






点击上方“Python与算法社区”,选择“星标”公众号

Kafka原创系列教程往期:

1
Kafka分布式集群搭建
基于第一节教程中配置的dcoker kafka 镜像,基于kakfa镜像创建容器。创建3台kafka容器,同样将容器指定backend桥接网络,这样做的好处是容器都处于一个局域网中,且你可以通过主机名或者容器名称直接访问,不需要知道IP地址。
如果不指定自定义的桥接网络,而使用模型的网络,你可能需要使用docker的links命令,使得他们之间可以通过容器名称互连。

在第二节的zookeeper教程的基础上,我启动了3个zookeeper节点。分别命名为zk1,zk2,zk3。
同样首先基于kafka镜像启动容器,指定桥接网络,与主机名、容器名方便我们操作。
dockerrun -it -d –networkbackend –name kafka1 –hostnamekafka1 kafka:1.2
使用上面的命令,分别创建kafka1,kafka2,kafka3三个容器,奇怪的是我的kafka容器无法与三个容器通信。如果你能够通信的话恭喜你,如果不能的话尝试我下面的做法。
使用dockerinspect 容器名称 命令查看容器的状态
dockerinspect zk1
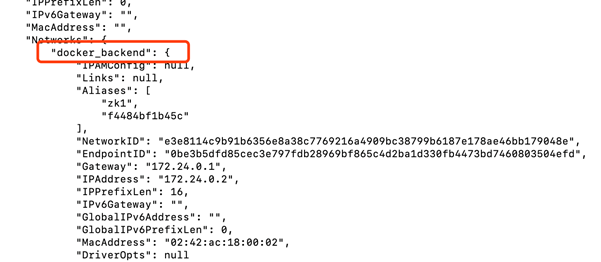
很奇怪我没有创建过这个桥接网络啊,使用docker network ls
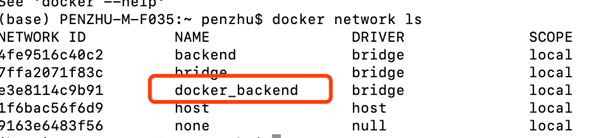
发现还真有,真是奇怪的很,因此我重新启动kafka容器使得他们处于同一个桥接网络中。
docker run -it -d –network docker_backend–name kafka1 –hostname kafka1kafka:1.2
成功通信。进入到容器内部查看目录结构
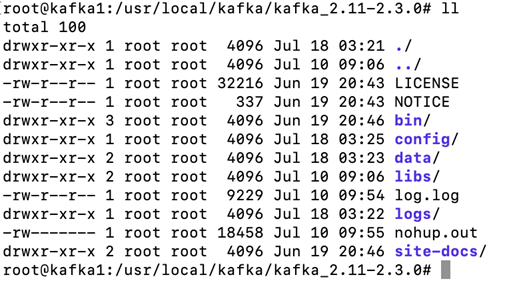
新建一个data目录负责存放kafka数据,并配置config中的server.properties
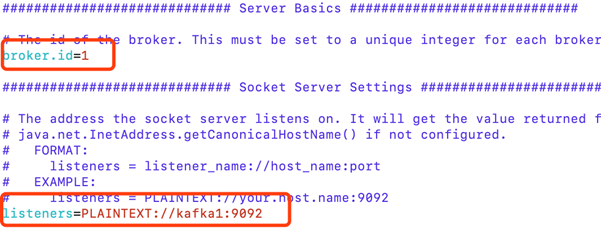
修改配置文件中的两项,broker.id是唯一的,用来标识不同的broker,配置监听器,标识borker将会监听来自9092端口的请求。
配置zookeeper

同理,按照这种配置,在其他两台kafka中相同的步骤来配置,id号分别为2,3。监听器主机名需要对应的修改。
2
启动三台kafka
分别启动三台kafka
./bin/kafka-server-start.shconfig/server.properties &
创建分区,指定zookeeper,设置3个分区,为每个分区配置3个副本
./bin/kafka-topics.sh--create --zookeeper zk1:2181 --replication-factor 3--partitions 3 --topic testopic
创建完成之后,

进入data目录里面查看可以看到testopic三个分区,有意思的是另外两个kafka的data目录里面也是同样的。也就是说创建三个副本,这个三个副本不存在同一个broker中。仔细想一下,如果在同一个broker中,这个副本毫无意义,当broker挂掉的时候,这个副本也将不能提供任何服务。
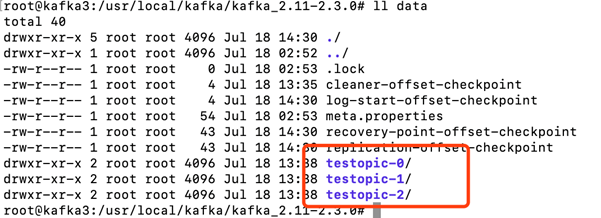
3个broker为每个分区指定3个副本,那如果指定4个呢?会存在partition与其副本在同一个broker中吗?

报错了,提示副本数不能大于broker。这也就证明了我们的猜想,partition不会与其副本在同一个broker中,因为这样毫无意义。
启动生产者程序

进入到data目录,并打印log文件,可以看到生产者生产的消息。
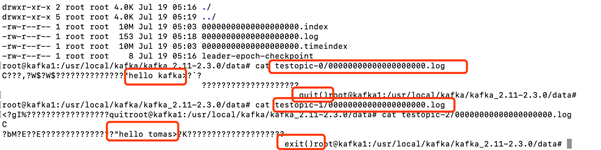
启动消费者命令
bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092--from-beginning --topic testopic
从命令来看并没有指定zookeeper地址。那么offset如何协调呢?实际上在新版kafka中offset以topic的形式存放在kafka中,老版本的kafka是将offset存放在zookeeper中,consumer消费消息需要指定zookeeper地址,kafka地址,新版本后消费者将不再依赖zookeeper。实际上offset的存放的地址,依赖kafka consumer的版本,如果consumer是新版本,则offset会以topic的形式存放在kafka中。
进入到zookeeper中查看

发自动生成了一个名为__consumer_offsets的topic。
进入到zookeeper中 get /brokers/topics/testopic
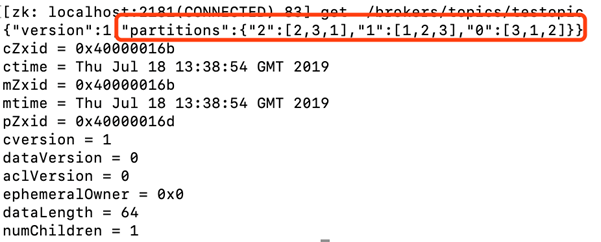
以“2”:[2,3,1]为例,表示partition2分别存在broker2,broker3,broker1中,因为我们副本数设置的为3。
再看一下__consumer_offsets的topic详情

自动生成了50个partition,并且都没有副本,随机的分布在3台broker中。
到其中的一台broker中查看data目录。自动生成了很多__consumer_offset 的partition
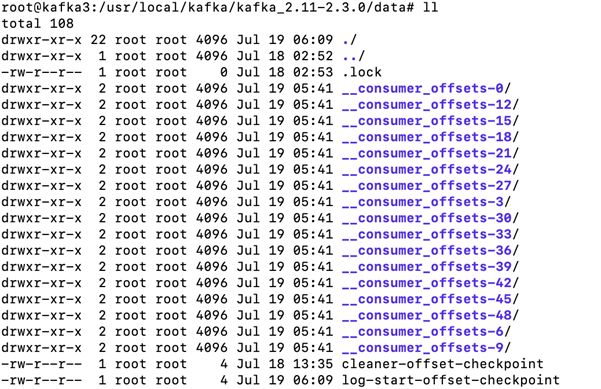
打印partition的log文件

3
总结
然而并没有找到我感兴趣的offset具体的值,但是包含了consumer的信息,这至少已经证明offset是存放在kafka中,而不是zookeeper中了,不是吗?
老版本的consumer接口在消费消息时候,并不会每消费一个消息就提交一次offset给zookeeper,因为这样容易造成zookeeper负担太大(即使zookeeper也是一个强大的分布式读写系统),而是会消费一部分消息后再提交。这样可能会导致消费者程序挂掉,offset还没有提交,那么下次可能会读到重复数据。将offset存放到kafka.
从上面的实验可以看到,我们就输入了几条数据,但是生成了50个partition,也就是说此刻kafka允许有50个consumer来并行同时消费不同partition中的消息,这个吞吐量还是很惊人的。
虽然zookeeper很快,但是之前的文章提到过,zookeeper读数据可以从leader或者follower读,但是写数据必须由leader写,然后follower再同步leader中的数据。从网络IO瓶颈比起来新版本kafka的做法允许更多消费者同时工作,且更新offset处理消息的batch size可以设置的更小。
因此在接口开发过程中,开发者甚至感受不到zookeeper的存在,将更多的精力放在开发业务。
熟悉kafka原理与配置方法,相信根据接口开发任务对于你来说将会非常easy,kafka入门教程更新到此,如果还对kafka有什么疑问,可以提出来一起讨论学习。
Kafka原创系列教程

长按扫码可关注
点个在看![]()














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









