







作者:中关村在线 濮元恺
第1页:CUDA 4.0提高多GPU效率
● CUDA带给GPU行业无限可能
2007年可以说是GPU发展史上翻天覆地的一年,在这一年微软推出了DirectX 10 API标准,将传统的Pixel Shader(顶点着色器)、Vertex Shader(像素着色器)和Geometry Shader(几何着色器),三种硬件逻辑被整合为一个全功能的统一着色器Shader。
这种API发展思路背后是微软和NVIDIA、AMD对于整个GPU发展历程的思考与转型。它标志着微软开始支持GPU走向更强的可编程性,也标志着Intel等传统CPU制造厂商在未来几年将要面对GPU的强硬挑战,越来越多的高性能计算机和超级计算机已经开始以GPU作为其运算能力提升的重要配件。

天河一号-A所采用的NVIDIA Tesla GPU
2007年同样是NVIDIA值得回忆的一年,NVIDIA公司在这一年正式推出了CUDA整套方案,它是一个完整的通用计算产品。CUDA是Compute Unified Device Architecture(统一计算架构)的简称,是建立在GPU基础之上的通用计算开发平台,它是一个全新的软硬件架构,可以将GPU视为一个并行数据计算的设备,对所进行的计算进行分配和管理。

NVIDIA提出的CUDA通用计算方案
简单分析可知,CUDA是一种以C语言为基础的平台,主要是利用显卡强大的浮点运算能力来完成以往需要CPU才可以完成的任务。这种整套方案的提出意味着程序员再也不用去钻研繁杂的底层汇编程序,而是在C语言的基础上稍加学习就能掌握CUDA并通过它来调用GPU强大的浮点运算能力。

CUDA 4.0的3个显著提升
这一版本的CUDA大幅度降低了编程难度,同时提升了GPU的编程和执行效率。CUDA 4.0主要的功能能够在Fermi架构的最新GPU上被发挥出来,同时它可以让G80、G92、GT200架构的GPU也拥有编程方式上的飞跃。
第2页:GPU统一虚拟寻址
● GPU统一虚拟寻址
在2011年2月28日,NVIDIA发布了最新版本的CUDA工具包——CUDA 4.0。借助该工具包,开发人员能够开发出在GPU上运行的并行应用程序。本次NVIDIA历经两年时间发布了CUDA 4.0版本,这一版本为我们带来了3个核心的编程与执行方式提升,它们分别是:
1、统一的虚拟寻址;
2、更直接的GPU间通信;
3、增强型C++模板库。
这3个关键性提升让更多开发人员能够利用GPU计算,它们也成为CUDA 4.0的核心提升之处。接下来我们通过NVIDIA官方公布的资料来简单分析CUDA 4.0的不同之处。
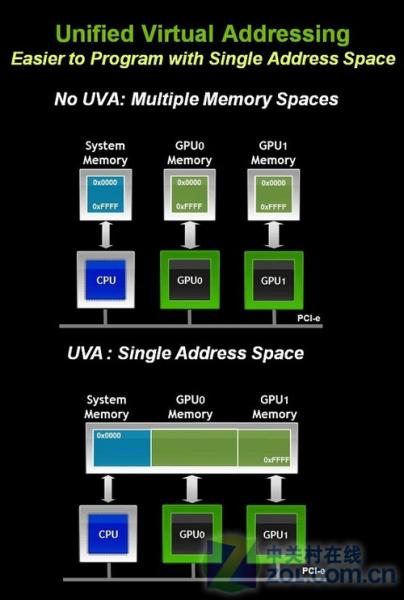
多个GPU及其显存可以被视为一体
首先提出的是“GPU统一虚拟寻址”概念,我们第一次见到这一概念在Fermi架构发布的报道中,Fermi架构带领GPU全面走向高性能计算的重要表现就在于存储体系的结构完善和GPU统一的虚拟寻址,结构部分中关村在线显卡频道之前进行了大量分析,细心的读者肯定收藏了我们的技术分析类文章。
Fermi的发布彻底统一了GPU寻址空间,将不同的寻址简化为一种指令,这在以前的的GPU中是不敢想象的,内存地址取决于存储位置:最低位是本地,然后是共享,剩下的是全局。这种统一寻址空间也是支持C++的必需前提。
本次CUDA 4.0版本的发布可以让多个GPU以及CPU统一调用GPU显存以及CPU内存,并将处理器(CPU+GPU)和存储器(内存+显存)视为统一整体。在最大显存为6GB的Tesla产品中,多CPU和多GPU融合之后可以为整个系统带来大容量存储设备并且进行统一寻址。
第3页:GPU通信和C++模板库
● GPU通信和C++模板库
多GPU通信在以前的CUDA版本中代价很大,只有专业的并行编程环境才能驱动多款GPU在同一系统内执行一个任务,而目前桌面级应用中,如果用户的多块显卡同时存在于系统中,一个CUDA加速程序往往只能调用其中一个GPU核心。

从DirectX 10到DirectX 11的多线程变化
虽然我们看到GPU在图形操作时可以有SLI速力或者CF交火能力,也有DirectX 提出的多线程渲染技术,但是高并行度的GPU通用计算领域在PC桌面级应用中反倒不能实现多款GPU联合加速。
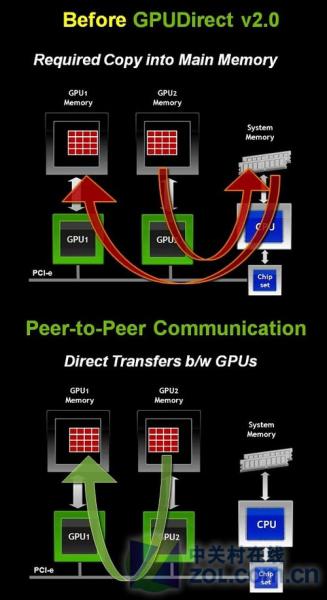
旧版的GPU Direct 1.0主要用于应用程序在网络间通信,新版的GPU Direct 2.0则转入节点内通信,支持P2P内存访问、传输和同步,代码更少,编程效率更高。在此之前,同一节点内的不同GPU互相访问,需要绕道系统内存并进行两次拷贝。 就不用理会系统内存了,不同GPU可以直接进行传输,只需要一个统一的存储体系协议NVIDIA就搞定了整个问题。
说到GPU支持C++编程大家一定不会陌生,在Fermi架构发布之时,C++模板库模板库就已经被NVIDIA不断升级。Fermi是首款支持第二代PTX指令的GPU架构,我们知道PTX 2.0使得GPU具备更强的可编程性、更精确和提供更高的性能。

Thrust C++模板化算法与数据结构
通过上图可知,Thrust C++模板化算法与数据结构提供了强大的开源C++并行算法和数据结构。类似C++ STL标准模板库;可在编译时自动选择最快的代码路径,在多核心CPU与GPU之间分配工作。
C/C++语言中所有变量和函数都是通过指针才能确定对象,这样存在编译时分离的寻址空间无法确定指针的位置而导致无法支持C/C++语言。PTX 2.0最为突出的地方在于它提供的统一寻址空间的意义,将GPU当成“共享地址空间”的并行计算机。大量的算法是基于共享地址空间平台的,这样能够显著推动GPU并行计算的发展。
第4页:CUDA 4.0引领行业如何发展
● CUDA 4.0引领行业如何发展
2011年2月28日,NVIDIA官方发布了CUDA 4.0以及全新计算开发包的各项特性,而3月5日NVIDIA正式发布了GPU通用计算开发包的CUDA 4.0 RC候选版,并提供给开发人员下载使用。

NVIDIA对自己的定位发生变化
从官方公布的资料看来,NVIDIA的确是早有打算并雄心勃勃进入并行计算市场,目前NVIDIA拥有了从Tegra到Tesla的整套芯片产品线。而这条产品线从节能高效到高性能计算全面涵盖,这的确是一家处于产业链上游的“超级”计算芯片公司。
CUDA从发布开始,到目前已经到了4.0版,从NVIDIA提出CUDA这个概念,已经有将近四年的时间,在最近一年时间CUDA发展迅速,主要是Fermi架构推出之后GPU可编程性急剧提升,GPU和CPU的差距已经越来越近,两者关系也越来越紧密。

CUDA 4个版本发展历程
上图描述了NVIDIA CUDA发布以来,从1.0版本官方大力宣传和爱好者尝试,到2.0版专用领域开始应用CUDA进行编程开发,3.0版本已经引来整个行业的关注,大量软件开始基于CUDA进行基于GPU的加速开发,到今天推出4.0版本继续降低开发难度提升开发效率。
除了上述叙述之外,我们通过资料得到CUDA 4.0架构版本还包含大量其它特性与功能,其中包括:
1、MPI与CUDA应用程序相结合——当应用程序发出MPI收发调用指令时,例如OpenMPI等改编的MPI软件可通过Infiniband与显卡显存自动收发数据。
2、GPU多线程共享——多个CPU主线程能够在一颗GPU上共享运行环境,从而使多线程应用程序共享一颗GPU变得更加轻松。
3、单CPU线程共享多GPU——一个CPU主线程可以访问系统内的所有GPU。 开发人员能够轻而易举地协调多颗GPU上的工作负荷,满足应用程序中“halo”交换等任务的需要。
4、全新的NPP图像与计算机视觉库——其中大量图像变换操作让开发人员能够快速开发出成像以及计算机视觉应用程序。
5、全新、改良的功能
Visual Profiler中的自动性能分析功能
Cuda-gdb中的新特性以及新增了对MacOS的支持
新增了对C++特性的支持,这些特性包括新建/删除以及虚拟等功能
全新的GPU二进制反汇编程序

3大核心提升能否带来CUDA 4.0飞跃式发展
目前CUDA能够有效利用GPU强劲的处理能力和巨大的存储器带宽进行图形渲染以外的计算,广泛应用于图像处理、视频传播、信号处理、人工智能、模式识别、金融分析、数值计算、石油勘探、天文计算、流体力学、生物计算、分子动力学计算、数据库管理、编码加密等领域,并在这些领域中对CPU获得了一到两个数量级的加速,取得了令人瞩目的成绩。














 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









