







Apache Spark is a fast and general engine for large-scale data processing.
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoo 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
如此的有前途,当然又是apache旗下的产品了,虽然当前还处于孵化阶段。项目地址:http://spark.incubator.apache.org/
Spark的优势:
Spark是一个高效的分布式计算系统,相比Hadoop,它在性能上比Hadoop要高100倍。Spark提供比Hadoop更上层的API,同样的算法在Spark中实现往往只有Hadoop的1/10或者1/100的长度。Shark类似“SQL on Spark”,是一个在Spark上数据仓库的实现,在兼容Hive的情况下,性能最高可以达到Hive的一百倍。
淘宝对Spark的运用
淘宝数据挖掘部的黄明(明风)-----《插上翅膀的大象,基于Spark on Yarn的淘宝数据挖掘平台》的主题演讲:
选择Spark on Yarn的三个理由
据明风介绍,他的团队从一年多前开始组建数据挖掘平台,我们是用Hadoop,淘宝公司最大的数据平台是“云梯”,云梯便是基于Hadoop的。不过我们在用Hadoop做数据挖掘时遇到很多问题,其中最大的问题是复杂数据挖掘算法的时候,面对反复多次迭代的问题。数副数据挖掘算法有时候需要迭代,每次迭代(英文)时间非常大,有些迭代100次,中间结构序列化和反序列化成本,这是我们选择一个更高性能计算框架的原因。还有简单的MR模式,Hadoop把MR模式非常简单处理数据计算的问题,我们处理复杂的机械学算法很难飞跃的一个问题。还有OO编程表达机器学习算法的能力,我们有一些机器学习同学他们说感受是啰嗦,OO表达机器学习算法过程很烦琐。另外图计算能力非常重要,Hadoop有相应的Hama计算框架,经过评估计算能力不足以满足我们需求。
我们选择Spark有三个理由:第一RDD内存计算、快速迭代、DAG;第二是Scala表达复杂机器学习算法能力比Java更强,FD编程风格、Actor模型、并发能力;第三Hadoop集成,很早提供HDFS访问,对于淘宝数据挖掘非常重要的,不可能再搭一套小的集群访问,把所有数据拉到小集群做计算这样代价很高,还有MapReduce编程模式,很多做数据挖掘的同学之前在Hadoop有很好的经验,对于他们迁移成本比迁移MPIA更简单一些。
Spark的生态圈
之前讲了很多,对于我们最看重的两点:一个云梯集成能力,我们可以通过Spark跟云梯计算资源和储存资源无缝结合,另外相对成熟的子项目,可以进行快速做图计算的能力,所以我们选择Spark作为数据平台。

淘宝的Spark之路
2012年初Spark发布0.5做一次试验,当时选择框架是Mesos大概用三台机器做小实验,由于这个版本不是非常成熟,所以在上边并没有真正把生产级别挖掘算法跑起来过,这个情况到2012年六月中0.6版本,Spark推出Standalone模式,大概十台小集群,用一周时间跑通了两个生产级别的算法,Spark确实跟云梯很好的集成能力。虽然我们只是跑了两个算法,但是没有做更大的推广,因为需要很多的机器才能承载生产能力,这个不是我们想做的。直到今年上半年看到云梯的Yarn基本成熟,并给我们提供合作和支持,在他们帮助,并和跟社区作者咨询后,我们选择做持续跟进,Yarn的版本0.2.3.7版本,Spark是Master分支,最终在8月份成功把Spark on Yarn跑起来。一开始是一百、现在有两百台机器,机器的内存是96G内存,在这样配置下,可以进行生产级别大批量任务的调度,而且只要云梯做机器的版本切换,200台机器可以做轻松的水平扩展,可以满足我们生产需要。
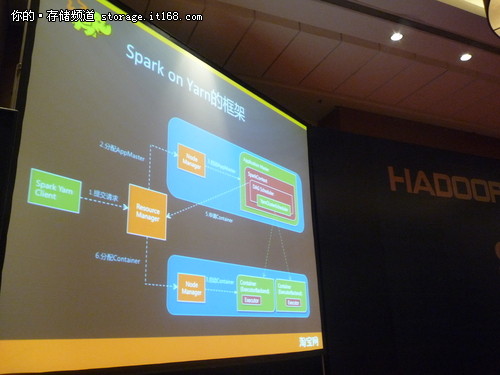
基于Spark on Yarn的数据挖掘平台架构
Spark on Yarn代码非常简洁,模块整体大概十个类左右,集成非常简单。我们看一下请求和交付的过程,图中绿色的表示Spark on Yarn的类,红色表示Spark本身有的类,蓝色表示Yarn的类。三者怎么结合? Spark on Yarn发起一个请求,会找到一个Node Manager,然后会启动Application Master,AppMaster启动完毕,会向ResourceManager,请求Container,ResourceManager会找到Node Manager机器,启动Container,作为Executor容器,真正交互是在ContainerBackend和YarnClusterManager之间进行的。
再看一下调度过程,我们Spark基于RDD和操作符,在第一步转换为DAG,DAG会传递给最核心的DAGScheduler,转化多个TaskSet,然后由ClusterManager传递Tark,到最后具体的Executor。
这个图和前一张图是呼应关系,因此可以看到我们为什么提升Spark on Yarn工作不是那么痛苦?因为Spark计算框架,设计理念是在任何分布式调度框架上运行,而Yarn调度框架,设计理念是作为任意的计算框架做调度。因此两个设计理念是天然的配合,集成的时候不存在太大的困难。
不过在Spark on Yarn的实施过程中,明风他们也遇到了很多问题:第一个是多生态作业竞争问题,同样是好处也是一个坏处,内存消耗非常多的作业,有可能作业等待很久才能递交上去,比普通的Hadoop更加麻烦,面临着CPU、内存都申请到才可以运行
第二机器内存性能,如果搭建Spark on Yarn集群,千万不要找内存比较小的搭集群,最好96G或者120G,机器可以相对少一点,比如100台20G搭建小集群,这样花在私人申请、任务调度、计算时间非常多,最后让Spark性能非常差,既然要跑Spark,就不要珍惜内存了,而且内存价格越来越白菜价,用好机器,真正体验Spark给数据挖掘带来质的飞跃;
第三个粗粒度的资源预申请,Spark提交的时候,运行算法之前需要把所有算法资源申请到,可能你提交一个算法运行十个Stage,中间一个需要1T内存,那么作业运行过程仲,要一直占1T内存不放才能成功运行。这个作者会在后面框架做一些改进,但是动作比较大,暂时问题没有办法解决,需要把算法跑需要按照最大资源申请需要的内存以及Core才可以;
最后一个问题开发人员的内存把控能力,因为Spark作业目前写起来有两个问题,一个是语法问题,一个对内存把控能力。作为普通的机器学习算法开发人员这方面会比较痛苦一点,因为他们更侧重机器学习算法,而对内存把控不太好,需要学习一些东西,才能在上边娴熟开发和运行算法。














 9939
9939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









