







文 | 水哥
源 | 知乎
Saying
1. 如果你面对一个全新的机器学习任务,让你来涨点。你可能第一个想到的往往是attention,第一个实现的是attention,第一个真的涨点了的技术也是attention;
2. DIN的最主要的意义,把attention引入到用户序列上,根据变化的item对象挑出合适的响应对象;
3. 别的地方还在吭哧吭哧研究embedding+DNN时,阿里妈妈啪的一下就把attention放进来了,很快啊!
这是【从零单排推荐系统】系列的第18讲。如果说机器学习有什么技巧是百试百灵,放到哪都可以用的上的话,我会推荐两个招。一是人海战术,可以理解为前面讲过的ensemble learning。
人海战术在工业推荐中做的不多,即使是决定要用,也用的很保守,复杂度控制的比较小心。到了打比赛,项目pk的时候,那可是脱了缰了。几年前ILSVRC还有的时候,上好几个模型把输出结果加起来做最终结果都只是常规操作,到了要pk那项目的时候几千个模型(当然不是CNN这种)也是有所耳闻。
二是attention,attention的发展也是比较有意思。最早的时候说自己是attention,必须得旁征博引,从生理角度分析引用了什么原理,哪里能体现出人的认知过程。到了现在,加一个系数就叫attention。不过说归说,attention确实是一种非常好用的技巧,在这一讲中我们先开个头,关于它的更多分析留在下一讲。
Deep Interest Network[1]
当其他人还在学习适应embedding+DNN这种结构的形式时,阿里妈妈这边已经在考虑更加细致的问题了。在今天看来,DIN里面使用的attention是整个机器学习领域里面几乎最直观的attention方式,其主要动机来源于对输入特征的观察,如图:
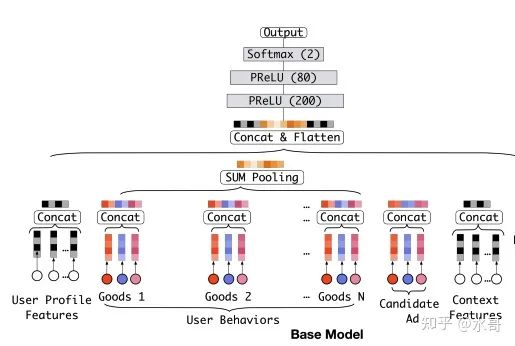
像我们上一讲提到过的,用户的特征主要有两种:一种是非序列的,可以称之为non-sequential的。这类特征往往是User ID,年龄性别城市这种(后面的可称之为profile,即一些用户画像信息)。另一种是序列化的(sequential),主要是用户的历史行为(User Behaviors),比如在电商场景下,就是用户过去购买过的产品;在短视频场景下,可以是用户过去点赞的视频。为了能顺利接下面的MLP,特征得是定长度的,所以这里序列特征要选择,最近的 个,多了截断,少了补0。
将序列特征输入MLP时,list中的每一个item都有对应的embedding,如果拼接起来,是一个巨大的长度,非常浪费空间(举个例子,最近的30个,如果每一个都是64维,这就将近2000维了。实际上现在常见的大公司的解决方案中,MLP第一层承接的输入总共也就几千维)。那么sum pooling就会是一个相对柔和的方案,可以保证特征的长度不会太长。但是sum pooling有两个缺点:
不会随着到来的广告变化而变化,无论来的是美食还是母婴产品,遇到的都是同样的历史行为表示。然而一个广告是否应该发生点击,应该更加重视对应类别的过往行为强度是否足够大。换句话说就是美食来了应该看看过往的行为中美食的行为多不多,和这个广告像不像。其他类别和当前这个广告联系并不大。所以我们需要一个动态的机制挑出需要的部分。
会对信息有所压缩,如果一个item的信息需要16维才能装得下,最后30个item的信息也只存在于16维里面的话,肯定是有压缩的。我们很难控制这个过程,或许需要的信息就刚好压缩没了。所以我们也需要一个尽量不压缩关键信息的机制。
而attention是什么呢?它就是能够动态挑出需要的部分,而且可以控制压缩的程度。所以就和上面的需求刚好对上了!这也就是DIN的最主要的意义,把attention引入到用户序列上,根据变化的item对象挑出合适的响应对象。
而为了完成这个attention,我们要决定(1)挑选出来的部分根据谁来变化(2)最终融合的形式。根据上面说的,为了要适应广告的变化,当然要把当前的广告信息作为输入,除此之外,用户本身的历史序列当然也是。对于第二个问题,我们最终还是希望结果的维度和sum pooling差不多,因此加权和是一个好的选择,这也是大多数attention的做法。综合以上两点,就得到:
其中 就对应序列中第 个item的embedding,而 是对应的attention系数。得到的结果是一个定长的向量,再和其他特征的embedding一起拼接起来,作为MLP的输入即可。这里没有对attention系数做归一化,主要是考虑到scale其实反映了兴趣的强度。加上attention的图如下所示,其中attention部分用红框突出了一下:
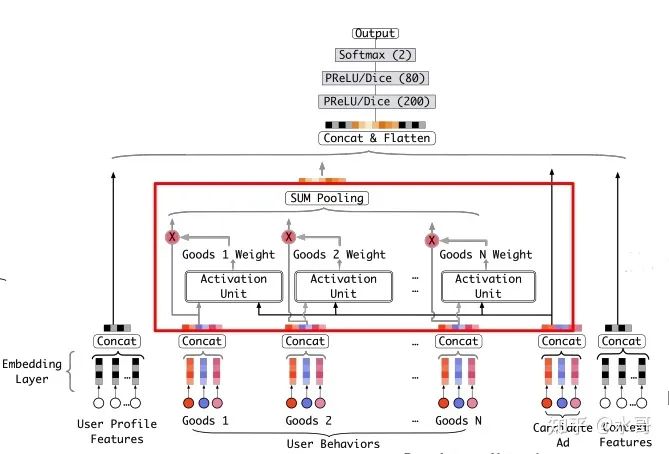
至此对DIN的思想和主要的实现就梳理完成了,还留着的一个细节是上面的attention系数怎么得到。其网络结构如下:
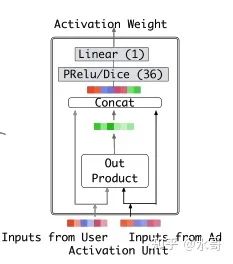
这个图画的不是很清楚,外积之后得到的应该是一个矩阵,然后得到中间绿色的向量是通过什么方式(乘以 还是拉平)?这里还是按照代码里面的逻辑来介绍[2]。item侧的输入是 的,这里 就是embedding的大小,比如64. user侧的输入是 ,第二项是序列的长度。先把item扩充成和user形状一样,然后把item,user,item-user,item*user四个张量在最后一维拼接。拼接后的张量经过FC层,一直映射到1,那么此时剩下的是 的结果了。这里的分数就是我们要的attention分数,拿它和user的list做一个矩阵乘法即可(还有一些别的操作,这里就省略掉了)。
Deep Interest Evolution Network[3]
有了DIN的基础,我们理解DIEN就更加容易。DIEN的主要出发点是,用户的历史行为体现了他自身兴趣的变化,而这个过程本身是时序的。而且这是一个发展的过程,这也就是题目中evolution的由来。
既然用户的序列是时序发生的,使用RNN,GRU和LSTM就显得非常自然。这里选择的是不容易梯度消失且较快的GRU。整体架构如下图所示:

图中的 是用户的行为序列,而 是对应的embedding。随着自然发生的顺序, 被输入GRU中,如果忽略上面的AUGRU环节,GRU中的隐状态 就应该成为用户的行为序列最后的表示。这部分就是两大组成部分之一的Interest Extractor Layer。
如果直白的做,也是可以的,但是会训练的不够“细”。 的迭代经过了很多步,然后还要和其他特征做拼接,然后还要经过MLP。这样的结果就是最后来了一个正样本,归因不到 上,整个网络感觉一团浆糊。基于此DIEN给出了第一个要点:使用辅助loss来强化 。
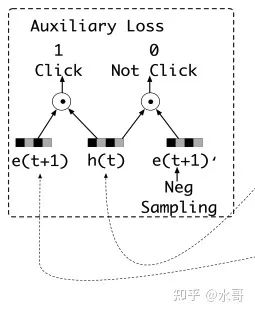
上面详细画了一下辅助loss的做法,我们本质上认为,如果发生了点击,那么当前的 和即将到来的广告的embedding应该很像。也就是 时刻得到的隐状态 和下一个要来的点击广告 要相近。可以对它们做内积然后求最大。仅仅是这样还不够,还可以采样一些不出现在历史序列的广告,构成负样本 ,然后和 内积后取最小。通过这个辅助的loss,让隐状态开始富有语义:点击与否能具体的归因到某一个时刻的状态上。
辅助loss的作用
当我看到DIEN使用了辅助loss的时候,就觉得很靠谱了。根据我的经验,辅助任务往往能带来好处。真正应用场合下,你把开始的输入和最后的要求告诉网络,他就能给你一个好的结果的情况非常少。大多数时候是需要你去控制每一步的输入输出,每一步的loss才能防止网络各种偷懒作弊。辅助loss(1)能够使得网络更受控制,向我们需要的方向发展;(2)能够把正负样本的原因更清晰的归因到特征层面。
我非常建议大家在实际业务中多试试辅助loss
GRU的部分体现了对于行为信息的一种更高阶的抽取,但是对于evolution体现的还不够强。于是需要第二个模块Interest Evolving Layer来完成。具体来说,兴趣的发展可以等价为attention的变化,在GRU的不同位置加入attention,则体现了不同的发展方式。
attention在这里的计算方式是:
和状态以及当前item都有关系。在GRU中有三个地方可以放如attention,
对隐状态乘上attention,称为AIGRU
改变update gate为attention系数,称为AGRU
改变update gate为原来的gate乘以attention,就是AUGRU了,这是效果最好的选择。含义也很清楚,attention决定了现在的兴趣转变有多快
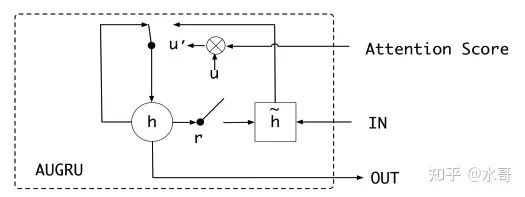
上面就是AUGRU的示意图,先和原来的update gate相乘,再以这个gate控制隐状态的更新。
为什么人海战术总是有用?
在本讲和下一讲我们分别思考两个问题,第一个问题是,为什么人海战术总是有用的,第二个问题是,为什么attention总是有效的。在这一讲中我们先尝试回答第一个问题,第二个问题留到下一讲来阐述。
我们这里举一个例子来理解一下,如果一个分类器在某个样本上得到正确输出的概率为 ,那么有 个分类器时(简单起见,假设他们平均意义上的概率差不多),按照投票制度获得正确输出的种类为 ,这里忽略打平的情况,所以 都取奇数。而总体的情况则是 . 我们可以验证一下,是否存在
如果存在这个关系,那我们可以说,经过人海战术,我们获得了更好的结果。下面的表格对不同的 和 的取值代入进行计算,我们可以发现前一项的概率确实相对于原来都获得了提升。
| n=3 | n=5 | n=7 | |
|---|---|---|---|
| p=0.6 | 0.648 | 0.683 | 0.710 |
| p=0.7 | 0.784 | 0.837 | 0.874 |
| p=0.8 | 0.896 | 0.942 | 0.967 |
| p=0.9 | 0.972 | 0.991 | 0.997 |
但是要强调一点,人海战术并不是没有条件的,我这里总结的情况是原分类器均匀地有在样本上能超过半数的判对,才能提升效果(这个条件没有经过证明,读者可以当做是辅助理解的条件)。比如说有三个分类器,分别在三个样本上输出 , , ,单独选一个都可以得到33%的正确率,但是大家合起来却变成了0%。但是如果这个概率分布能够变的更平均一点,变成 , , ,这样正确率变成了100%,像后面这样的情况人海战术才能有用。不过实际中我们遇到的也都是后面的情况,像前面这种非常畸形的分布很难遇见。
这一讲的DIN+DIEN这两个方案在实现上完全可以由后续要讲的基于transformer来替换。但重要的是我们要体会这其中思考的过程。DIN出现的时候,大多数人可能连embedding+DNN是什么都没搞清楚(也可以说,大多数人还在搞CV/NLP,哈哈),而DIN就抓住了用户行为信息和用户画像信息结构上不协调的点,深挖了attention的操作。在DIN把attention告诉大家后,DIEN又换了一个思路,从行为发生的时序上进行研究。这一系列的工作从来都不是别人发表了什么我就用什么,而是我的系统缺什么我就开发什么,这是最需要上一讲的逍遥派学习的地方。
思考题
sum pooling并不是一定就会损失信息的,这一点在DIN的论文中也说了,embedding维度越高,sum pooling保留的信息就可以越多。如何理解这句话?你能设计一个embedding使得sum pooling之后没有信息损失吗?
下期预告
推荐系统精排之锋(13):Attention有几种写法?
往期回顾
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1]Deep Interest Network for Click-Through Rate Prediction,KDD,2018 https://arxiv.org/pdf/1706.06978.pdf
[2]https://github.com/zhougr1993/DeepInterestNetwork/blob/9765f96202f849e59ff260c8b46931a0ddf01d77/din/model.py#L200
[4]Deep Interest Evolution Network for Click-Through Rate Prediction,AAAI,2019 https://arxiv.org/pdf/1809.03672.pdf
















 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









