







一、为什么使用Python
Python是一种解释型、面向对象、动态数据类型的高级编程语言,具有现在高级编程语言的特性,完全面向对象。Python是荷兰人Guido van Rossum(“龟叔”)在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言。
Python优点:“优雅”、“明确”、“简单”
Python缺点:①运行速度慢,相比于C语言非常慢,因为Python是解释性语言,即代码在执行时会一行一行地翻译成CPU能理解的机器码,这个翻译过程非常耗时,所以很慢。而C程序是运行直接编译成CPU能执行的机器码,所以运行非常快。
②代码不能加密。如果要发布Python程序,实际上就是发布源代码,而C语言不用发布源代码,只需要把编译后的机器码(也就是Windows上常见的xxx.exe文件)发布出去。要从机器码反推C代码是不可能的,所以,凡是编译型语言都没有这个问题,而解释型语言,则必须把源代码发布出去。
Python主要应用领域有:
①人工智能
②网络爬虫
③科学计算和数据分析
④自动化运维
⑤金融工程领域
二、安装Python
因为python是跨平台的,所以可以运行在Windows、Mac和各种Linux/Unix系统上。在Windows上写的Python程序,放到Linux上也是可行的。开始学习Python首先就是把Python安装到自己电脑里,安装完成之后会得到Python解释器(就是负责运行python程序的),一个命令行交互环境,还有一个简单集成开发环境。
安装Anaconda包管理器:下载地址https://www.anaconda.com/distribution/
集成开发环境(IDE:Integrated Development Environment):PyCharm,
PyCharm 下载地址 : https://www.jetbrains.com/pycharm/download/
PyCharm 安装地址:http://www.runoob.com/w3cnote/pycharm-windows-install.html
Python解释器:编写Python代码时,最后得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码就需要Python解释器去执行.py文件。Python解释器有CPython(C语言开发的,官方版解释器)、IPython(基于CPython之上的一个交互式解释器,含有Tab键补全,问号手册)、PyPy(提高Python代码执行速度)、Jython(Java语言开发的)、IronPython(.Net开发)
三、第一个Python程序
命令行模式:即Win+R输入cmd进入的就是命令行模式,交互式模式:在命令行模式下输入python进入的就是交互式模式,输入exit()并回车就退出了Python交互式模式。命令行模式输入python xxx.py直接运行xxx.py文件,交互式模式输入一行执行一行。Python的交互式模式和直接运行.py文件有什么区别呢?直接输入python进入交互模式,相当于启动了python解释器,每输入一行就执行一行。直接运行.py文件相当于启动了python解释器,然后一次性把.py文件的源代码给执行了。
print("Hello,World!")能不能像.exe文件那样直接运行.py文件啊?在Windows上是不可以的,但是,在Mac和Linux上面是可以的,方法是在.py文件的第一行加上一个特殊的注释:
#推荐使用#!/usr/bin/env python3
#!/usr/bin/python
#告诉操作系统执行这个脚本的时候,调用/usr/bin下的python解释器,相当于写死了python路径。
#!/usr/bin/env python3
#为了防止操作系统用户没有将python装在默认的/usr/bin路径里,当系统看到这一行的时候,首先会到env设置里查找python的安装路径,再调用对应路径下的解释器完成操作。
print("Hello,World!")然后,通过命令给xxx.py以执行权限:
chmod a+x xxx.py就可以在命令行下运行./xxx.py了。
输入输出
>>> print("Hello,World!")
Hello,World!
>>> print("My name","is",":","Aamax","!")
My name is : Aamax !
>>> print(1000)
1000
>>> print(1000+2000)
3000
>>> print(2**10)
1024
>>> print("1+1=",1+1)
1+1= 2x = "a"
y = "b"
print(x) #a
print(y) #b
print(x,end="")
print(y,end="") #ab说明:用print()在括号中加上字符串,就可以向屏幕上输出指定文字,也可以接受多个字符串,用“,”隔开,就可以连成一串输出。也可以打印整数、计算结果以及字符串+计算结果组合。print默认输出是换行的,如果要实现不换行需要在变量末尾加end=" "
>>> name = input("Please input your name: ")
Please input your name: Aamax
>>> print("Welcome, ",name)
Welcome, Aamax说明:输入name = input()并按下回车后,Python交互式命令行就在等待输入,这时可以输入任意字符,然后回车完成输入。输入完成后,不会有任何提示,Python交互式命令行又回到了>>>状态,刚刚输入的内容存放到了name变量里了,可以直接输入name查看变量内容。
四、Python基础语法
1.注释
Python单行注释以 # 开头,多行注释可以用多个#,也可以使用 ''' 和 """
#单行注释
'''
第一行注释
第二行注释
'''
"""
第一行注释
第二行注释
"""2.缩进
# -*- coding:utf-8 -*-
#判断正负数
n = int(input("Please input a number: "))
if n >= 0:
print("n是正数!")
else:
print("n是负数!")说明:第一行注释是为了告诉Python解释器,按照UTF-8编码读取源代码。以#开头的是注释,解释器会忽略掉注释。接下来每一行为一个语句,当语句以冒号:结尾时,缩进的语句视为代码块。缩进虽然没有规定是几个空格还是Tab,但按照约定俗称的管理,应该始终坚持使用4个空格的缩进。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。特别注意缩进会带来“复制-粘贴”功能失效,导致代码报错,特别注意!!!
3.数据类型
在Python3中有六个标准的数据类型:Number(数字)、String(字符串)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典),在这六个标准数据类型中:不可变数据(3个)--->Number(数字)、String(字符串)、Tuple(元组);可变数据(3个)--->List(列表)、Set(集合)、Dictionary(字典)
Number(数字)------整数
Python可以处理任意大小的整数(没有大小限制),当然也包括负整数,在程序中的表示方法与数学上的写法一模一样,例如0,1,1000,-2000等等。除十进制以外,还有二进制,十六进制,其中二进制用0b作为前缀,十六进制用0x前缀和0-9,a-f表示。
Number(数字)------浮点数
浮点数就是小数(没有大小限制),按照科学计数法表示时,一个浮点数的小数点位置是可变的,所以称为浮点数。浮点数可以用数学写法,如1.2,3.14,但对于很大或很小的浮点数,就需要用科学计数法表示,1.23x就是
1.23e9。
Number(数字)------布尔值
在Python中,可以直接用True、False表示布尔值(请注意大写),布尔值可以用and、or、not运算,and运算是与运算,or运算是或运算,not运算是非运算(优先级为not>and>or)。在数值上下文环境中True当作1,False当作0。
Number(数字)------复数
数字总结:
a、Python可以同时为多个变量赋值,如a,b = 1,2
b、一个变量可以通过赋值指向不同类型的对象
c、数值除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数
d、在混合运算中,Python会把整型转换为浮点数
String字符串
字符串是用单引号‘’或者双引号“”括起来的任意文本。‘’或“”本身只是一种表示方式,不是字符串的一部分,因此,字符串“abc”只有a,b,c这3个字符。如果单引号内部又包含单引号(或双引号内部又包含双引号)怎么办?可以使用转义字符 \ 来标识。转义字符 \ 可以转义很多字符,如 \n 表换行,\t 制表符,字符\本身也要转义,那就用 \\ 表示\。Python还允许用 r' ' 表示' '内部字符串默认不转义。
>>> print("My name is 'Aamax'")
My name is 'Aamax'
>>> print('My name is "Aamax"')
My name is "Aamax"
>>> print('My name\'s "Aamax"')
My name's "Aamax"
>>> print("My name's \"Aamax\"")
My name's "Aamax"
>>> print("hello,\n123")
hello,
123
>>> print(r"hello,\n123")
hello,\n123
#一个表达式太长用多行来写,用 \ 连接
>>> all = 'aaa' + \
... 'bbb' + \
... 'ccc' + \
... '123'
>>> all
'aaabbbccc123'
>>> a = 'abc'
>>> b = a.replace('a','A') #调用replace(),这个方法虽然名字叫replace却没有改变字符串内容,而是创建了一个新字符串'Abc'并返回。保证了不可变对象本身永远不可变。
>>> b
'Abc'
>>> a
'abc'
字符串总结:
a、Python中字符串用单引号或者双引号括起来没有任何区别,完全相同
b、转义符 \ ,使用 r 可以让反斜杠不发生转义。如r"hello,\n123"则\n会显示,而非换行
c、按字面意义级联字符串,如"My name","is",":","Aamax","!"会得到My name is : Aamax !
d、字符串可以用 + 运算符连接在一起,用 * 运算符重复
e、Python中字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始
f、Python中字符串不能改变,Python中没有单独字符类型,一个字符就是长度为1的字符串。
g、字符串截取语法格式:变量[头下标:尾下标:步长]
h、ord()函数获取字符的整数表示,如ord('A')=65,chr()函数把编码转化为对应的字符,如chr(66)='B' ,由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。以Unicode表示的str通过encode()方法可以编码为指定的bytes,反过来,要把bytes变为str,就需要使用decode()方法。要计算str包含多少字符,可以用len()函数。
List(列表)
list是一组用方括号括起来、逗号分隔的数据。列表的元素可以是任何类型,但使用时通常各个元素类型是相同的。如列表list_a有5个元素,分别是字符串、布尔值、整数、浮点数、和列表:list_a = ['a',True,3,1.2,[3,9]]
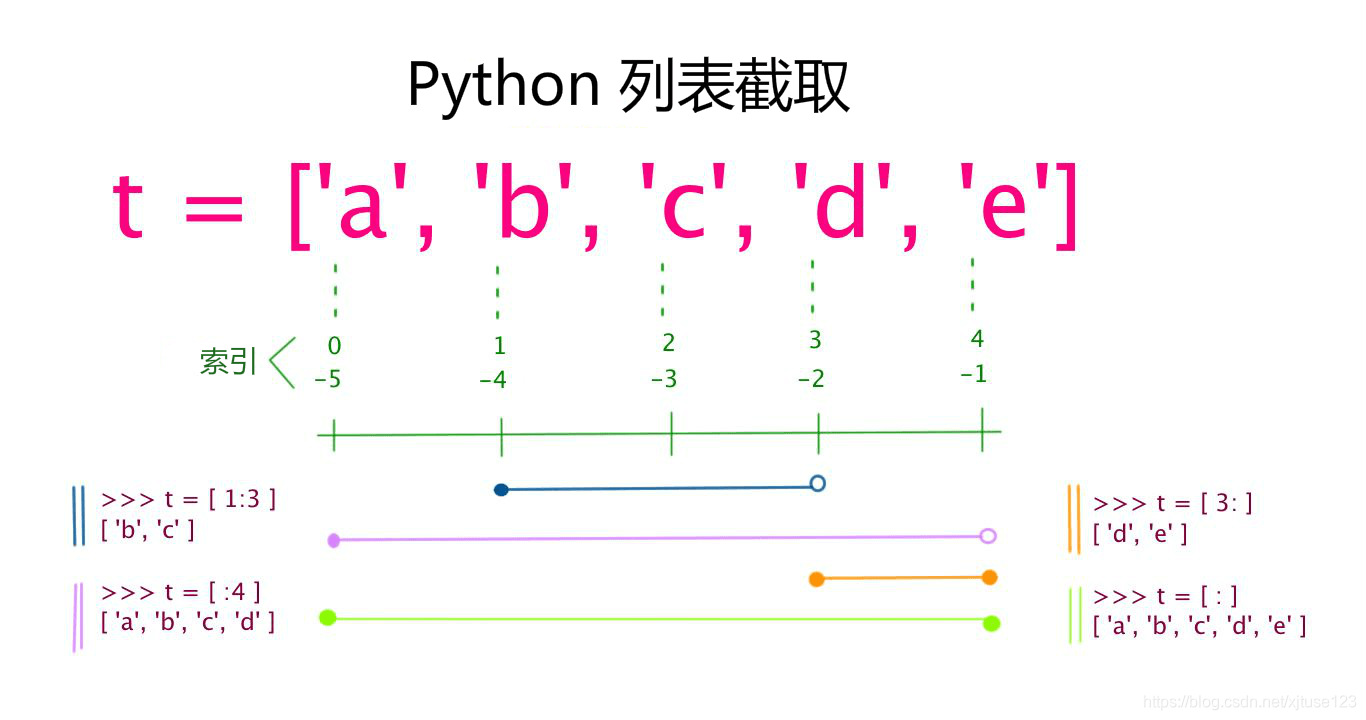
list_a = ['a','Aamax',3,1.2,[3,9]]
list_b = ['111',2019]
print(list_a[0]) #输出列表a的第一个元素,这里为a
print(list_a[-1]) #输出列表a的最后一个元素,这里为[3,9]
print(list_a[:]) #输出列表a的全部元素,这里为['a', 'Aamax', 3, 1.2, [3, 9]]
print(list_a[1:4]) #输出列表a的第2个至第4个元素,是一个左开右闭区间,即包含左边索引的元素,到右边索引为止但不包括该元素。这里为['Aamax', 3, 1.2]
print(list_a + list_b) #连接列表,这里为['a', 'Aamax', 3, 1.2, [3, 9], '111', 2019]
list_b[1] = 2020 #把某个元素换为别的元素,直接赋值给对应的索引位置
print(list_b) #['111', 2020]
#注:超出索引范围会报错!
#enumerate可以获取列表下标与列表元素
>>> list_a = ['a','Amax',3,1.2,[3,9]]
>>> for i,j in enumerate(list_a):
... print(i,j)
0 a
1 Amax
2 3
3 1.2
4 [3, 9]list运算符 、内置函数、内置方法
| 运算符 | 含义 | 表达式 | 结果 |
|---|---|---|---|
+ | 列表合并在一起 | ['a', 'b', 'c'] + [1, 2, 3] | ['a', 'b', 'c', 1, 2, 3] |
* | 列表重复 | ['a'] * 3 | ['a', 'a', 'a'] |
in | 是否为列表元素 | 'a' in ['a', 'b'] | True |
| 函数 | 含义 | 用法 |
|---|---|---|
| len() | 计算列表长度,即计算列表中元素个数 | len([1,2,3]) #3 |
| max() | 返回列表元素中最大值,列表元素必须是同一类型且可比较,比如都是数字型或都是字符串,如果类型不统一就会报错。 | max(['a','b','c']) #c |
| min() | 返回列表元素中的最小值。元素类型要求跟max()一样。 | min([1,2,3]) #1 min(['a','b','c']) #a |
| sun() | 计算列表所有元素的和,其元素类型必须是数值型的(整数、浮点数) | sum([1,2,3]) #6 |
| sorted() | 返回一个排序的列表,但并不改变原列表。 | sorted([1,0,-1,4]) #[-1, 0, 1, 4] sorted(['ab','da','c','f']) #['ab', 'c', 'da', 'f'] |
| list() | 生成一个空列表,或把其它类型数据转换成list。 | list() #[] list('python') #['p', 'y', 't', 'h', 'o', 'n'] |
| any() | 只要列表中有一个元素是True就返回True | any([0,1,'']) #True |
| all() | 只有列表所有元素为True才返回True | all([0,'','2']) #False all([1,'a','2']) #True |
| 方法 | 功能 | 示例 | 结果 |
|---|---|---|---|
| append() | 把一个元素加到列表尾部 | L = ['a','b','c','a','d','a'];L.append('A');print(L) | L变为['a','b','c','a','d','a','A'] |
| insert() | 把一个元素插到列表指定位置 | L = ['a','b','c','a','d','a'];L.insert(1,'A');print(L) | L变为['a','A','b','c','a','d','a'] |
| remove() | 删除列表中某个值的第一个匹配项 | L = ['a','b','c','a','d','a'];L.remove('a');print(L) | L变为['b','c','a','d','a'] |
| pop() | 删除列表中指定位置元素(默认最后一个元素) | L = ['a','b','c','a','d','a'];L.pop(2);print(L) | L变为['a','b','a','d','a'] |
| clear() | 清空列表 | L = ['a','b','c','a','d','a'];L.clear();print(L) | L变为[] |
| index() | 从列表中找出某个值第一个匹配项的索引位置 | L = ['a','b','c','a','d','a'];print(L.index('a')) | 0 |
| count() | 统计某个元素在列表中出现的次数 | L = ['a','b','c','a','d','a'];print(L.count('a')) | 3 |
| sort() | 对原列表进行排序 | L = ['a','b','c','a','d','a'];L.sort();print(L) | L变为['a','a','a','b','c','d'] |
| reverse() | 将列表倒置 | L = ['a','b','c','a','d','a'];L.reverse();print(L) | L变为['a','d','a','c','b','a'] |
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组元素不能修改。元组写在小括号()里,元素之间用逗号隔开。
注:如果定义只有1个元素的元组,如果这么定义:t = (1),定义的不是元组,而是1这个数!因为括号()就可以表示元组,又可以表示数学公式中的小括号,这就产生了歧义。因此,这种情况下按小括号进行计算,所以只有1个元素的元组定义时必须加一个逗号来消除歧义,如t = (1,)
t1 = ('a',1,2.2,'b',[3,6])
t2 = ('A',2019)
print(t1[0]) #a
print(t1[-1]) #[3, 6]
print(t1[::2]) #('a', 2.2, [3, 6]),这里步长为2
print(t1 + t2) #('a', 1, 2.2, 'b', [3, 6], 'A', 2019)
t1[4][1] = 9 #修改的不是元组,而是列表
print(t1) #('a', 1, 2.2, 'b', [3, 9])
#注:超出索引范围会报错!!元组运算符、元组内置函数、元组方法、拆包
| 运算符 | 含义 | 表达式 | 结果 |
|---|---|---|---|
+ | 合并在一起 | ('a', 'b', 'c') + (1, 2, 3) | ('a', 'b', 'c', 1, 2, 3) |
* | 重复 | ('a',) * 3 | ('a', 'a', 'a') |
in | 是否为元素 | 'a' in ('a', 'b') | True |
| 函数 | 含义 | 用法 |
|---|---|---|
| len() | 计算元组长度,即计算元组中元素个数 | len((1,2,3)) #3 |
| max() | 返回元组元素中最大值,元组元素必须是同一类型且可比较,比如都是数字型或都是字符串,如果类型不统一就会报错。 | max(('a','b','c')) #c |
| min() | 返回元组元素中的最小值。元素类型要求跟max()一样。 | min((1,2,3)) #1 min(('a','b','c')) #a |
| sun() | 计算元组所有元素的和,其元素类型必须是数值型的(整数、浮点数) | sum((1,2,3)) #6 |
| sorted() | 返回一个排序的元组,但并不改变原元组。 | sorted((1,0,-1,4)) #(-1, 0, 1, 4) sorted(('ab','da','c','f')) #('ab', 'c', 'da', 'f') |
| tuple() | 生成一个空元组,或把其它类型数据转换成元组。 | tuple() #() tuple('python') #('p', 'y', 't', 'h', 'o', 'n') |
| any() | 只要元组中有一个元素是True就返回True | any((0,1,'')) #True |
| all() | 只有元组所有元素为True才返回True | all((0,'','2')) #False all((1,'a','2')) #True |
| 方法 | 功能 | 示例 | 结果 |
|---|---|---|---|
| index() | 从元组中找出某个值第一个匹配项的索引位置 | T = ('a','b','c','a','d','a');print(T.index('a')) | 0 |
| count() | 统计某个元素在元组中出现的次数 | T = ('a','b','c','a','d','a');print(T.count('a')) | 3 |
#拆包
a,b,c,d = 1,2,3,4
print(a,b,c,d) #1 2 3 4
x = (1,2,3,4,5,6)
a,*b = x #x有6个元素,左边变量只有2个,多余的都被带*的b吸收了
print(a,b) #1 [2, 3, 4, 5, 6]
a,*b,c = x #多余的都被带*的b吸收了
print(a,b,c) #1 [2, 3, 4, 5] 6
*a,b,c = x #多余的都被带*的a吸收了
print(a,b,c) #[1, 2, 3, 4] 5 6元组总结:
a、与字符串一样,元组的元素不能修改
b、元组也可以被索引和切片,方法一样
c、注意包含0或1个元素的元组的特殊语法规则。t = () #空元组,t = (2,) #一个 元素,需要在元素后添加逗号
d、元组也可以用+操作符进行拼接
Dictionary(字典)
字典是python中映射类型(Mapping Type),它把"键"(key)映射到"值"(value),通过key可以快速找到value,它是一种"键值对"数据结构。这里的"键"是任意不可变类型对象(可以做hash,即具有hash()和eq()方法对象),通常是字符串和数字,同一个字典中键是唯一的,不能是列表!"值"可以是任何类型数据。字典是一组用花括号括起来、逗号分隔的键值对,键值对用冒号隔开键与值。格式:d = {key1:value1,key2:value2}
1)字典的创建
字典可以通过dict()或一对花括号创建一个空字典:d = {}。花括号内可以放用逗号隔开的多个键值对,键值用冒号隔开。当使用dict()生成字典时,传入参数有两种形式:一种是序列型数据list或tuple,它每个元素必须包含两个子元素,以满足key-value对;另一种是name=value形式的参数。
d1 = {} #花括号创建空字典
d2 = dict() #通过dict创建空字典
print(d1 == d2) #True
d3 = {'a':1,'b':2,'c':3}
print(d3) #{'a': 1, 'b': 2, 'c': 3}
d4 = {'a':1,'a':2,'a':3}
print(d4) #{'a': 3},字典只有一个键a,它的值是最后一次赋值3,多次对一个key放入value,后面的值会把前面的值冲掉
#以下两种生成字典方式等效
d5 = {'a':100,'b':200,'c':300}
d6 = dict(a=100,b=200,c=300)
#d6 = dict((('a',100),('b',200),('c',300))) #元素为元组的元组
#d6 = dict((['a',100],['b',200],['c',300])) #元素为元组的列表
#d6 = dict([('a',100),('b',200),('c',300)]) #元素为列表的元组
#d6 = dict([['a',100],['b',200],['c',300]]) #元组为列表的列表
print(d5)#{'a': 100, 'b': 200, 'c': 300}
print(d6)#{'a': 100, 'b': 200, 'c': 300}2)字典的访问
①通过键访问其值
列表可以通过其索引访问元素,字典也可以通过键访问对应的值,形式类似列表那样用方括号,只不过用"键"替代"索引"。方法是字典对象名称加方括号括起来键名,如:d7['aa'],如果某个键不在字典对象中,通过方括号访问会报错:
#通过键访问其值
d7 = dict(aa=98,bb=99,cc=87,dd=86)
print(d7['aa']) #98
print(d7['cc']) #87②通过get(key)方法访问其值
给get()传入键作为参数,就可以得到value,如果key不存在则返回None
d7 = dict(aa=98,bb=99,cc=87,dd=86)
print(d7.get('aa')) #98
print(d7.get('ee')) #None3)字典更改
>>> d7 = dict(aa=98,bb=99,cc=87,dd=86)
>>> d7['aa'] = 100 #改变某个键值
>>> d7
{'aa': 100, 'bb': 99, 'cc': 87, 'dd': 86}
>>> d7['ee'] = 90 #增加新的键值对
>>> d7
{'aa': 100, 'bb': 99, 'cc': 87, 'dd': 86, 'ee': 90}
>>> del d7['cc'] #删除某个键及其值
>>> d7
{'aa': 100, 'bb': 99, 'dd': 86, 'ee': 90}
>>> d7.pop('aa') #删除某个键及其值并得到其值
100
>>> d7
{'bb': 99, 'dd': 86, 'ee': 90}4)字典相关内置函数
| 函数 | 含义 | 用法 |
|---|---|---|
| len() | 返回字典的长度,是键的个数,也是值的个数,也是键值对的个数。空字典长度为0 | len({'a':1,'b':2}) #2 len({}) #0 |
| any() | 类似于对列表、元组的操作,不过函数检验的是字典的键。 any():只要字典有一个键为True则返回True | any({'':1,0:'abc',False:111}) #False any({'a':1,0:'abc',False:111}) #True any({}) #False |
| all() | all():只有字典的所有键都为True才返回True | all({'':1,0:'abc',False:111}) #False all({'a':1,0:'abc',False:111}) #False all({}) #True,没有键却认为所有键都为True |
| sorted() | 把字典的所有key当做一个列表(或元组)进行排序 | sorted({'a':1,'c':3,'b':4}) #['a','b','c'] |
>>> d7
{'bb': 99, 'dd': 86, 'ee': 90}
>>> 'bb' in d7 #in用来检验一个key是不是在字典中
True
>>> 'aa' not in d7
True
>>> for k in d7: #遍历字典
... print(k)
...
bb
dd
ee5)字典的内置方法
| 方法 | 功能 | 示例 |
|---|---|---|
| keys() | 返回键(key)(类型是dict_keys)。这个view对象可以动态查看字典内部的对象,当字典改变后,这个view对象也会反应变化 | d1 = dict(a=1,b=2,c=3,d=4) kk = d1.keys() type(kk) #<class 'dict_keys'> for k in kk: print(k) #a b c d
d1['e'] = 5 #修改了字典 for k in kk: #没有重新获取kk,但kk已经发生了变化 print(k) #a b c d e |
| values() | 返回值(values)(类型是dict_values)。 | d1 = dict(a=1,b=2,c=3,d=4) vv = d1.values() type(vv) #<class 'dict_values'> for v in vv: print(v) #1 2 3 4
d1['e'] = 5 for v in vv: print(v) #1 2 3 4 5 |
| items() | 返回键值对(key-value)(类型是dict_items) | d1 = dict(a=1,b=2,c=3,d=4) ii = d1.items() type(ii) #<class 'dict_items'> for i in ii: print(i) #('a',1) ('b',2) ('c',3) ('d',4)
d1['e'] = 5 for i in ii: print(i) #('a',1) ('b',2) ('c',3) ('d',4) ('e',5) |
| get() | 获取key对应的value | d1 = dict(a=1,b=2,c=3,d=4) d1.get('a') #1 d1.get('lili',100) #100 |
| clear() | 清空一个字典 | d1 = dict(a=1,b=2,c=3,d=4) d1.clear() #{} |
| copy() | 在Python中,把列表、字典对象赋值给变量时,都是“浅拷贝”,即变量指向了对象,原来的对象改变了,这个变量的值也会跟着变。而copy()函数是“深拷贝”,重新创造一个新的对象赋值给变量,原来的对象的改变不影响新对象。 | >>> d1 = {'a':1}
|
| pop(key) | 删除key及其所对应的值,返回值为被删除键所对应的值。 | >>> d1 = {'a': 1, 'b': 2} >>> d1.pop('a') 1 >>> d1 {'b': 2} |
| popitem() | 随机删除字典中一对键和值,返回值为被删除的键值对 | >>> d1 = {'a':1,'b':2,'c':3} >>> d1.popitem() ('c', 3) >>> d1 {'a': 1, 'b': 2} |
| fromkeys(seq,[val]) | 创建一个字典,以序列seq中元素做字典的键,val(可选)为字典所有键对应的值 | >>> d = {} >>> d.fromkeys([1,2,3]) {1: None, 2: None, 3: None} >>> d.fromkeys([1,2,3],1) {1: 1, 2: 1, 3: 1} |
| update() | 用一个字典来更新另一个字典 | >>> d = d.fromkeys([1,2,3],0) >>> d {1: 0, 2: 0, 3: 0} >>> d.update({1:10,2:20}) >>> d {1: 10, 2: 20, 3: 0} |
字典总结:
a、字典和列表相比,字典有两个特点:其一,查找和插入速度极快,不会随key的增加而变慢。其二,需要占用大量内存,内存浪费多。所以,字典是一种用空间换时间的方法。
b、字典的key必须是不可变对象(数字、字符串、元组) ,且同一个字典中键必须是唯一的。这是因为字典根据key计算value的存储位置,如果每次计算相同key得到结果不同,那字典就完全混乱了。
Set(集合)
集合(set)在内部实现上就是一个没有value的字典,所以它跟字典很像。集合有key但没有value(且key不重复),它的写法是这样s = {'a','b','c'},既然集合跟字典很像,那要集合干什么?集合主要测试一个对象是不是在一堆对象集里面,也就是 in 运算。这个功能其实列表也可以,但列表速度远低于集合,因为列表是顺序存储,它的时间复杂度是O(n),而集合用hash table实现的,时间复杂度为O(1)。
1)集合的创建
#创建一个空集合只能用set(),用{}创建的是一个空字典
>>> s1 = set()
>>> s2 = {}
>>> type(s1)
<class 'set'>
>>> type(s2)
<class 'dict'>
>>> s = set() #创建了一个空集合
>>> type(s)
<class 'set'>
>>> set([1,2,3,4,5]) #初始化集合,把一个列表转化为集合
{1, 2, 3, 4, 5}
>>> set([1,2,2,3,3,3,4]) #集合里重复元素最后被筛掉
{1, 2, 3, 4}
>>> s1 = {'a','b','c','d'}
>>> s1 #集合中元素是随机存放的
{'d', 'a', 'b', 'c'}
>>> s2 = {1,'a',True}
>>> s2 #结果中怎么会没有布尔值True?
{1, 'a'}2)集合的访问
集合不能像列表那样通过索引访问内部某一个元素,只能通过遍历访问全部元素,或通过变量名访问整个集合:
>>> s = {'a','b','c','d'}
>>> s
{'d', 'a', 'b', 'c'}
>>> for x in s:
... print(x)
...
d
a
b
c3)集合相关内置函数
| 函数 | 含义 | 用法 |
|---|---|---|
| len() | 返回集合长度,即集合包含的元素个数,空集合长度为0 | >>> len({'a','b','c'}) 3 >>> len({}) 0 |
| any() | 类似于对列表、元组的操作 any():只要集合有一个元素为True则返回True | >>> any({'',0,False}) False >>> any({'a',0,False}) True >>> any({}) False |
| all() | all():只有集合的所有元素都为True才返回True | >>> all({'',0,False}) False >>> all({'a',0,False}) False >>> all({}) True |
| sorted() | 跟操作列表、元组效果一样,它把集合的所有元素进行排序 | >>> sorted({'d','b','a','c'}) ['a', 'b', 'c', 'd'] |
>>> 'a' in {'a','c','d','b'} #in用来检验一个对象是不是在集合中
True
>>> 'm' in {'a','c','d','b'}
False
>>> for k in {'a','c','d','b'}: #遍历集合
... print(k)
...
b
a
d
c| 方法 | 功能 | 示例 |
|---|---|---|
| add(x) | 把对象x添加到集合中 | >>> s = {'a','b','c'} >>> s.add(1) >>> s {1, 'a', 'b', 'c'} |
| update() | 把多个对象添加到集合中 | >>> s = {'a','b','c'} >>> s.update([1,2,3]) >>> s {1, 2, 3, 'c', 'a', 'b'} >>> s.update(['x','y'],{8,9}) >>> s {1, 2, 3, 8, 9, 'c', 'x', 'a', 'b', 'y'} |
| discard(x) remove(x) | 两个都是从集合中删除一个元素x,不同的是,如果x不在集合中,discard()会忽略;而remove()会抛出KeyError错误 | >>> s = {'a','b','c'} >>> s.discard('a') #删除a >>> s {'b', 'c'} >>> s.remove('c') #删除c >>> s {'b'} >>> s.discard('x') #删除x,集合中没有x,忽略 >>> s.remove('x') #删除x,集合中没有x,报错 Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'x' |
| pop() | 类似于字典和列表中pop(),都是从其中删除一个元素并返回该元素。因为集合没有key和索引的概念,所以集合pop()不带参数。 | >>> s = {'a','b','c'} >>> s.pop() 'a' >>> s {'b', 'c'} |
| clear() | 清空一个集合 | >>> s = {'a','b','c'} >>> s.clear() >>> s set() |
| copy() | 跟字典中的copy()一样,返回一个集合的深拷贝 | >>> s1 = {'a','b','c'} >>> s2 = s1.copy() >>> s2 {'a', 'b', 'c'} >>> s1.add(1) >>> s1 {1, 'a', 'b', 'c'} >>> s2 {'a', 'b', 'c'} |
| union() | 求两个或多个集合的并集 | >>> s1 = {'a','b','c'} >>> s2 = {1,2,3} >>> s1.union(s2) {1, 'a', 2, 3, 'b', 'c'} |
| intersection() | 求两个多多个集合的交集 | >>> s1 = {'a','b','c'} >>> s2 = {'a','b',1,2} >>> s1.intersection(s2) {'a', 'b'} |
| difference() | 求一个集合与另一个或多个集合的差集,相当于集合减法 | >>> s1 = {'a','b','c'} >>> s2 = {'a','b',1,2} >>> s1.difference(s2) #返回s1包含却不在s2中的元素组成的集合 {'c'} >>> s2.difference(s1)#返回s2包含却不在s1中的元素组成的集合 {1, 2} |
| symmetric_difference() | 两个集合中除去交集之外的元素集合 | >>> s1 = {'a','b','c'} >>> s2 = {'a','b',1,2} >>> s1.symmetric_difference(s2) {1, 2, 'c'} |
| intersection_update() | 同intsersection()一样求得新集合,但此方法改变调用它的对象 | >>> s1 = {'a','b','c'} >>> s2 = {'a','b',1,2} >>> s1.intersection(s2) {'a', 'b'} >>> s1 #s1不变 {'a', 'b', 'c'} >>> s1.intersection_update(s2) >>> s1 #s1发生了变化 {'a', 'b'} |
| difference_update() | 同difference()一样求得新集合,并用新集合改变调用该方法的集合。 | >>> s1 = {'a','b','c'} >>> s2 = {'a','b',1,2} >>> s1.difference(s2) {'c'} >>> s1 #s1不变 {'a', 'b', 'c'} >>> s1.difference_update(s2) >>> s1 #s1发生了变化 {'c'} |
| symmetric_difference_update() | 同symmetric_difference()一样求得新集合,并用新集合改变调用该方法的集合 | >>> s1 = {'a','b','c'} >>> s2 = {'a','b',1,2} >>> s1.symmetric_difference(s2) {1, 2, 'c'} >>> s1 {'a', 'b', 'c'} >>> s1.symmetric_difference_update(s2) >>> s1 {1, 2, 'c'} |
| isdisjoint() | 如果两个集合没有交集则返回True | >>> s1 = {'a','b','c'} >>> s2 = {1,2,3} >>> s1.isdisjoint(s2) True |
| issubset() | 判断一个集合是不是另一个集合的子集 | >>> s1 = {'a','b','c'} >>> s2 = {'a'} >>> s2.issubset(s1) True |
| issuperset() | 判断一个集合是不是另一个集合的超集 | >>> s1 = {'a','b','c'} >>> s2 = {'a','b'} >>> s1.issuperset(s2) True |
集合总结:
a、可以用大括号{}或者set()函数创建集合,但是创建一个空集合必须用 set() 而不是 {} ,因为 {} 创建的是一个空字典!注意区分set([1,2,3])与{[1,2,3,]},set([1,2,3])返回set类型,合法。而{[1,2,3]}将可变类型放入集合中,报错!!!
空值
空值是Python中的一个特殊的值,用None表示,None不能理解为0或者False,因为0或False有意义,而None是一个特殊的空值。如果我们自己定义的函数没有返回值,Python会自动返回None。
4.变量
变量在程序中用一个变量名表示,变量名必须是大小写英文、数字和下划线的组合,且不能用数字开头。
变零可以是一个整数,如a = 1,变量可以是一个字符串,如a = "001",变量也可以是一个布尔值,如a = True。可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。这种变量本身类型不固定的语言称为动态语言。
Python内置的type()函数可以用来查询变量所指的对象类型,isinstance()也可以用来判断变量所指对象类型。type()和isinstance()的区别在于:1) type()不会认为子类是父类的一种类型 2) isinstance()会认为子类是父类的一种类型。即isinstance()可以判断子类是否继承父类,而type()不可以。
#type()与isinstance()可以来查询/判断变量所指类型
a,b,c,d = 10,10.25,True,4+8j
print(type(a),type(b),type(c),type(d)) #<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
print(isinstance(a,int)) #True
print(isinstance(b,float)) #True
print(isinstance(c,bool)) #True
print(isinstance(d,complex)) #True
#type()与isinstance()区别
class A:
pass
class B(A):
pass
print(isinstance(A(), A)) #True
print(type(A()) == A) #True
print(isinstance(B(),A)) #True
print(type(B() == A)) #False
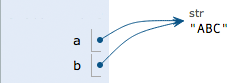
当写a = "ABC"时,Python解释器干了两件事:①在内存中创建了一个'ABC'的字符串;②在内存中创建了一个名为a的变量,并把它指向'ABC'。也可以把一个变量a赋值给另一个变量b,这个操作实际上把变量b指向变量a所指向的数据。给变量a赋新的值,变量b的值有无变化?代码如下:
>>> a = "ABC"
>>> b = a
>>> a = "XYZ"
>>> print(b)
ABC 执行a = 'ABC',解释器创建了字符串'ABC'和变量a,并把a指向'ABC':

执行b = a,解释器创建了变量b,并把b指向a指向的字符串'ABC':
执行a = 'XYZ',解释器创建了字符串'XYZ',并把a的指向改为'XYZ',但b并没有更改:
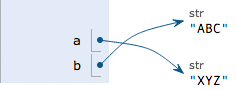
所以,最后打印变量b的结果自然是'ABC'了。
5.常量
常量就是不能变的变量,如数学中π就是一个常量,在Python中,通常用大写的变量名表示常量。
6.字符编码
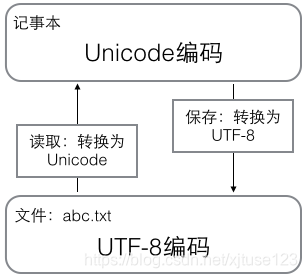
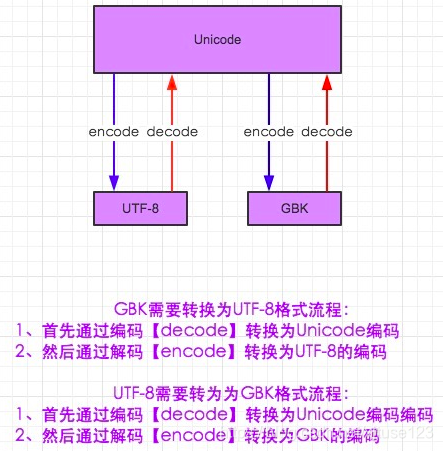
最早是ASCII编码,只有大小写英文字母、数字和一些符号,后来中国人制定了GB2312(简体中文)、GBK(简体中文+繁体中文)、GB18030(简体中文+繁体中文+藏文+蒙文+维吾尔文等),把中文编进去。全世界有上百种语言,为了制定一套编码囊括各种语言,Unicode应运而生。ASCII编码是一个字节,而Unicode编码通常是2个字节(非常偏僻字符需要4个字节),如果把ASCII编码改为Unicode编码,其实只需要在原ASCII编码前面补0就可以了。如A用ASCII编码为01000001,用Unicode编码为00000000 01000001。统一成Unicode编码缺失解决了乱码问题,但是文本如果基本上全是英文的话,用Unicode编码会比ASCII编码多一倍的存储空间,在存储和传输上十分不划算。本着节约精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。在UTF-8编码中,常用英文字母被编码成1个字节,汉字通常3个字节,生僻字符4-6个字节。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转化为UTF-8编码。用记事本编辑时,从文件读取的UTF-8字符被转化为Unicode字符到内存里,编辑完成后,保存时再把Unicode转化为UTF-8保存到文件。浏览网页的时候,服务器把动态生成的Unicode内容转化为UTF-8在传输到浏览器。
 |  |
在python2默认编码是ASCII, python3里默认是unicode,如果中文与韩文之间需要进行转换怎么做?需要:中文--->Unicode--->韩文,同样韩文转换中文也需要:韩文--->Unicode--->中文。
7.格式化
在Python中,采用的格式化方式和C语言是一致的,用 % 实现。 % 运算符就是用来格式化字符串的,在字符串内部,%s 表示用字符串替换,%d 表示用整数替换,有几个 % 占位符,后面就跟几个变量或者值,顺序要对应。如果只有一个 % ,括号可以省略。
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
>>> '亲爱的%s你好!' %'Aamax'
'亲爱的Aamax你好!'
>>> '亲爱的%s您好!您%d月的话费是%.2f,余额是%.2f' %('Aamax',5,123.345453,454.5465465)
'亲爱的Aamax您好!您5月的话费是123.35,余额是454.55'
>>> '亲爱的%s您好!您%02d月的话费是%.1f,余额是%.2f' %('Aamax',5,123.345453,454.5465465)
'亲爱的Aamax您好!您05月的话费是123.3,余额是454.55'如果不确定%d,%f,%s怎么用,那就任何情况下都写为 %s 。 %s 会把任何数据类型转化为字符串,有些时候,字符串里面%是一个普通字符,这种情况下就需要转义,用 %% 来表示一个%
>>> '亲爱的%s您好!您%s月的话费是%s,余额是%s' %('Aamax',5,12.243,34.3223)
'亲爱的Aamax您好!您5月的话费是12.243,余额是34.3223'
>>> 'growth rate: %d %%' %7
'growth rate: 7 %'format()
另一种格式化字符串的方法是使用字符串的 format() 方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}、{2}......
>>> '亲爱的{0}您好!您{1}月的话费是{2:.2f},余额是{3:.1f}'.format('Aamax',5,12.345,23.567)
'亲爱的Aamax您好!您5月的话费是12.35,余额是23.6'# -*- coding:utf-8 -*-
name = input("Name: ")
age = input("Age: ")
job = input("Job: ")
salary = input("Salary: ")
info = '''
------info of %s ------
Name:%s
Age:%s
Job:%s
Salary:%s
'''%(name,name,age,job,salary)
info2 = '''
------info of {_name} ------
Name:{_Name}
Age:{_Age}
Job:{_Job}
Salary:{_Salary}
'''.format(_name=name,
_Name=name,
_Age=age,
_Job=job,
_Salary=salary)
info3 = '''
------ info of {0} ------
Name:{0}
Age:{1}
Job:{2}
Salary:{3}
'''.format(name,age,job,salary)
print(info3)8.标识符
①第一个字符必须是字母表中字母或下划线_,不能以数字开头。
②标识符的其他部分由字母、数字和下划线组成。
③标识符对大小写敏感。
9.Python保留字(关键字)
Python中关键字我们不能把它们用作任何标识符名称。Python标准库中提供了一个keyword模块,可以输出当前版本所有关键字
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']10.import 与 from...import
在 Python中用 import 或者 from...import 来导入相应的模块。
将整个模块(somemodule)导入,格式为:import somemodule
从某个模块中导入某个函数,格式为:from somemodule import somefunction
从某个模块中导入多个函数,格式为:from somemodule import firstfunc,secondfunc,thirdfunc
将某个模块的全部函数导入,格式为:from somemodule import *
将模块更换别名,格式为:import somemodule as xxx
五、Python流程控制
1.if条件判断
Python中if语句的一般形式如下所示:
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>(1)如果‘<条件判断1>’为True将执行“<执行1>”块语句
(2)如果‘<条件判断1>’为False将判断“<条件判断2>”
(3)如果‘<条件判断2>’为True将执行“<执行2>”块语句
(4)如果‘<条件判断2>’为False将判断“<条件判断3>”
........
(5)否则执行“<执行4>”快语句
注意:a、每个条件后面要使用冒号:,表示接下来是满足条件后要执行的语句块
b、使用缩进来划分语句块,相同缩进的语句在一起组成一个语句块
c、在python中没有switch-case语句
d、if判断条件还可以简写,比如if x:,只要x是非零数值、非空字符串、非空list等,就判断为True,否则为False。
e、if语句可以单独存在,而没有elif...else,并且if语句可以嵌套,可以把if...elif...else结构放在另一个if...elif...else结构中。
#if-elif-else程序练习
print("###欢迎进入BMI计算系统###")
height = float(input("请输入您的身高(单位:米):"))
weight = float(input("请输入您的体重(单位:kg): "))
BMI = weight / (height * height)
if BMI < 18.5:
print("您的BMI为%.2f,体重过轻,平时得多吃肉啊" %BMI)
elif (BMI >=18.5) & (BMI<25):
print("您的BMI为%.2f,体重正常,注意保养~~~" %BMI)
elif (BMI >=25) & (BMI<28):
print("您的BMI为%.2f,体重超重,得适当减肥啦" %BMI)
elif (BMI >=28) & (BMI <32):
print("您的BMI为%.2f,已进入肥胖群体,得减肥了" %BMI)
else:
print("您的BMI为%.2f,已经严重肥胖了" %BMI)2.循环
Python中的循环语句有 for 和 while
for 循环
for循环的一般格式如下:
for <variable> in <sequence>:
<statements>
else:
<statements>for 循环用来遍历一个序列是最常用的,有时候手头没有现成序列要遍历,这时候就要用到 range() 函数。range()参数个数不同代表了生成不同的序列:
range(10)生成从0-9共10个整数序列
range(1,10)生成从1开始到10为止但不包含10的整数序列,即1-9
range(1,10,2)从1开始到10为止,每次步长为2 的整数序列,即[1,3,5,7,9]
#10以内整数相加
sum = 0
for x in range(11):
sum = sum + x
print(sum) #55 for循环其实可以同时使用两个甚至多个变量 ,比如dict的items()可以同时迭代key和value:
d = {'a':1,'b':2,'c':3}
for k,v in d.items():
print(k,"=",v)
#a = 1 b = 2 c = 3
如果给定一个list或tuple,可以通过for循环来遍历一个list或tuple,这种遍历我们成为迭代。在Python中迭代是通过for...in来完成的,任何可迭代对象(元组、列表、字符串、字典等等)都可以作用于for循环,包括我们自定义数据类型,只要符合迭代条件,都可以使用for循环。
#使用迭代查找一个list中的最小和最大,并返回一个tuple
def findMinAndMax(L):
if len(L) == 0:
return None,None
else:
min = L[0]
max = L[0]
for i in L:
if min >= i:
min = i
if max <= i:
max = i
return min,max
L = [1,9,6,4,-9,-45,670]
print(findMinAndMax(L)) #(-45, 670)while循环
Python中while语句的一般形式为:
while 判断条件:
语句n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1到100之和为:",sum) #1到100之和为: 5050break和continue
break是终止(或跳出)整个循环,提前结束循环;continue是跳过本次循环后面的代码去执行下一次循环。
#break与continue
#如果i<3就continue到下一次循环,continue后面代码不被执行,所以0,1,2不会被打印。
#如果i>7就break整个循环,即跳出循环,7后面的8,9也不会被打印
for i in range(10):
if i < 3:
continue
if i > 7:
break
print(i) #3 4 5 6 7
循环的else语句
循环语句可以有else子句,当 穷尽列表(for循环中) 或 循环正常结束 或者 条件变为false(while循环中) 时执行。但循环被break终止时else块将不执行。
while循环语句和for循环语句使用else区别:
a、如果else语句和while循环语句一起使用,则当条件变为False时,才执行else语句。
b、如果else语句和for循环语句一起使用,else语句块只在for循环正常终止时执行。
#示例一:
for i in range(3):
print(i)
else:
print("loop ends") #结果为0 1 2 loop ends,循环正常结束后执行了else部分
for i in range(3):
if i > 1:
break
print(i)
else:
print('loop ends') #结果为0 1,被break打断之后不再继续执行#示例二:判断质数
for n in range(2,10):
for x in range(2,n):
if n % x ==0:
print(n,'等于',x,'*',n//x)
break
else:
print(n,'是质数')
结果:
2 是质数
3 是质数
4 等于 2 * 2
5 是质数
6 等于 2 * 3
7 是质数
8 等于 2 * 4
9 等于 3 * 3














 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









