







# -*- coding: utf-8 -*-
import random
a = 1
b = 10
step = 3
seq = [-1, -2, -3, -4, -5, -6, -7, -8, -9, 0]
k = 2
# 0 <= n < 1.0
print 'random', random.random()
# b <= n(float) <= a
print 'uniform', random.uniform(a, b)
# a <= n(int) <= b
print 'randint', random.randint(a, b)
# 从指定范围内,按指定基数递增的集合中,获取一个随机数
print 'randrange', random.randrange(a, b, step)
# 从序列中获取一个随机元素
print 'choice', random.choice(seq)
# 从指定序列中随机获取指定长度的片断
print 'sample', random.sample(seq, k)
# 将一个列表中的元素顺序打乱
random.shuffle(seq)
print 'shuffle', seq
# 带权重的随机
def __in_which_part(n, w):
for i, v in enumerate(w):
if n < v:
return i
return len(w) - 1
def weighting_choice(data, weightings):
s = sum(weightings)
w = [float(x)/s for x in weightings]
t = 0
for i, v in enumerate(w):
t += v
w[i] = t
c = __in_which_part(random.random( ), w)
try:
return data[c]
except IndexError:
return data[-1]
print 'weighting_choice', weighting_choice(['a', 'b'], [10, 90])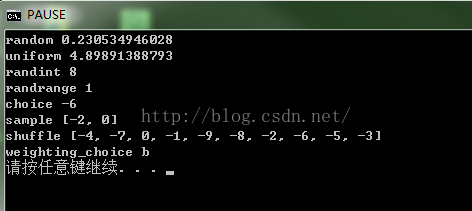














 1715
1715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









