







整理了一些Java方面的架构、面试资料(微服务、集群、分布式、中间件等),有需要的小伙伴可以关注公众号【程序员内点事】,无套路自行领取
更多优选
- 一口气说出 9种 分布式ID生成方式,面试官有点懵了
- 3万字总结,Mysql优化之精髓
- 为了不复制粘贴,我被逼着学会了JAVA爬虫
- 技术部突然宣布:JAVA开发人员全部要会接口自动化测试框架
- Redis 5种数据结构及对应使用场景,全会面试要加分的
引言
微服务、分布式大行其道的当下,中、高级Java工程师面试题中高并发、大数据量、分库分表等已经成
了面试的高频词汇,这些知识不了解面试通过率不会太高。你可以不会用,但你不能不知道,就是这么
一种现状。技术名词大多晦涩难懂,不要死记硬背理解最重要,当你捅破那层窗户纸,发现其实它也就
那么回事。
一、为什么要分库分表
关系型数据库以MySQL为例,单机的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶
颈。当单表数据量在百万以里时,我们还可以通过添加从库、优化索引提升性能。一旦数据量朝着千万
以上趋势增长,再怎么优化数据库,很多操作性能仍下降严重。为了减少数据库的负担,提升数据库响
应速度,缩短查询时间,这时候就需要进行分库分表。
二、如何分库分表
分库分表就是要将大量数据分散到多个数据库中,使每个数据库中数据量小响应速度快,以此来提升数
据库整体性能。核心理念就是对数据进行切分(Sharding),以及切分后如何对数据的快速定位与整合。
针对数据切分类型,大致可以分为:垂直(纵向)切分和水平(横向)切分两种。
1、垂直切分
垂直切分又细分为垂直分库和垂直分表
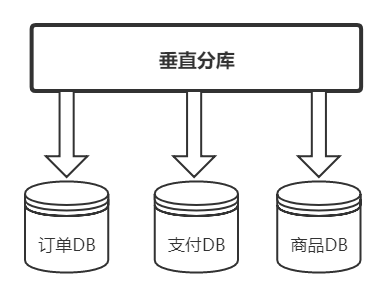
垂直分库
垂直分库是基于业务分类的,和我们常听到的微服务治理观念很相似,每一个独立的服务都拥有自己的
数据库,需要不同业务的数据需接口调用。而垂直分库也是按照业务分类进行划分,每个业务有独立数
据库,这个比较好理解。
垂直分表
垂直分表是基于数据表的列为依据切分的,是一种大表拆小表的模式。
例如:一个order表有很多字段,把长度较大且访问不频繁的字段,拆分出来创建一个单独的扩展表work_extend进行存储。
order表:
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(2000) |
拆分后
order核心表:
| id | workNo | price | … |
|---|---|---|---|
| int(12) | int(2) | int(15) |
work_extend表:
| id | workNo | describe | … |
|---|---|---|---|
| int(12) | int(2) | varchar(2000) |
数据库是以行为单位将数据加载到内存中,这样拆分以后核心表大多是访问频率较高的字段,而且字段
长度也都较短,可以加载更多数据到内存中,增加查询的命中率,减少磁盘IO,以此来提升数据库性能。
优点:
- 业务间解耦,不同业务的数据进行独立的维护、监控、扩展
- 在高并发场景下,一定程度上缓解了数据库的压力
缺点:
- 提升了开发的复杂度,由于业务的隔离性,很多表无法直接访问,必须通过接口方式聚合数据,
- 分布式事务管理难度增加
- 数据库还是存在单表数据量过大的问题,并未根本上解决,需要配合水平切分
2、水平切分
前边说了垂直切分还是会存在单表数据量过大的问题,当我们的应用已经无法在细粒度的垂直切分时,
依旧存在单库读写、存储性能瓶颈,这时就要配合水平切分一起了。
水平切分将一张大数据量的表,切分成多个表结构相同,而每个表只占原表一部分数据,然后按不同的条件分散到多个数据库中。
假如一张order表有2000万数据,水平切分后出来四个表,order_1、order_2、order_3、order_4,每张表数据500万,以此类推。
order_1表:
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
order_2表
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
order_3表
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
order_4表
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
水平切分又分有库内分表和分库分表
库内分表
库内分表虽然将表拆分,但子表都还是在同一个数据库实例中,只是解决了单一表数据量过大的问题,并没有将拆分后的表分布到不同机器的库上,还在竞争同一个物理机的CPU、内存、网络IO。
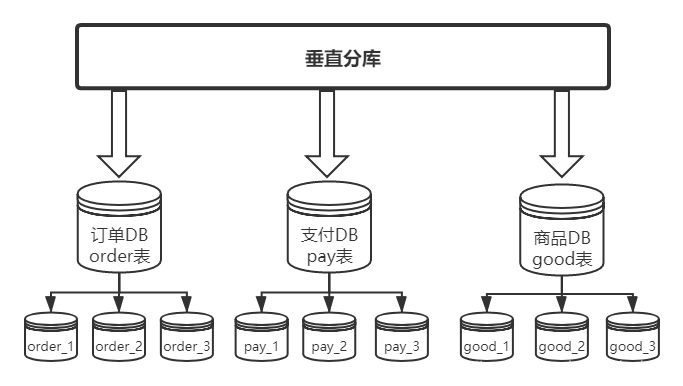
分库分表
分库分表则是将切分出来的子表,分散到不同的数据库中,从而使得单个表的数据量变小,达到分布式的效果。
优点:
- 解决高并发时单库数据量过大的问题,提升系统稳定性和负载能力
- 业务系统改造的工作量不是很大
缺点:
- 跨分片的事务一致性难以保证
- 跨库的join关联查询性能较差
- 扩容的难度和维护量较大,(拆分成几千张子表想想都恐怖)
三、数据该往哪个库的表存?
分库分表以后会出现一个问题,一张表会出现在多个数据库里,到底该往哪个库的表里存呢?
1、根据取值范围
按照时间区间或ID区间来切分,举个栗子:假如我们切分的是用户表,可以定义每个库的User表里只存10000条数据,第一个库userId从1 ~ 9999,第二个库10000 ~ 20000,第三个库20001~ 30000…以此类推。
优点:
- 单表数据量是可控的
- 水平扩展简单只需增加节点即可,无需对其他分片的数据进行迁移
- 能快速定位要查询的数据在哪个库
缺点:
- 由于连续分片可能存在数据热点,如果按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
2、hash取模
hash取模mod(对hash结果取余数 (hash() mod N))的切分方式比较常见,还拿User表举例,对数据库从0到N-1进行编号,对User表中userId字段进行取模,得到余数i,i=0存第一个库,i=1存第二个库,i=2存第三个库…以此类推。
这样同一个用户的数据都会存在同一个库里,用userId作为条件查询就很好定位了
优点:
- 数据分片相对比较均匀,不易出现某个库并发访问的问题
缺点:
- 但这种算法存在一些问题,当某一台机器宕机,本应该落在该数据库的请求就无法得到正确的处理,这时宕掉的实例会被踢出集群,此时算法变成hash(userId) mod N-1,用户信息可能就不再在同一个库中。
四、分库分表后会有哪些坑?
1、事务一致性问题
由于表分布在不同库中,不可避免会带来跨库事务问题。一般可使用"XA协议"和"两阶段提交"处理,但是这种方式性能较差,代码开发量也比较大。
通常做法是做到最终一致性的方案,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。
2、分页、排序的坑
日常开发中分页、排序是必备功能,而多库进行查询时limit分页、order by排序,着实让人比较头疼。
分页需按照指定字段进行排序,如果排序字段恰好是分片字段时,通过分片规则就很容易定位到分片的位置;一旦排序字段非分片字段时,就需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户,过程比较复杂。
3、全局唯一主键问题
由于分库分表后,表中的数据同时存在于多个数据库,而某个分区数据库的自增主键已经无法满足全局
唯一,所以此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。可
以参考我之前写的这篇文章《一口气说出 9种 分布式ID生成方式,面试官有点懵了》
五、分库分表工具?
自己开发分库分表工具的工作量是巨大的,好在业界已经有了很多比较成熟的分库分表中间件,我们可
以将更多的时间放在业务实现上
- sharding-jdbc(当当)
- TSharding(蘑菇街)
- Atlas(奇虎360)
- Cobar(阿里巴巴)
- MyCAT(基于Cobar)
- Oceanus(58同城) Vitess(谷歌)
今天就说这么多,如果本文对您有一点帮助,希望能得到您一个点赞👍哦
您的认可才是我写作的动力!
整理了一些Java方面的架构、面试资料(微服务、集群、分布式、中间件等),有需要的小伙伴可以关注公众号【程序员内点事】,无套路自行领取















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











