






是deepseek的十月怀胎,一朝分娩带来的喜悦?还是各种资本的流量捧杀,准备收割韭菜?这股AI的风,确实该歇歇了。
近期全国各家医院都在竞相本地部署deepseek,动不动就是某某地区首家!这样的标题。大多数医院都没有宣称自己部署了满血版的deepseek,从他们提供的截图中可以看出,部署的时32B或者更低的版本,是啊,1.5B也是本地部署啊,甚至有的医院还通过Chatbox接了API,然后号称云端本地化?至此,已成笑话,这场本地部署的闹剧到底何时才能休止?
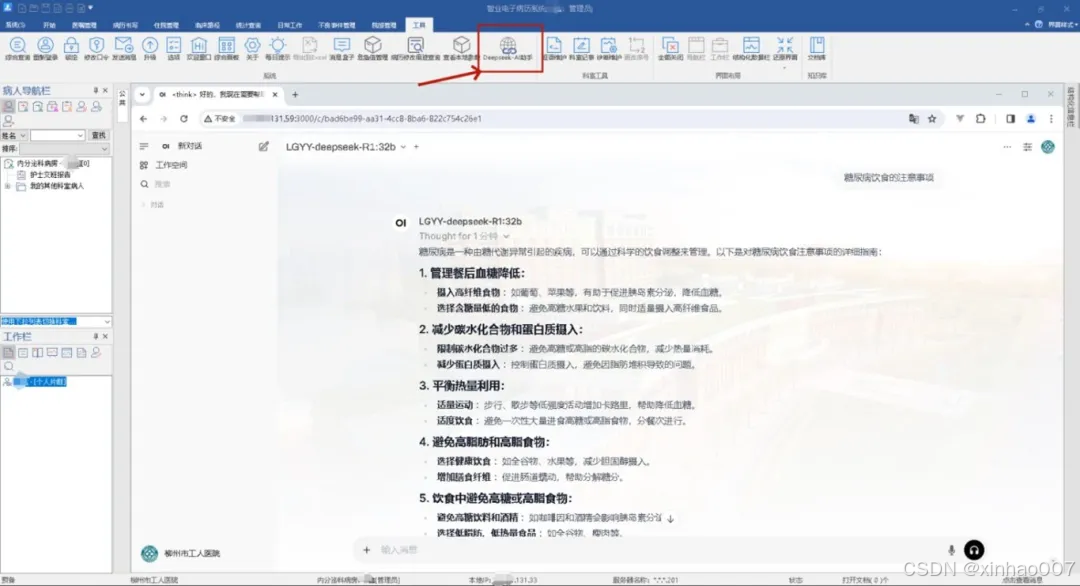
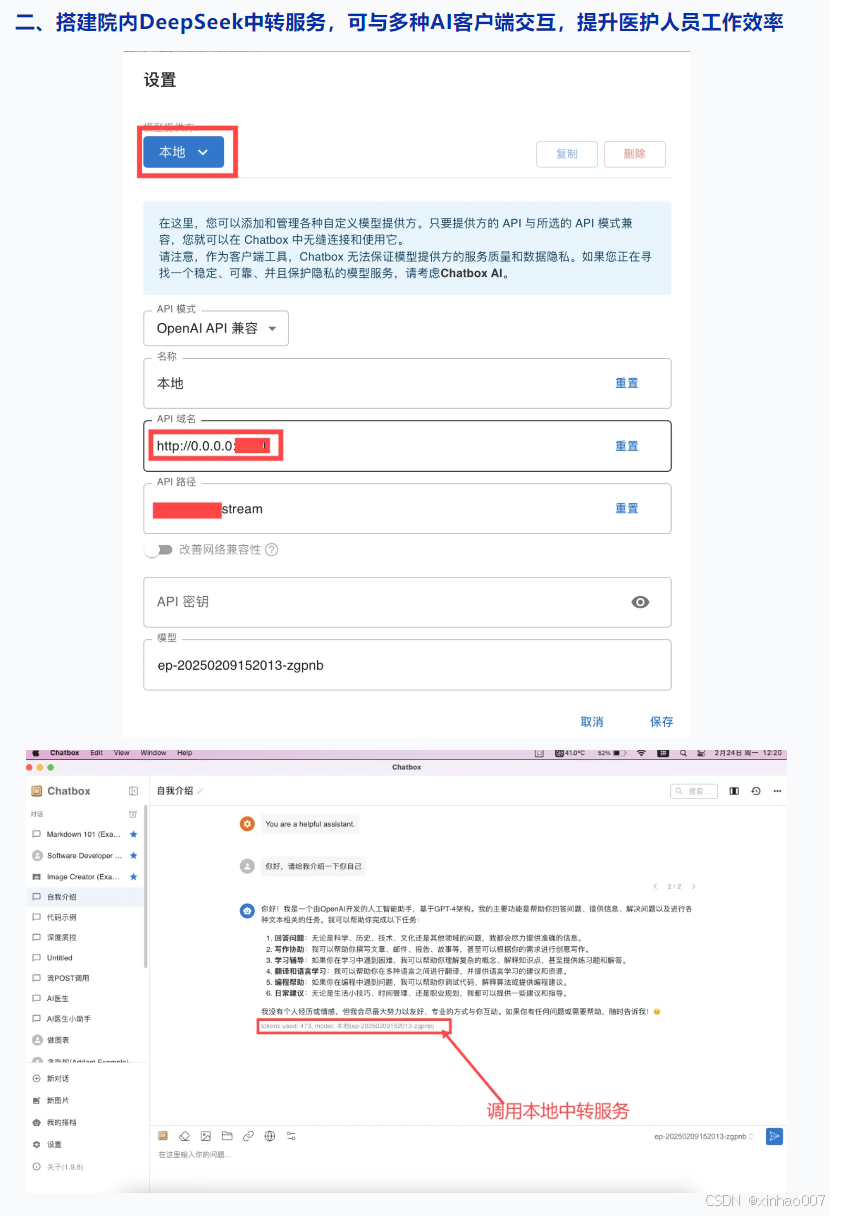
就我本人的体验而言,14B的模型压根不能用于医疗,我将处方审核的经典例题对模型进行问答,发现deepseek32B对与相互作用、重复用药的问题无法识别,V3(671B)也比较勉强,橙篇、智谱清言的在线版本识别不出处方审核的一些问题。ChatGPT对中药问题不敏感,对一些抗菌药的治疗方案偏国外的治疗方案,不适合国内。R1(在线满血版)、Kimi表现较好通过了例题考验,其中Kimi对处方审核的结果描述较为果断,对就是对错就是错,敢说。R1啰嗦的废话比较多,语言较中性,对审核的结果是建议性的,没有明确对错。
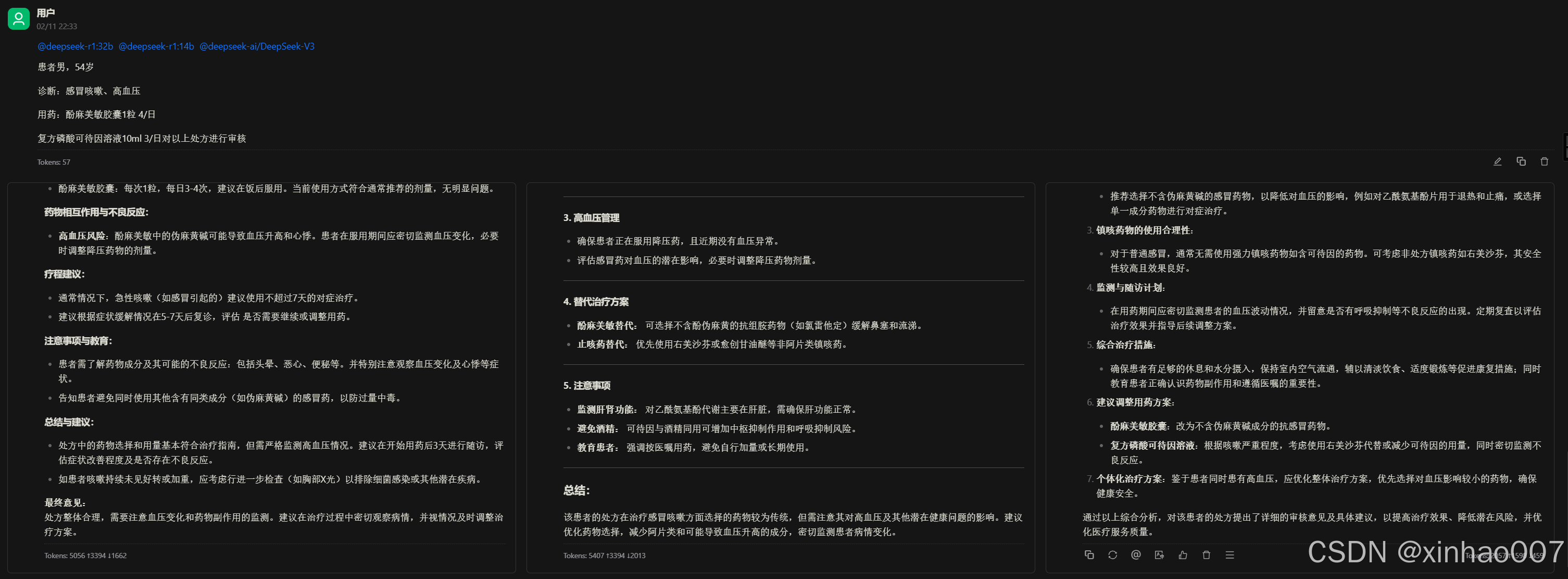
试问各家没部署满血版的医院,您本地部署的蒸馏模型真的能用?敢用?一个小小的感冒重复用药都审不出来,还指望它能做什么呢?
时间回到2024年12月,那是我第一次接触deepseek,在我所处的药学领域(个人体验感)V2模型的能力感觉与文心一言或者kimi持平,仅仅是文字输出的速度较快。后来出了V3模型,在知识库和反应速度上产生了碾压,再就是后来的R1。当时的R1确实好用,但不是现在的R1,其所含的知识库和自由度完全不可与年前的R1同日而语。
当然,也有一些国内的TOP医院做了实事,与科技公司合作训练出了垂直领域内适合诊疗的模型,这样的模型基于大量的诊疗数据,具备一定的垂直领域专业性,而绝对不是一个通用的大模型所能比拟的。
如果说真的要做,我想应该是做模型的本地部署后的蒸馏和微调,从671B采用“分层次知识蒸馏”技术,在医疗场景中兼顾泛化能力与垂直领域精准适配,然后微调后变成一个小体量的(可能仅有14B),仅含有医疗数据的垂直领域模型来用。这样不仅模型更专业化,而且还能节约设备的成本,减少显卡、内存的消耗,同时减少电力的消耗,低碳环保。
模型的幻觉问题是绝对存在的,模型使用后仍需医师药师来判断。
离开医疗领域,从宏观视角来看,AI暂时可以成为创意的加速器,作词作曲作画,无一不达到了像素级别的抄袭,很快,人类原创的那些资料都会被抄光,进入创意枯竭的时代。同时,AI的过度借鉴和抄袭,会导致人们的创造力匮乏,大家都用AI ,得出的结果都是一样的,或者如果AI被从后台知识库影响了呢?是否人们的认知会偏向某一个极端?
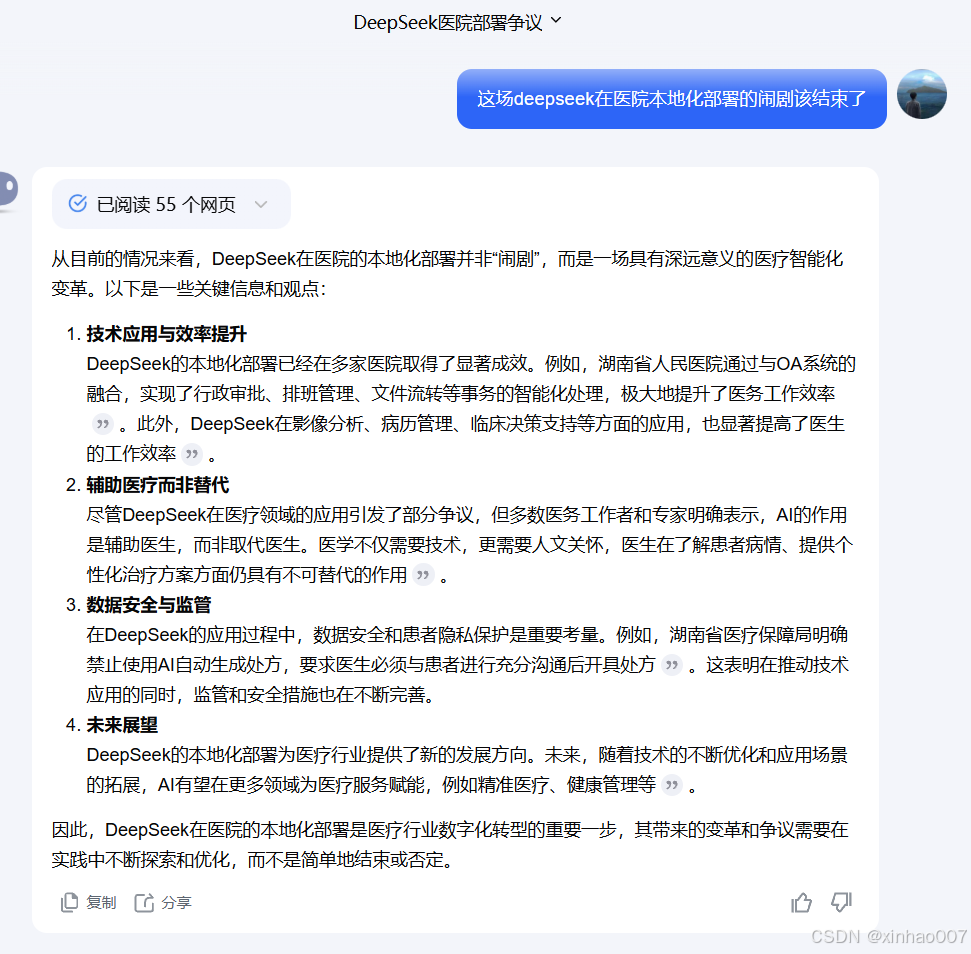
它会反驳我的想法,甚至是说服我。因为,全网铺天盖地的都是正面的宣传。行政审批?排班?文件流转?deepseek帮领导盖个章?deepseek帮我调个班?deepseek帮我把文件发给某部门?哈哈哈,简直是。。。AI的回答说了那么多,甚至一句中性的思考和评价都没有,因为它的知识库里没有,AI就像一个小孩子学习新的知识,没人告诉他这件事是错的,他便笃定的认为这件事是百分百对的。他不具备自我思考的能力,只是冰冷的硅基。
那么,未来我们该怎么做?
很简单,AI不具备创造能力,我们未来能做的就是充分发挥自己的创造力。
举个例子我用cline对接API deepseek R1写“国家集采药品管理系统”,明确的告诉了他计算公式,架构,主键等等,我满心欢喜他能写出来,但是我看到了他的思考过程,竟然参考我发表在CSDN上的文章,好嘛,能参考就是好事。但是最终他并没有写出代码,为什么呢?因为我只公开的思路,架构,但是没有告诉AI答案(代码),所谓的AI写代码,不过是东抄一段西凑一段,只要是网络上没有的代码,它就不会写出来。AI是个剽窃者。
AI会迅速拉开人与人的差距,当然是会用AI与不会用AI人的差距。当然,AI也会迅速拉平人的差距,比方说,请AI进行公文的写作, 题目一致,AI输出的大体一致,在开放的世界里,AI做到了知识平权,给了每个人迅速获取知识并整合知识的机会。
我们仍然需要有人去创造,去发明,AI很快就会挖光所有人类的知识库,人类会从当下的创意加速时代进入一个创意枯竭的时代。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









