






原创 小道仙97 小道仙97 2024-04-03 14:00 广东
-
1、准备
-
2、源码阅读
-
2-1、对使用@RocketMQMessageListener的类进行增强,生成监听器ListenerContainer,并启动
-
2-2、基于顺序消费和并发消费创建对应的Service,创建处理消息的的线程池
-
2-3、拉消息和负载均衡的开始
-
2-4、队列和消费者之间的负载均衡
-
2-5、拉消息
-
-
3、总结
上一遍学习了三种常见队列的消费原理,本次我们来从源码的角度来证明上篇中的理论。
1、准备
RocketMQ 版本
<!-- RocketMQ -->
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.3.0</version>
</dependency>
消费者代码
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.springframework.stereotype.Component;
@Component
@RocketMQMessageListener(consumerGroup = "my-consumer_asyn-topic", topic = "rocketmq-topic")
public class RocketmqConsumer1 implements RocketMQListener<MessageExt> {
@Override
public void onMessage(MessageExt messageExt) {
byte[] body = messageExt.getBody();
System.out.println("RocketMQ 001" + new String(body));
}
}
2、源码阅读
2-1、对使用@RocketMQMessageListener的类进行增强,生成监听器ListenerContainer,并启动
在 RocketMQMessageListener 包下面有一个 Bean后置处理器,会对每个使用了 @RocketMQMessageListener 的类进行增强,生成 监听器,并启动这个监听器
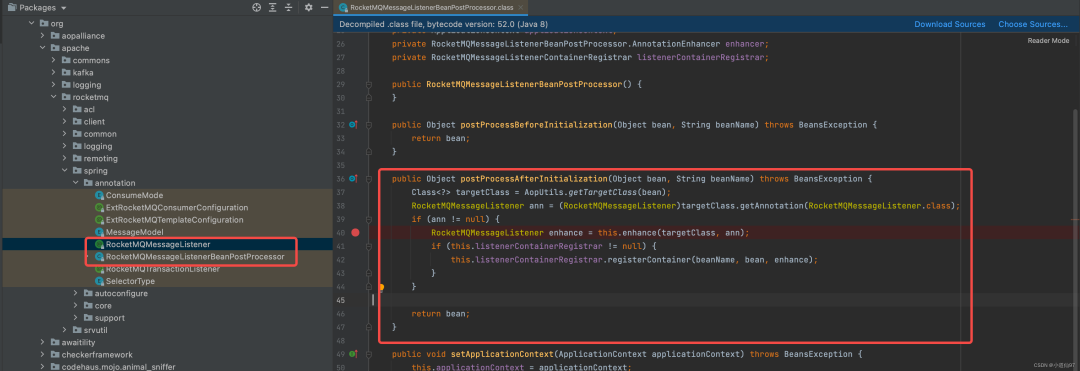
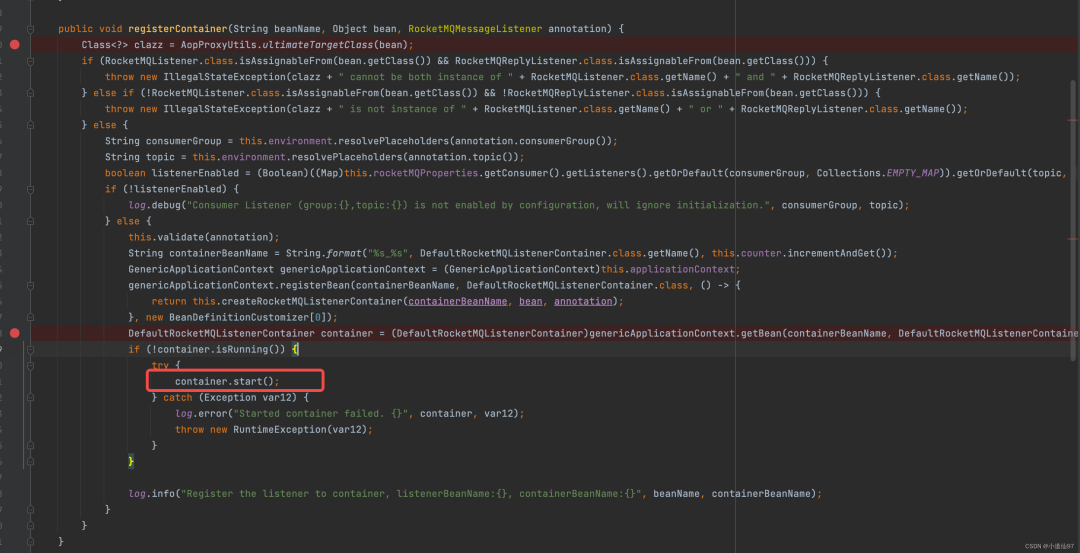
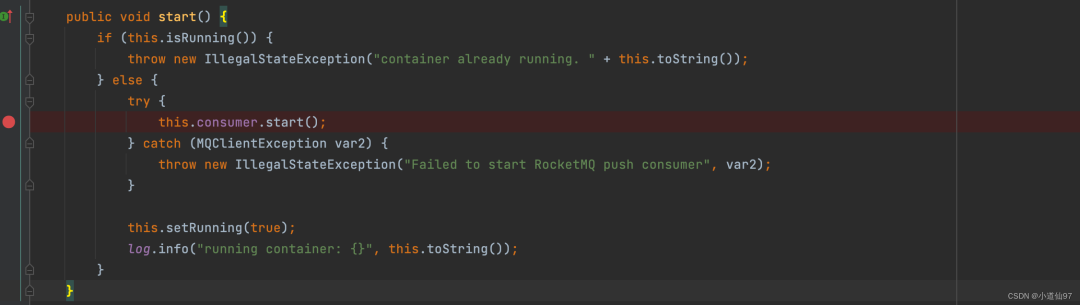
在这里插入图片描述

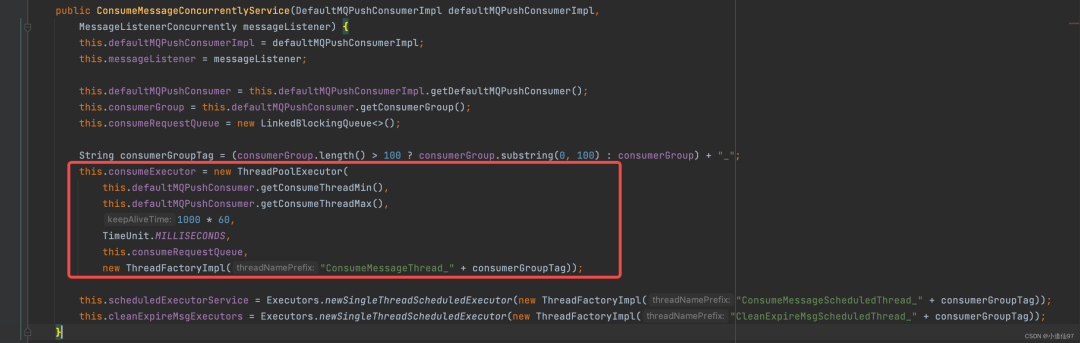
2-2、基于顺序消费和并发消费创建对应的Service,创建处理消息的的线程池
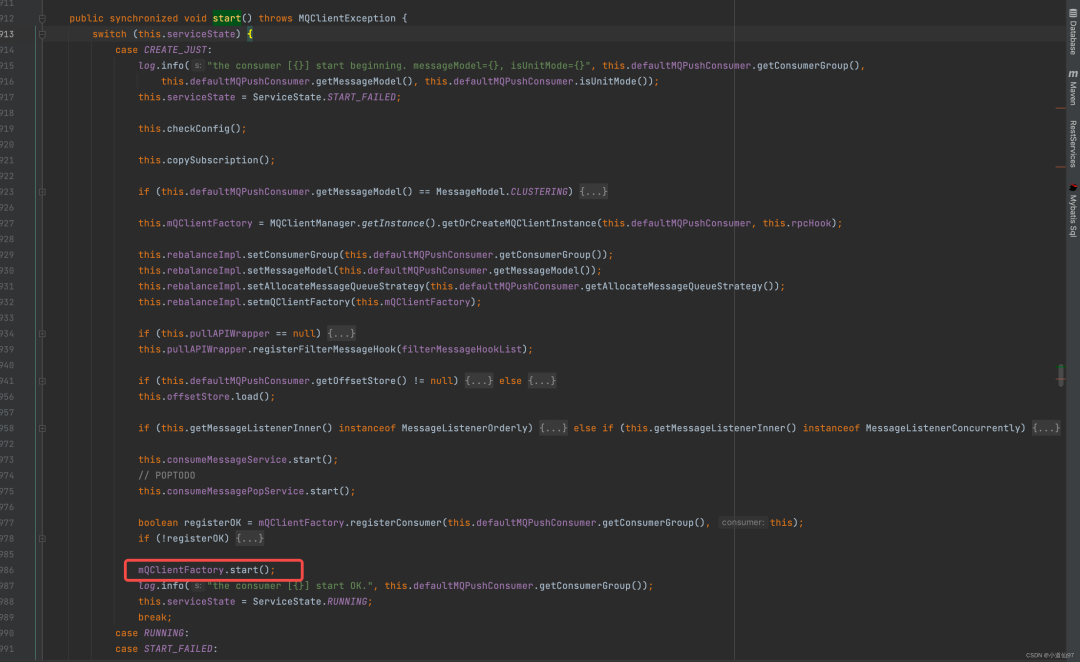
org.apache.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl#start 这个方法很长,这里简化一下来看看我们比较关注的几个点,详情看源码
// 默认就是 CREATE_JUST
private volatile ServiceState serviceState = ServiceState.CREATE_JUST;
public synchronized void start() throws MQClientException {
switch (this.serviceState) {
case CREATE_JUST:
// ... 省略 ...
// 如果是顺序消费就创建顺序消费的 监听器 ConsumeMessageOrderlyService
if (this.getMessageListenerInner() instanceof MessageListenerOrderly) {
this.consumeOrderly = true;
this.consumeMessageService = new ConsumeMessageOrderlyService(this, (MessageListenerOrderly) this.getMessageListenerInner());
}
// 创建并发消费的监听器 ConsumeMessageConcurrentlyService
else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) {
this.consumeOrderly = false;
this.consumeMessageService = new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently) this.getMessageListenerInner());
}
// ... 省略 ...
// 把当前的消费者组和消费者存入本地的 ConcurrentHashMap
boolean registerOK = mQClientFactory.registerConsumer(this.defaultMQPushConsumer.getConsumerGroup(), this);
// ... 省略 ...
// 进行下一步的启动
mQClientFactory.start();
log.info("the consumer [{}] start OK.", this.defaultMQPushConsumer.getConsumerGroup());
this.serviceState = ServiceState.RUNNING;
break;
// ... 省略 ...
}
// ... 省略 ...
}
上篇讲到RocketMQ消费的模式是一个线程去不停的拉消息,然后丢到一个线程池里面去消费,刚刚我们看到根据是否是顺序消费,创建不同的 service,这个线程池就是在这个地方创建的。
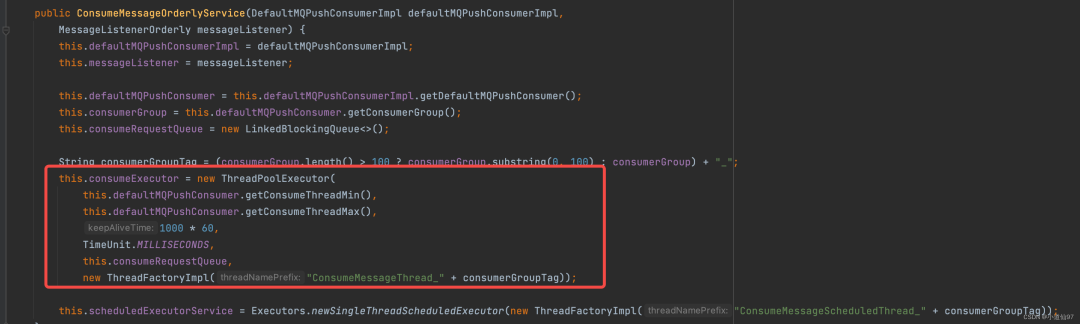
在这里插入图片描述
在这里插入图片描述
注: 默认情况下,consumeThreadMin = 20 、consumeThreadMax = 64
2-3、拉消息和负载均衡的开始
在这里插入图片描述
在这里插入图片描述
2-4、队列和消费者之间的负载均衡
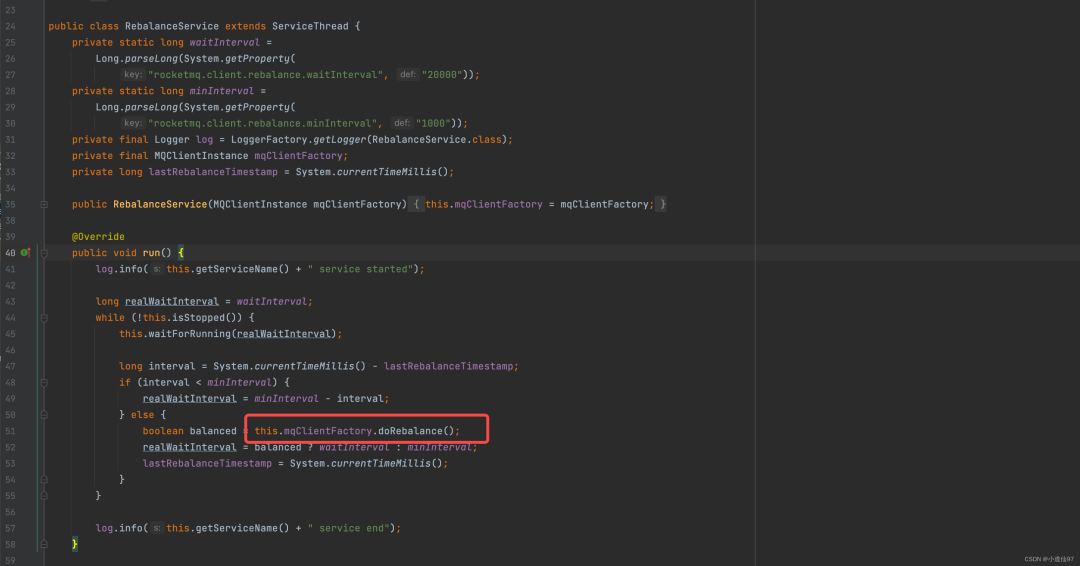
虽然拉消息的代码在前面,但没有关系,负载和拉消息都是新开启线程去执行,我个人觉得负载均衡放在前面讲更合适一些
一个topic中的queue数量大多数时候是固定的,但消费者却不是,很多时候我们会动态的去调整消费者的数量,而在上一期的理论中得知消费组中的消费者数量如果大于queue的数量是没用的,下面通过源码来看它是如何实现的
this.rebalanceService.start();
在这里插入图片描述
循环遍历每一个消费者去负载均衡
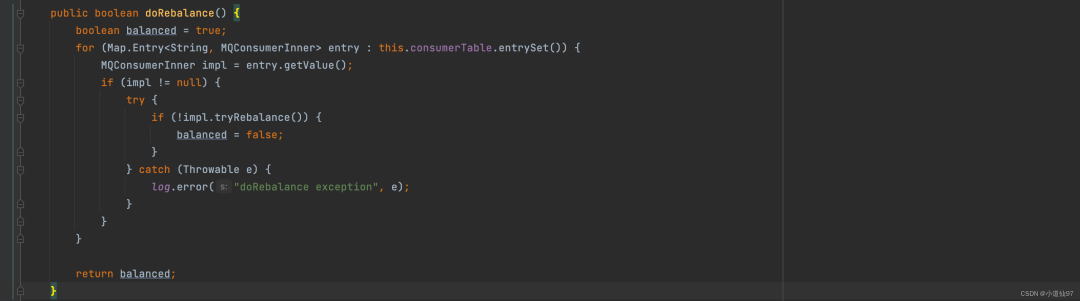
在这里插入图片描述
consumerTable 数据的由来参看【2-4-1、consumerTable 数据的由来】
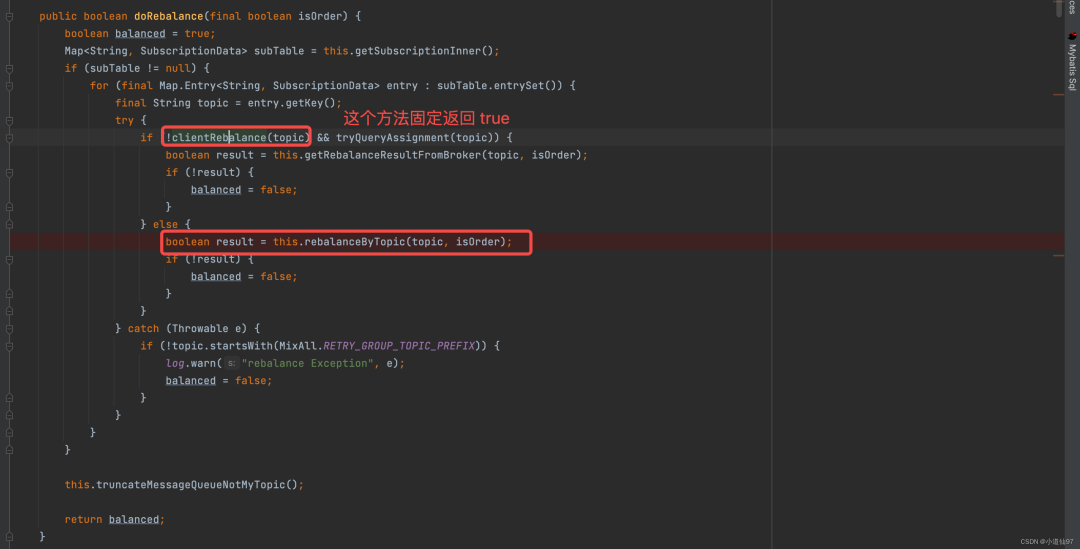
负载的核心代码 rebalanceByTopic
消费模式有集群消费和广播消费,负载均衡肯定是基于:集群消费
private boolean rebalanceByTopic(final String topic, final boolean isOrder) {
boolean balanced = true;
switch (messageModel) {
case BROADCASTING: {
// ... 省略 ...
}
case CLUSTERING: {
// 获取当前 topic 的 queue
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
// 发起 netty请求,获取当前组下面的消费者
List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);
// ... 省略 ... 参数校验
if (mqSet != null && cidAll != null) {
List<MessageQueue> mqAll = new ArrayList<>();
mqAll.addAll(mqSet);
Collections.sort(mqAll);
Collections.sort(cidAll);
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
// 使用策略进行分配,默认的策略是平均分配
allocateResult = strategy.allocate(this.consumerGroup,this.mQClientFactory.getClientId(), mqAll, cidAll);
} catch (Throwable e) {
log.error("allocate message queue exception. strategy name: {}, ex: {}", strategy.getName(), e);
return false;
}
Set<MessageQueue> allocateResultSet = new HashSet<>();
if (allocateResult != null) {
allocateResultSet.addAll(allocateResult);
}
// 对分配的结果进行 设置
boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);
if (changed) {
log.info(
"client rebalanced result changed. allocateMessageQueueStrategyName={}, group={}, topic={}, clientId={}, mqAllSize={}, cidAllSize={}, rebalanceResultSize={}, rebalanceResultSet={}",
strategy.getName(), consumerGroup, topic, this.mQClientFactory.getClientId(), mqSet.size(), cidAll.size(),
allocateResultSet.size(), allocateResultSet);
this.messageQueueChanged(topic, mqSet, allocateResultSet);
}
balanced = allocateResultSet.equals(getWorkingMessageQueue(topic));
}
break;
}
default:
break;
}
return balanced;
}
-
如何进入rebalanceByTopic,参看【2-4-2、进入 rebalanceByTopic】
-
默认的平均分配策略如何执行的,参看【2-4-3、平均分配策略原理】
-
分配结果参看【2-4-4、重置队列和消费者之间的关系】
2-4-1、consumerTable 数据的由来
在【2-3、拉消息和负载均衡的开始】开始的第一张图中 start开始之前执行了一个 registerConsumer 方法,这个方法就是把当前消费者和其组 consumerTable

2-4-2、进入 rebalanceByTopic
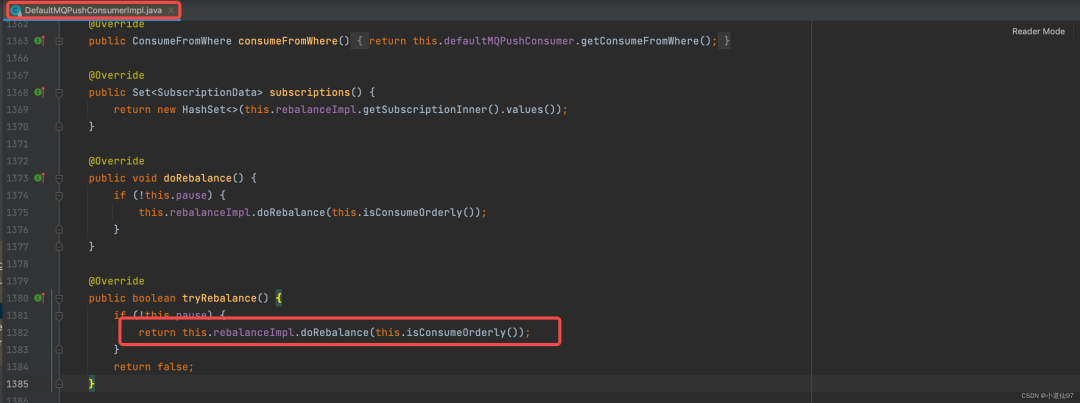
2-4-3、平均分配策略原理
-
这里假设当前queue只有 1个,消费者有 2个,当前消费者是第一个
-
下面的 index 、mod 等其它参数都是基于这个假设来计算的
public class AllocateMessageQueueAveragely extends AbstractAllocateMessageQueueStrategy {
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List<MessageQueue> result = new ArrayList<>();
if (!check(consumerGroup, currentCID, mqAll, cidAll)) {
return result;
}
// index = 1
int index = cidAll.indexOf(currentCID);
// mod = 2
int mod = mqAll.size() % cidAll.size();
// averageSize = 1
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
// startIndex = 1
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
// range = 0
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
// result 为空数组
return result;
}
@Override
public String getName() {
return "AVG";
}
}
通过上面的计算可以得出,当消费者的数量大于队列数量的时候,返回值是 空数组
2-4-4、重置队列和消费者之间的关系
重置的操作分三步
-
删除进程中与当前消费者绑定的队列
-
删除broker中的绑定的关系
-
建立新的关系
private boolean updateProcessQueueTableInRebalance(final String topic, final Set<MessageQueue> mqSet,
final boolean isOrder) {
boolean changed = false;
// 删除进程中与当前消费者绑定的队列
HashMap<MessageQueue, ProcessQueue> removeQueueMap = new HashMap<>(this.processQueueTable.size());
Iterator<Entry<MessageQueue, ProcessQueue>> it = this.processQueueTable.entrySet().iterator();
while (it.hasNext()) {
Entry<MessageQueue, ProcessQueue> next = it.next();
MessageQueue mq = next.getKey();
ProcessQueue pq = next.getValue();
removeQueueMap.put(mq, pq);
// ... 删除操作 ...
}
// 删除broker中的绑定的关系
for (Entry<MessageQueue, ProcessQueue> entry : removeQueueMap.entrySet()) {
MessageQueue mq = entry.getKey();
ProcessQueue pq = entry.getValue();
if (this.removeUnnecessaryMessageQueue(mq, pq)) {
this.processQueueTable.remove(mq);
changed = true;
log.info("doRebalance, {}, remove unnecessary mq, {}", consumerGroup, mq);
}
}
// 建立新的关系
boolean allMQLocked = true;
List<PullRequest> pullRequestList = new ArrayList<>();
for (MessageQueue mq : mqSet) {
// ... 建立新的关系 ...
// 并把新的结果存入 pullRequestList 这很重要
}
if (!allMQLocked) {
mQClientFactory.rebalanceLater(500);
}
// 基于新的绑定关系去获取消息
this.dispatchPullRequest(pullRequestList, 500);
return changed;
}
如果上一步的平均分配的结果为 空数组,那在这里就会删除所有的绑定关系,并且无法建立新的关系,也就说明当消费组中的消费者的数量大于queue的数量是无用的
dispatchPullRequest,这个方法的实现类只有如下代码
@Override
public void dispatchPullRequest(final List<PullRequest> pullRequestList, final long delay) {
for (PullRequest pullRequest : pullRequestList) {
if (delay <= 0) {
this.defaultMQPushConsumerImpl.executePullRequestImmediately(pullRequest);
} else {
this.defaultMQPushConsumerImpl.executePullRequestLater(pullRequest, delay);
}
}
}
这个操作的最终结果就是把 pullRequest,放入 messageRequestQueue 中,delay不为空的时候,会开启一个定时认为每隔delay时间往messageRequestQueue里面塞一次, 这个点很重要
如果分配给当前消费者处理的 queue有2个,那这里就会生成两个 pullRequest
2-5、拉消息
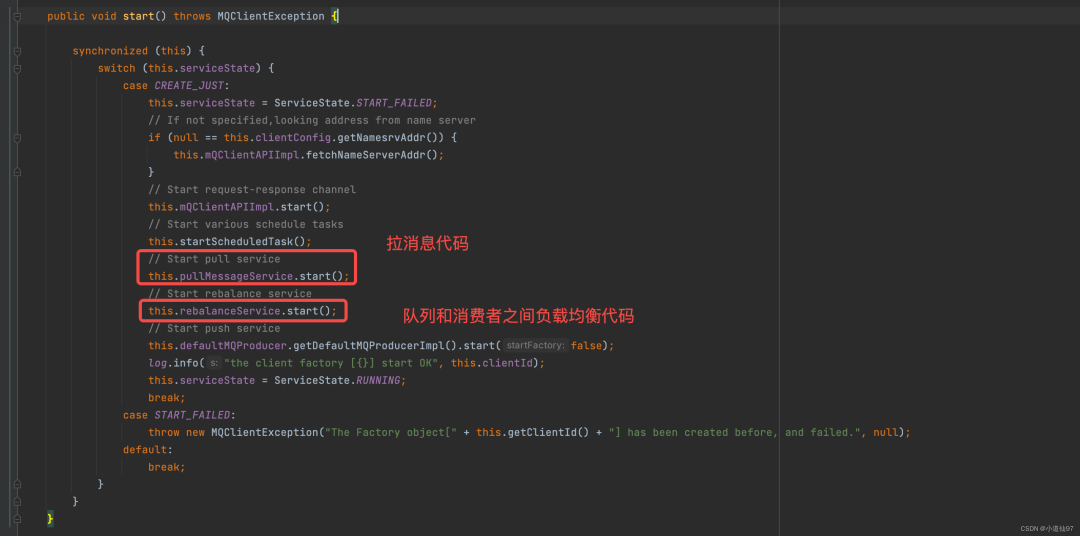
解释完负载均衡,让我们再次回到【2-3】,现在来看看2-3提到的拉消息逻辑
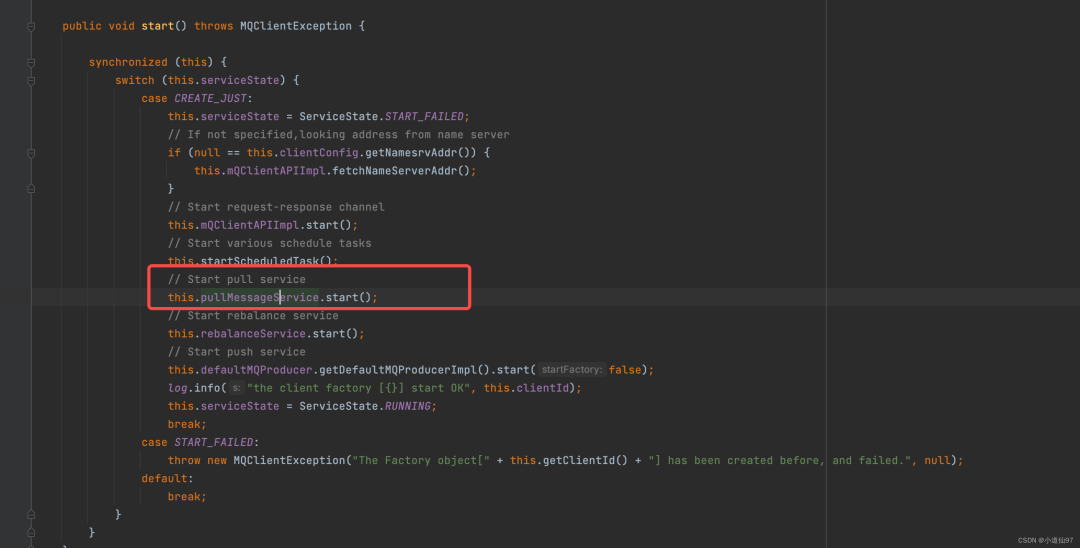
在这里插入图片描述
2-5-1、固定一个线程去拉消息
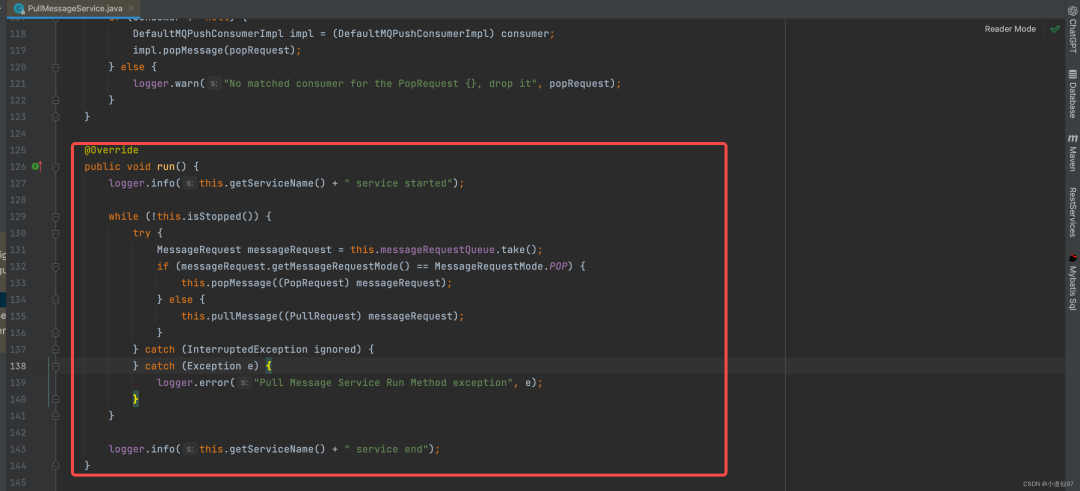
在这里插入图片描述
-
在【2-4-4】中得出,分配给当前消费者的queue会生成一个 PullRequest,然后以500ms一次塞进 messageRequestQueue里面去
-
take 方法是一个阻塞的方法,如果队列中没有数据,它会阻塞一直等待有数据为止
-
public class PullRequest implements MessageRequest
2-5-2、拉消息的过程
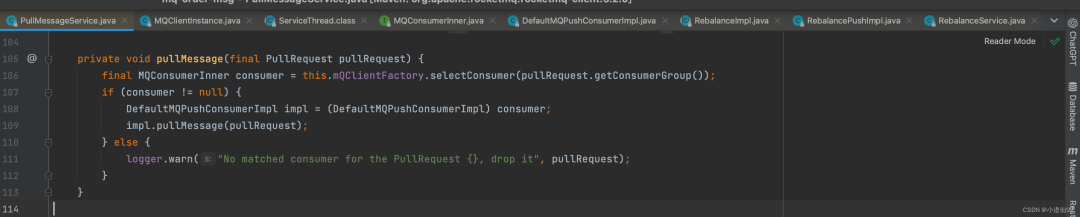
在这里插入图片描述
pullMessage 是拉消息的核心代码,简单来说就是各种判断,组装参数去请求broker获取消息,这里要关注的几个参数
-
CommunicationMode.ASYNC 使用异步拉取参数
-
pullCallback 拉到数据后的回调方法
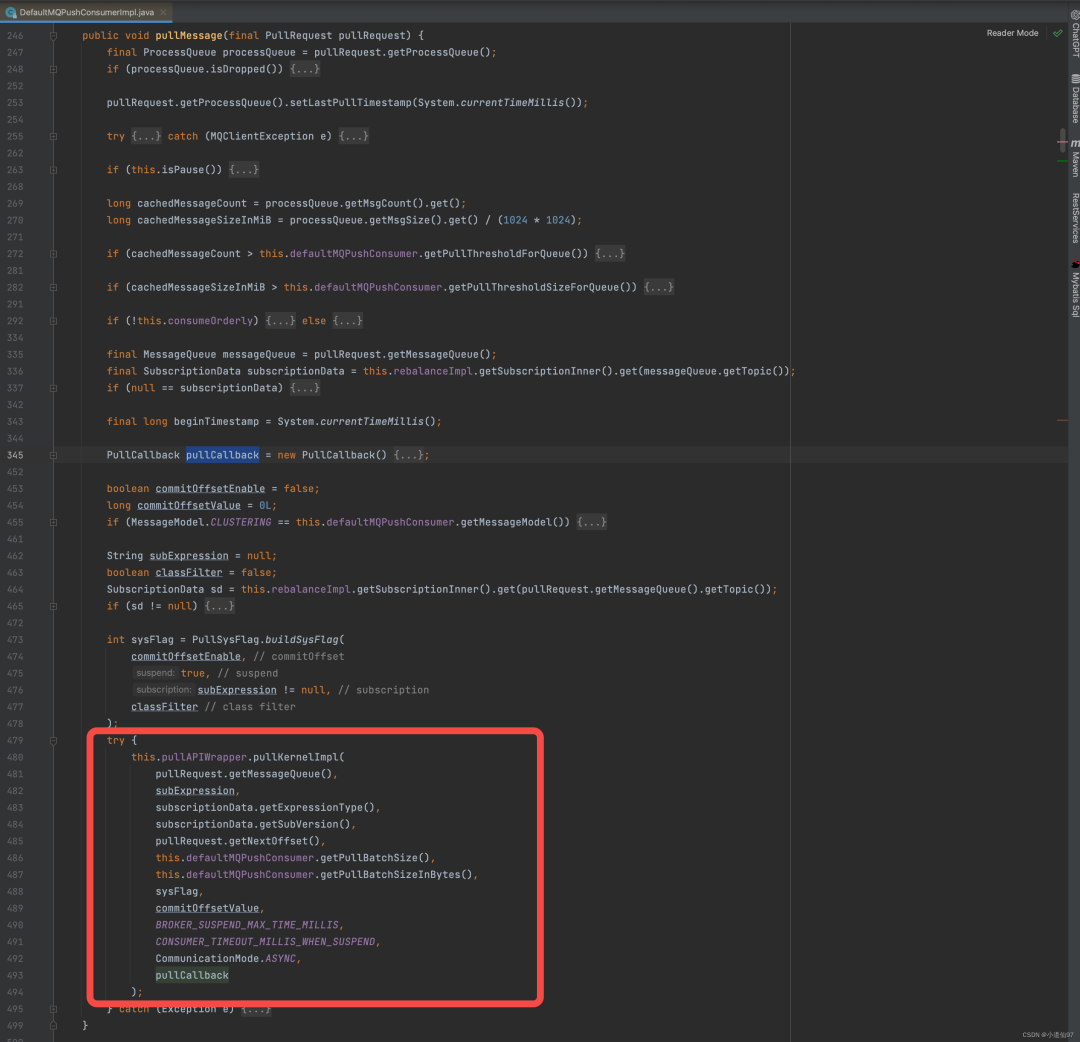
在这里插入图片描述
在真实发起netty请求之前也是一些参数的处理,流程参看下面的截图
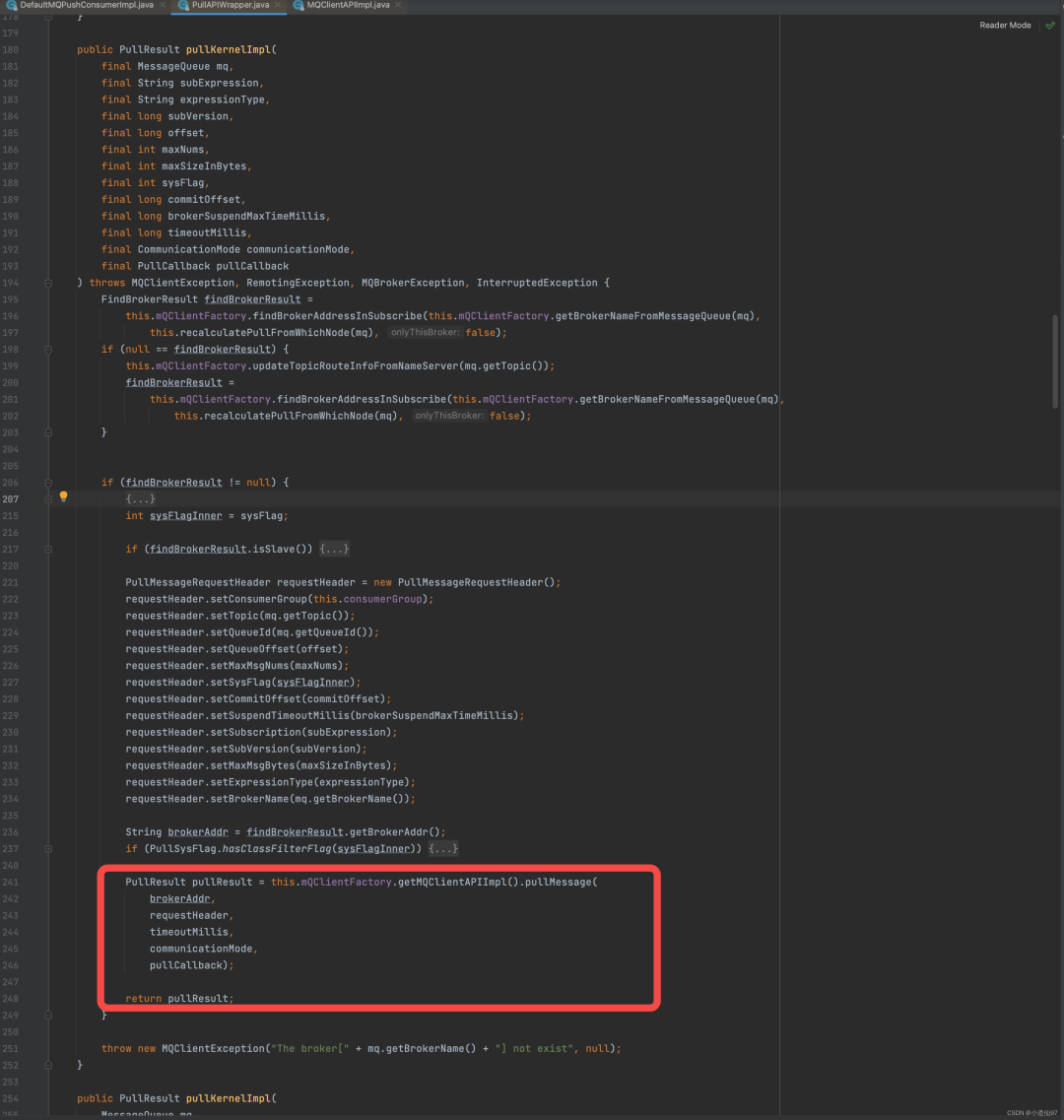
在这里插入图片描述
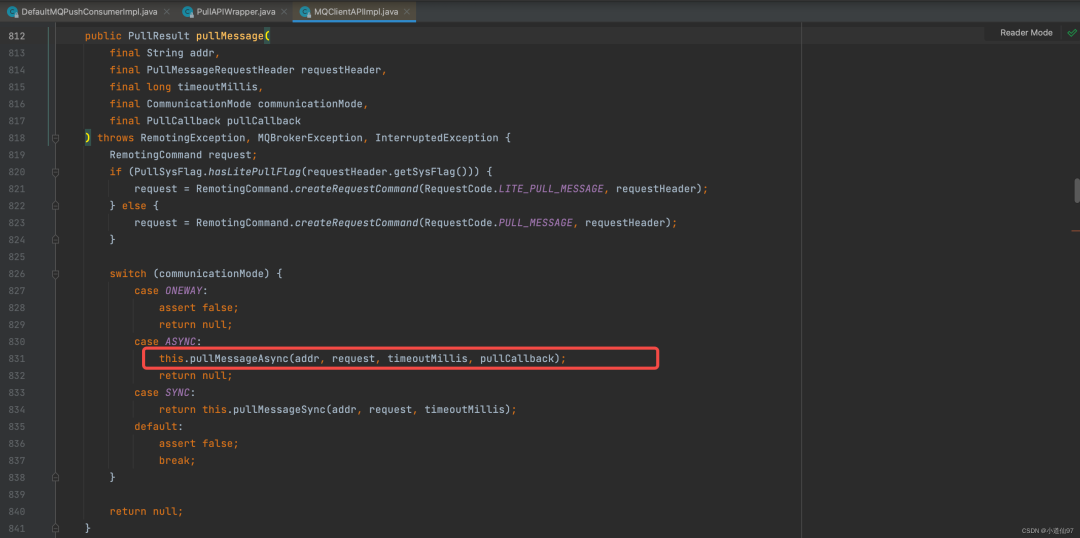
在这里插入图片描述
在这里插入图片描述
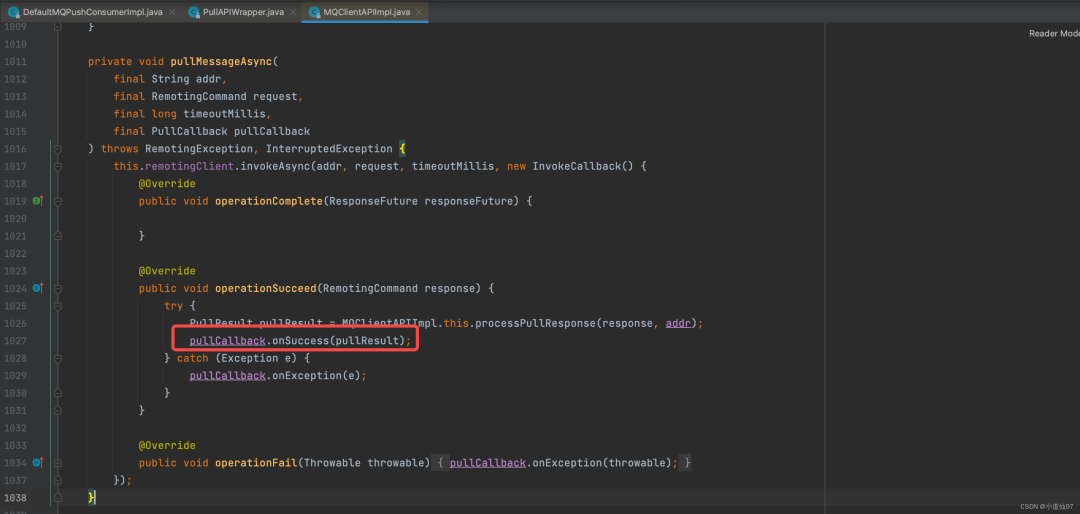
成功拉到消息后就调用回调的 onSuccess 方法
2-5-3、消息回调方法 onSuccess
org.apache.rocketmq.client.consumer.PullCallback#onSuccess PullCallback 有onSuccess和onException,在 onSuccess 中 有个 switch语句,对于正常拉到消息的状态为 FOUND,所以来着重看这个部分的代码块
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
pullResult = DefaultMQPushConsumerImpl.this.pullAPIWrapper.processPullResult(pullRequest.getMessageQueue(), pullResult, subscriptionData);
switch(pullResult.getPullStatus()) {
case FOUND:
long prevRequestOffset = pullRequest.getNextOffset();
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
long pullRT = System.currentTimeMillis() - beginTimestamp;
DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullRT(pullRequest.getConsumerGroup(), pullRequest.getMessageQueue().getTopic(), pullRT);
long firstMsgOffset = 9223372036854775807L;
if (pullResult.getMsgFoundList() != null && !pullResult.getMsgFoundList().isEmpty()) {
firstMsgOffset = ((MessageExt)pullResult.getMsgFoundList().get(0)).getQueueOffset();
DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullTPS(pullRequest.getConsumerGroup(), pullRequest.getMessageQueue().getTopic(), (long)pullResult.getMsgFoundList().size());
boolean dispatchToConsume = processQueue.putMessage(pullResult.getMsgFoundList());
// 消息丢入线程池消费,分并发消费和顺序消费
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(pullResult.getMsgFoundList(), processQueue, pullRequest.getMessageQueue(), dispatchToConsume);
// 继续把请求放入队列,由单线程继续去拉取消息 默认 pullInterval = 0
if (DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval() > 0L) {
DefaultMQPushConsumerImpl.this.executePullRequestLater(pullRequest, DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval());
} else {
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
}
} else {
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
}
if (pullResult.getNextBeginOffset() < prevRequestOffset || firstMsgOffset < prevRequestOffset) {
DefaultMQPushConsumerImpl.log.warn("[BUG] pull message result maybe data wrong, nextBeginOffset: {} firstMsgOffset: {} prevRequestOffset: {}", new Object[]{pullResult.getNextBeginOffset(), firstMsgOffset, prevRequestOffset});
}
break;
// ... 省略 ...
}
}
DefaultMQPushConsumerImpl.this.executePullRequestImmediately 这个方法在负载均衡的最后一步已经讲到了,其实就是把 pullRequest 存入 messageRequestQueue 中
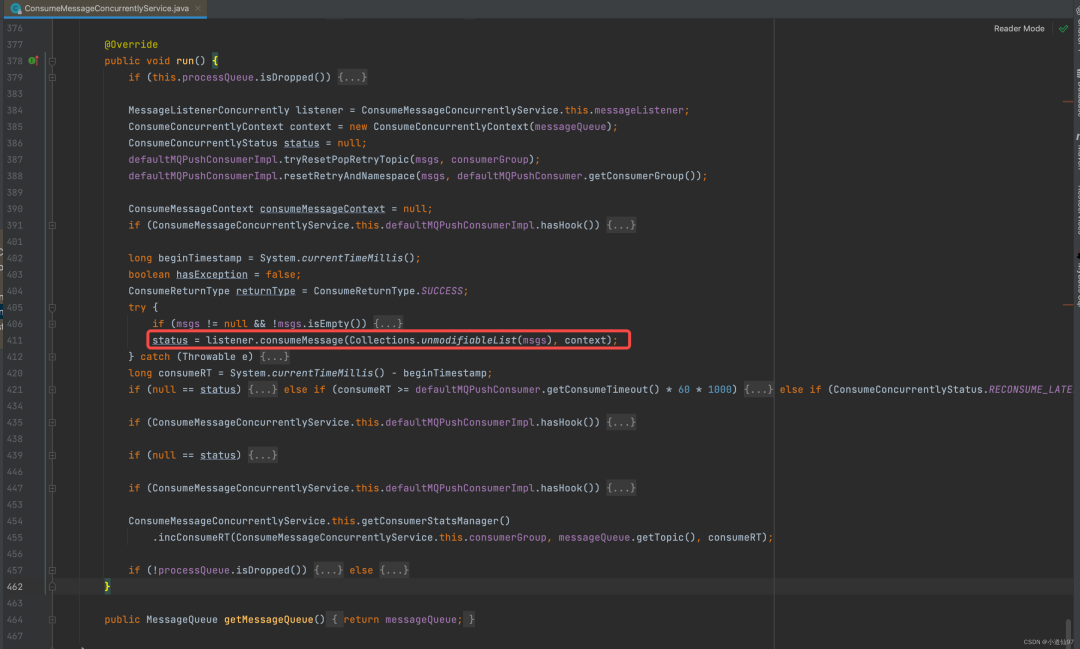
2-5-4、并发消费
@Override
public void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispatchToConsume) {
final int consumeBatchSize = this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
if (msgs.size() <= consumeBatchSize) {
ConsumeRequest consumeRequest = new ConsumeRequest(msgs, processQueue, messageQueue);
try {
// 丢进线程池去消费
this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
this.submitConsumeRequestLater(consumeRequest);
}
} else {
// 消息量过大,分批消费,逻辑一样
}
}
在这里插入图片描述
在这里插入图片描述

在这里插入图片描述
这里可以看到并发消息,只是直接就把消息组装成一个可执行的 Runnable,然后交给线程池去执行
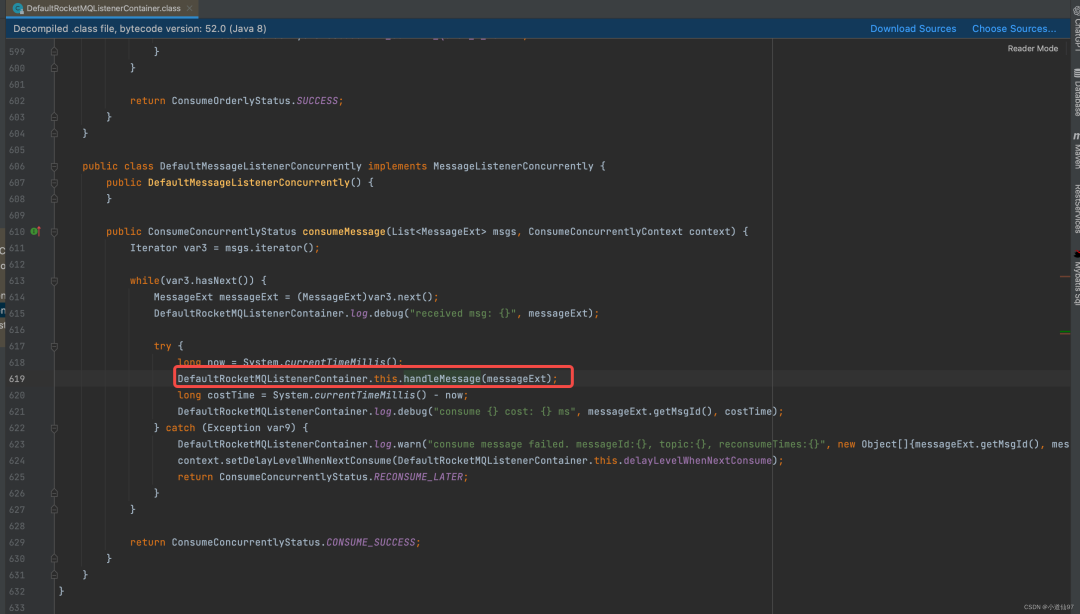
2-5-5、顺序消费
顺序消息可不一样,顺序消息必须要求同一个队列的消息只能单线程去消费才可以保证绝对的顺序
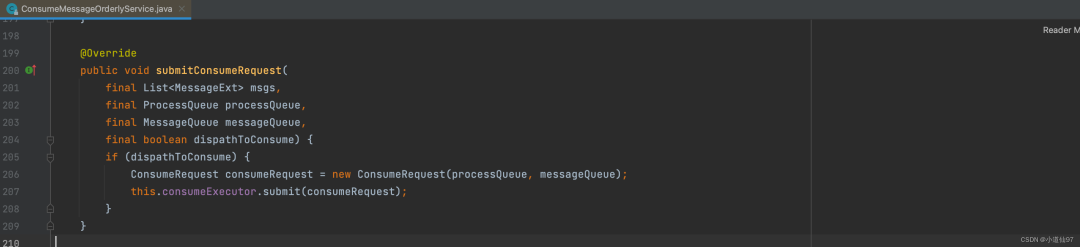
在这里插入图片描述
可以看到顺序消息也是直接把消息丢进了线程池,但是在进行消息处理的时候,使用队列进行加锁了,相当于这个队列只能单线程消费了,后续逻辑就都一样了,最终走到我们自己重写的 onMessage 里面
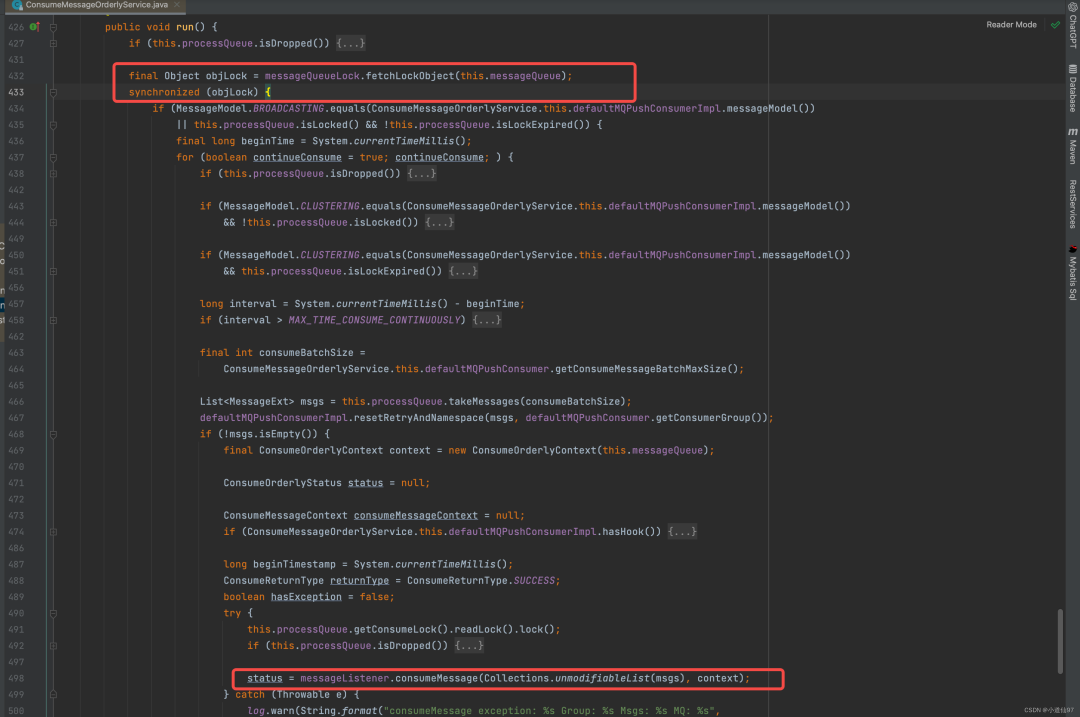
在这里插入图片描述
3、总结
看完上面的源码你最少可以回答下面几个问题
-
RocketMQ消费的流程是怎么样的
-
为什么消费者大于queue的时候,消费者就没用了
-
顺序消费如何保证顺序的














 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









