






Htk解码器网络
之前看过一部分wfst解码器的代码,跟pocketsphinx的解码器部分结构上面不太一样,所以阅读了一下htk的解码器部分的说明,以期望对pocketsphinx的代码阅读有帮助。
参考资料:
HTK book http://htk.eng.cam.ac.uk/download.shtml
解码器网络
一、 解码器网络的概况
网络分为两种:word网络和phone网络。
l word网络有两种形式:一种是由语法文件(Task Grammer)构建的网络;还有一种是由语言模型(word loop)构建的网络。网络的描述形式是SLF(Standard Lattice Format)格式的文件。
l 根据词典将词级别的网络可以扩展为phone级别的网络。
具体过程参考下图:
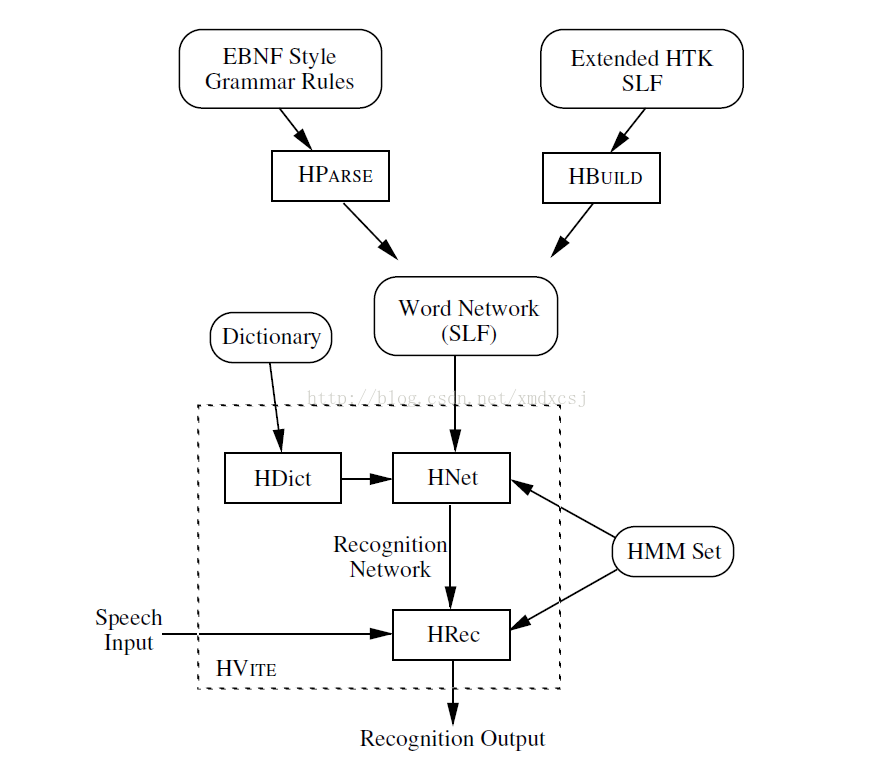
上图中相关命令的含义如下:
HParse:将语法树文件转化为SLF
HBuild:将二元语言模型(bigramlanguage model)转化为SLF,或者将word网络分解成子网络
HSGen:根据SLF文件随机生成一些结果,用于评估构建网络的复杂度
HDMan:产生词典文件
HLStats:产生语言模型
HDict:网络加载词典文件
HLM:网络加载语言模型
HNet:将词典、HMM set和word网络转化为HMM的网络
HRec:加载HMM网络来识别语音输入
HVite:集合了HNet和HRec的功能
二、 什么是解码器网络
虽然也是由节点node和边arc构成的,但是和wfst网络还是有很大的不同,等以后涉及wfst网络的时候再做详细的类比。对于word网络的SLF,节点表示word,边表示word之间的转移概率。
简单的word网络如下:
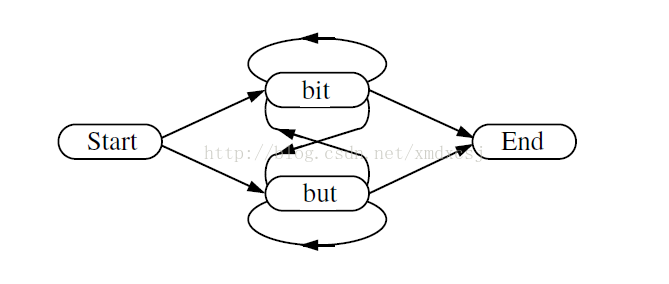
它对应的SLF文件如下:

详细含义和规则参考HTK book的Chapter 20。
为了减少边的数量,可以增加空节点!NULL,如下图所示

三、 Word级别网络(SLF文件)的是怎么生成的
(一) 根据语法文件产生
1. 使用HParse命令,语法规则:
| | | 或关系 |
| [ ] | 里面是可选项 |
| { } | 0或者多次重复 |
| <> | 1或者多次重复 |
| <<>> | 上下文有关的循环 |
2. 使用HBuild命令
根据主网络(a main lattice) 和子网络集合(aset of sub-lattices)生成word网络。相当于网络中的一个节点代表一个子网络。
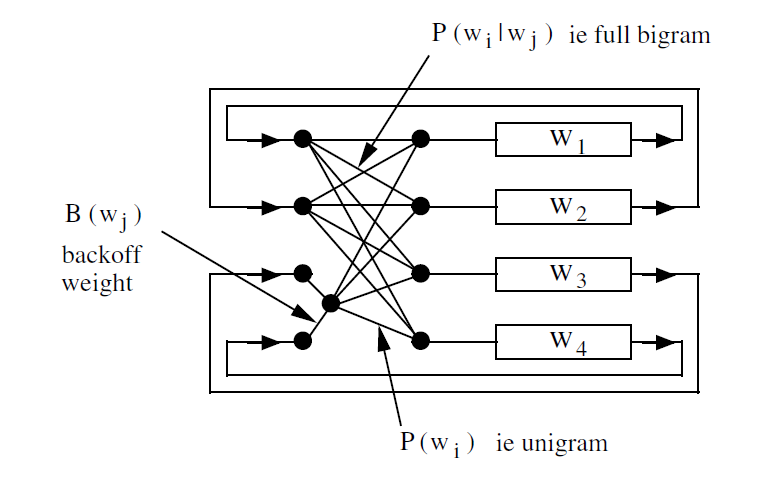
(二) 根据语言模型产生
使用HBuild命令读取二元的语言模型生成,结构图如下:
四、 词典怎么产生
(一) 词典的类型
1. Phone级别的词典

2. word-internal contextdependencies级别的词典

HNet命令会自动将phone级别的字典扩展为该类型
也可以自己将dict扩展成这种类型
3. Cross-word dependencies级别的词典
只能由HNet产生
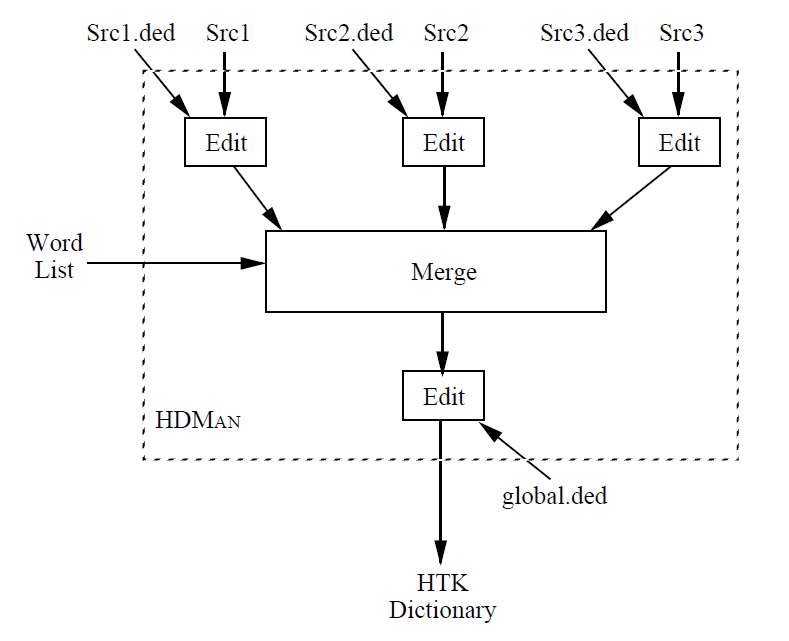
(二) 词典的生成
使用HDMan命令生成词典,可以有多个字典的输入文件
五、 Word网络和词典扩展为hmm网络
输入:词典、word网络、HMM set
输出:HMM网络
命令:HNet
(一) 主要步骤
1. Context definition
根据发音词典的音素决定声学模型的名字,以及是否需要根据上下文进行扩展。分为三种情况:
(a) Context Free
上下文确定的时候该音素不变,比如sp这个三音素(在每个词发音的结尾会加入该音素)。
(b) Context Independent
也是上下文确定的时候不变,比如sil这个三音素(相当于静音)。sil和sp的区别在于sil可能会出现在其他的三音素中,但是sp不会,比如sil-aa+r。
(c) Context Dependent
上下文有关,三音素的形式,取决于hmm set里面有没有这种三音素的定义
2. Determination of network type
如果词典里面的所有phone都出现在hmm set里面的话,无需进行phone的扩展,直接在word网络中按照词典的发音展开即可。
如果不满足上面条件,将词典的phone按照internal context expansion展开,判断展开以后的音素是否都出现在hmm set中。
如果不满足上面条件,将词典的phone按照full cross-word context expansion展开,判断展开以后的音素是否都出现在hmm set中。
ALLOWCXTEXP,ALLOWXWRDEXP, FORCECXTEXP这三个参数决定进行何种级别的展开。
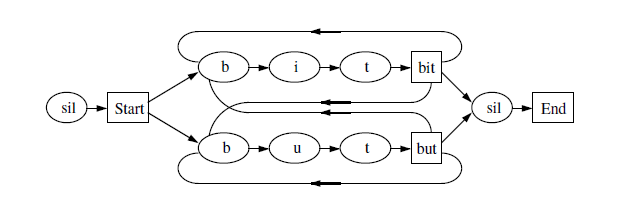
3. Network expansion
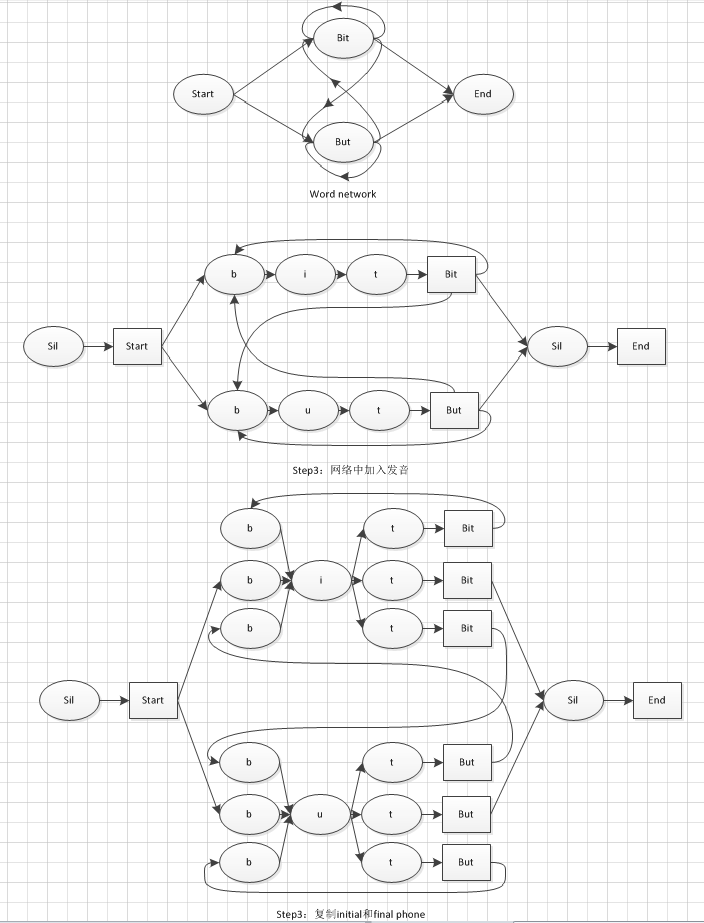
Word网络里面的word节点前面扩展该word的发音,根据上下文扩展的话,初始和最终的三音素可能需要复制成多个节点用于对应于前一个word或者后一个word。
如下图中:t的输出but有三个出边,所以需要将t这个节点复制为三个t节点,每一个t节点后面都跟着but节点。
4. Linking of models to network nodes
将单音素根据上下文生成对应的三音素

对应于:
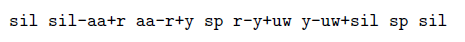
(二) 实例


















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









