构如下:
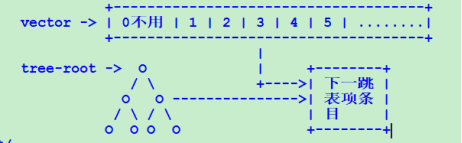
通过索引,前缀表可以快速地定位到下一跳表。通过下一跳信息,也可以查到下一跳表。在创建下一跳表时,总是知道其前缀表,因此,每个下一跳表中存储所有使用该下一跳的前缀索引(rn-index)。
4 下发转发面的数据
下发转发面的数据分为前缀表和下一跳表:
前缀表中为:前缀(key):+多个下一跳索引(value)
下一跳表中为:下一跳索引(key)+真正的下一跳信息(value)
原有的方案中,下发的都是已经迭代后的有效的下一跳,但本次分离的方案,由于中间多了一层索引,因此有多种选择:
<1> 下发有效前缀,该前缀下发所有的下一跳索引,下一跳表全部下发并在条目中指明是否有效,如果有效则条目中携带真正的下一跳(这里的真正的下一跳为迭代后的下一跳,可能存在多个下一跳路径结果)
<2> 下发有效前缀,该前缀仅下发有效的下一跳索引,下一跳表仅下发有效的下一跳,下一跳条目中仅携带真正的下一跳信息(这里的真正的下一跳为迭代后的下一跳,可能存在多个下一跳路径结果)
如果考虑到要支持IP-FRR,那么需要在前缀的value中携带主备路径信息,即需要指明哪个下一跳索引为主,哪个为备。
上述的两种选择中,<1> 控制面实现较为简单,仅需要在下发下一跳表中携带是否有效标记,并在有效的情况下把所有的路径信息包含在内。其缺点在于转发面需要再次查找后判断。<2> 控制面实现上稍微麻烦一些,在下发前缀时需要先判断一下。但是转发面可以不用再判断有效。
以上两种方法,对于ECMP的场景,由于是迭代后再有ECMP的场景,转发面的处理就有些麻烦。要解决这个问题,有两种方案,不过其核心在于增加垫层,无非是处理垫层的地方不一样。
<1> 控制面有三层表关系:前缀表–>垫层索引表–>下一跳表。前缀表的结果指向垫层,垫层索引表的结果指向下一跳表。即前缀中,原先多个下一跳会生成下一跳表和下一跳索引,现在需要为这多个下一跳分配一个垫层索引,结果为多个下一跳索引。下发转发面时,前缀表对应的结果永远只有一个索引,而下发的下一跳信息,其key为垫层表索引,value为通过下一跳索引再继续迭代后的所有的真正的下一跳信息。 此时,需要在真正的下一跳中携带FRR的主备信息。
<2> 控制面有二层表关系,转发面的表项管理进行聚合处理。即控制面还是原先的二层关系,转发面对其聚合,重新生成索引。相当于把上述的垫层做在转发面的表项管理中。
5 一种简单的迭代方法
基于3中的分离后的数据结构,迭代方案大概如下:
如果有路由发生了变化,那么就意味着其下一跳发生了变化,那么我们遍历下一跳表,如果下一跳表发生了变化,那么我们就重新更新该下一跳表中记录的关联的路由表。同时,只要有一个下一跳表发生了变化,我们就启动迭代定时器重新迭代。直至没有下一跳发生变化。
在分离后的方案中,这么做,比起原先的结构,至少节省了需要判断下一跳有效的重复计算量。
6 更加有效迭代方法
5中的迭代,有两个问题:
<1> 多路径时,多个下一跳变化引发多次处理对应的前缀表的整合下发。
<2> 路由迭代时,由于存在路由依赖关系,在一次遍历中,可能后迭代到的路由影响到之前迭代到的路由,那么就会导致再次启动定时器,再次遍历。
针对以上问题,有以下解决方案:
<1> 每次遍历时,记录需要更新的rn,在遍历结束后统一更新,避免中间同一rn的重复更新。
<2> 采用分离链表,记录不同的优先级,具体如下:
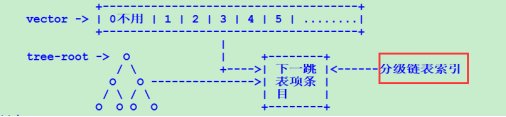
增加一条分级链表索引。将以上三种类型的出接口分别挂链,其中仅有出接口的优先级最高,出接口+下一跳IP的优先级第二,能迭代成功的下一跳IP的优先级第三(这种属于迭代路由),无法迭代出的下一跳IP的优先级最低。
在下一跳表中,除了关键的Key信息,还存了一些其他的信息:
<1>此下一跳依赖的其他的下一跳的索引集合:如果此下一跳是需要迭代的,那么就需要记录最终迭代出的那些下一跳的索引;之所以是集合,是因为在迭代后,是可能存在ECMP的情况。
<2>依赖于此下一跳的其他下一跳的索引集合:对于前两种下一跳,有可能其他的下一跳会迭代到此下一跳。
<3>依赖于此下一跳的前缀集合:注意,这里存储的集合是直接生成此下一跳的前缀,并不记录迭代前的前缀。
另外,为了提高迭代的有效性,第三种优先级可以再根据最大支持的迭代层次再细分优先级列表。根据依赖关系,被依赖者优先级高,依赖者优先级低。对于多路径依赖,按照最低的优先级来算。
7 一个例子
下面是一个例子。
1.1.1.0/24 出接口Fei-1
2.2.2.0/24 出接口Fei-2,下一跳IP 2.2.2.2
3.3.3.0/24 下一跳2.2.2.3
4.4.4.0/24 下一跳1.1.1.2 和 2.2.2.3
5.5.5.0/24 下一跳4.4.4.2
6.6.6.0/24 下一跳5.5.5.2
7.7.7.0/24 下一跳5.5.5.2
这里为了方便识别,前缀Index从1开始,下一跳Index从11开始
| 前缀Index | 前缀信息 | 前缀下一跳索引集合 | 下一跳Index | 下一跳信息 | RecurIndexs(此下一跳依赖的其他下一跳的索引) | RelatedIndexs(依赖于此下一跳的其他下一跳索引) | RnIndexs | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1.1.1.0/24 | 11 | 11 | Fei-1 | 14 | 1 | ||
| 2 | 2.2.2.0/24 | 12 | 12 | Fei-2+2.2…2 | 13 | 2 | ||
| 3 | 3.3.3.0/24 | 13 | 13 | 2.2.2.3 | 12 | 15 | 3、4 | |
| 4 | 4.4.4.0/24 | 13、14 | 14 | 1.1.1.2 | 11 | 15 | 4 | |
| 5 | 5.5.5.0/24 | 15 | 15 | 4.4.4.2 | 13、14 | 16 | 5 | |
| 6 | 6.6.6.0/24 | 16 | 16 | 5.5.5.2 | 15 | 6、7 | ||
| 7 | 7.7.7.0/24 | 16 |
下发转发面的表项如下:
下一跳表:
11:Fei-1;12:Fei-2+2.2.2.2,13:Fei-2+2.2.2.2;14:Fei-1;15:(Fei-1,Fei-2+2.2.2.2);16:(Fei-1,Fei-2+2.2.2.2)
前缀表:
1:11;2:12;3:12;4:(13,14);5:15;6:16;7:16
其中从上面可见,下一跳表还需要下两个,即只需要下直连接口路由的和IGP的。前缀表都下,但下的时候需要从前缀下一跳索引集合中迭代到最终的下一跳索引。
上述的表格是按照顺序依次而来,因此容易推算出。但在代码层面,路由6和路由5的顺序可能先有6,后有5,那么就存在迭代顺序问题。
考虑到迭代的速度,最好是先迭代直连接口的路由和IGP路由,再迭代BGP和静态路由,其中,由于BGP和静态路由又可能存在依赖性,内部最好还有依赖保障。
首先我们分了多级链,优先级最高的是接口路由和接口下一跳,其次是IGP的路由和下一条,最后才是BGP和静态路由。
如果路由发生了变化,我们先遍历1级链,然后遍历2级链。注意,从分析来看,1级链和2级链里的数据实际不一样的,并且,最终的下一跳信息就是他们的下一跳Key。从这些下一跳里的RelatedIndex中,我们可以反推出依赖于他们的路由。当把这些路由更新完后,需要继续从这些下一跳里的RelatedIndex中继续反推。
举例来说,上述路由达到稳态。然后Fei-1接口Down导致1号前缀表删除。
那么,首先我们知道11号下一跳无效。然后在1级和2级中找不到和Fei-1关联的其他下一跳,那么只取出了14号,14号依赖于11,那么14号也无效,那么15号里的依赖于14的就无效了。16依赖于15也受到影响。到16号结束。这时候,对应的路由:
前缀表:
2:12;3:12;4:(13);5:15;6:16;7:16
下一跳表1:
12:Fei-2+2.2.2.2,13:Fei-2+2.2.2.2;15:(Fei-2+2.2.2.2);16:(Fei-2+2.2.2.2)
如果路由5发生了删除,那么下一跳表中15号和16号都要删除,路由6、7也要删除,其他不动。
由上面可以看出,路由发生变化,在添加、删除或更新表时,先处理下一跳表,根据下一跳表依次处理依赖者。具体说来,动作如下:
路由添加:
先添加前缀表,同时查看是否存在下一跳表:
如果有下一跳表,则记录下一跳索引,并根据索引找到该下一跳,并更新RnIndexs,根据当前所有的下一跳信息判断是否需要下发(有有效的就下发)。此后再启动定时器,重新迭代下一跳表。——这是因为新加的路由有可能改变当前的下一跳迭代信息。
如果没有下一跳表,生成下一跳表并生成索引添加,根据下一跳类型插入到分级链中。迭代下一跳信息并生成对应的数据,注意被依赖者也要处理RelatedIndexs。下发表项。此后启动定时器,重新迭代下一跳表。
迭代下一跳表时,先处理优先级1,再处理优先级2,再处理优先级3。这时候考虑到最长匹配原则,是需要全表遍历并重新迭代。不变的略过,变化的将要记录变化然后重新继续启动定时器。重新迭代时,可能有的下一跳变有效,有的变无效,有的更改了迭代Index,这些都需要对应处理。
下一跳变有效,就重新更新对应的迭代Index,更新前缀信息和下一跳信息下发转发面
下一跳变无效,就重新更新对应的迭代Index,删除前缀信息和下一跳信息下发转发面
下一跳更新的迭代Index变化,更新下一跳表项给转发面
路由删除:
删除前缀表,同时删除相关的下一跳表的RnIndexs里的前缀Index。如果下一跳表里面的RnIndexs为空,那么下一跳表也删除。删除后启动定时器,重新迭代下一跳表。
路由更新:
更新前缀表和下一跳表,启动定时器,重新迭代下一跳表。
直到下一跳表没有变化,才不再启动定时器。此时路由收敛。
从上面的可以看出,如果能做到先处理被依赖者,再处理依赖者,那么路由就能最快地进行收敛。那么如何处理呢?从上面设计可以看出,每个下一跳有迭代的下一跳的信息。比如Index 16的下一跳迭代依赖于15, 那么16和15都知道16依赖于15。
假设,我们设置一个迭代深度,比如最多8层,那么,我们需要为其设置7层优先级链表,按照优先级把对应下一跳放在内部。迭代时,按照优先级迭代。这样,就可以最快地进行迭代。














 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









