







继续将《机器学习实战》的内容带给大家,如果你已经是大牛,请将我的文章忽略,本人适合入门的人物,今天先把前边的数据建立和数据的预处理带给大家。好了先看第一段代码:
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec这个函数是创建数据的代码,这里就不详细说明了,就是两个列表。
然后我们看一下将所有词汇去掉重复的统计出来:
def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
O(∩_∩)O~ 函数都非常简单,python用来求并集非常方便,O(∩_∩)O~,这个是非常好的一个例子,然后我们继续说明如何查询新来的文本和我们统计的文本进行对照进行统计是否出现该文本:
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print ("the word: %s is not in my Vocabulary!" % word)
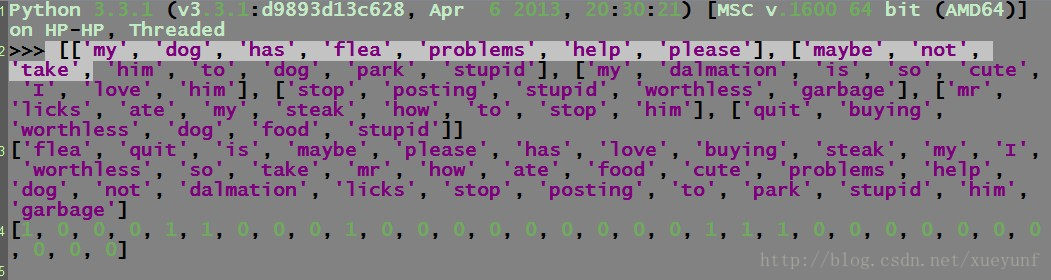
return returnVec最后给大家来张截图(因为很多人常说无图无真相啊,为了保持我有图有真相的形象,果断来一张):

















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









