






在系统维护的过程中,随时可能有需要查看 CPU 使用率,并根据相应信息分析系统状况的需要。在 CentOS 中,可以通过 top 命令来查看 CPU 使用状况。运行 top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式 -- 用基于 top 的命令,可以控制显示方式等等。退出 top 的命令为 q (在 top 运行中敲 q 键一次)。
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
可以直接使用top命令后,查看%MEM的内容。可以选择按进程查看或者按用户查看,如想查看oracle用户的进程内存使用情况的话可以使用如下的命令:
$ top -u oracle
内容解释:
PID:进程的ID
USER:进程所有者
PR:进程的优先级别,越小越优先被执行
NInice:值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数
%CPU:进程占用CPU的使用率
%MEM:进程使用的物理内存和总内存的百分比
TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
COMMAND:进程启动命令名称
操作实例:
在命令行中输入 “top”
即可启动 top
top 的全屏对话模式可分为3部分:系统信息栏、命令输入栏、进程列表栏。
第一部分 -- 最上部的 系统信息栏 :
第一行(top):
“00:11:04”为系统当前时刻;
“3:35”为系统启动后到现在的运作时间;
“2 users”为当前登录到系统的用户,更确切的说是登录到用户的终端数 -- 同一个用户同一时间对系统多个终端的连接将被视为多个用户连接到系统,这里的用户数也将表现为终端的数目;
“load average”为当前系统负载的平均值,后面的三个值分别为1分钟前、5分钟前、15分钟前进程的平均数,一般的可以认为这个数值超过 CPU 数目时,CPU 将比较吃力的负载当前系统所包含的进程;
第二行(Tasks):
“59 total”为当前系统进程总数;
“1 running”为当前运行中的进程数;
“58 sleeping”为当前处于等待状态中的进程数;
“0 stoped”为被停止的系统进程数;
“0 zombie”为被复原的进程数;
第三行(Cpus):
分别表示了 CPU 当前的使用率;
第四行(Mem):
分别表示了内存总量、当前使用量、空闲内存量、以及缓冲使用中的内存量;
第五行(Swap):
表示类别同第四行(Mem),但此处反映着交换分区(Swap)的使用情况。通常,交换分区(Swap)被频繁使用的情况,将被视作物理内存不足而造成的。
第二部分 -- 中间部分的内部命令提示栏:
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下表:
s
- 改变画面更新频率
l - 关闭或开启第一部分第一行 top 信息的表示
t - 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
m - 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
N - 以 PID 的大小的顺序排列表示进程列表(第三部分后述)
P - 以 CPU 占用率大小的顺序排列进程列表 (第三部分后述)
M - 以内存占用率大小的顺序排列进程列表 (第三部分后述)
h - 显示帮助
n - 设置在进程列表所显示进程的数量
q - 退出 top
s -
改变画面更新周期
第三部分 -- 最下部分的进程列表栏:
以 PID 区分的进程列表将根据所设定的画面更新时间定期的更新。通过 top 内部命令可以控制此处的显示方式
pmap
可以根据进程查看进程相关信息占用的内存情况,(进程号可以通过ps查看)如下所示:
$ pmap -d 5647
ps
如下例所示:
$ ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' 其中rsz是是实际内存
$ ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' | grep oracle | sort -nrk
其中rsz为实际内存,上例实现按内存排序,由大到小
在Linux下查看内存我们一般用free命令:
[root@scs-2 tmp]# free
total used free shared buffers cached
Mem: 3266180 3250004 16176 0 110652 2668236
-/+ buffers/cache: 471116 2795064
Swap: 2048276 80160 1968116
下面是对这些数值的解释:
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
第四行就不多解释了。
区别:第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是16176KB,已用内存是3250004KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
如上例:
2795064=16176+110652+2668236
接下来解释什么时候内存会被交换,以及按什么方交换。 当可用内存少于额定值的时候,就会开会进行交换。
如何看额定值:
cat /proc/meminfo
[root@scs-2 tmp]# cat /proc/meminfo
MemTotal: 3266180 kB
MemFree: 17456 kB
Buffers: 111328 kB
Cached: 2664024 kB
SwapCached: 0 kB
Active: 467236 kB
Inactive: 2644928 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 3266180 kB
LowFree: 17456 kB
SwapTotal: 2048276 kB
SwapFree: 1968116 kB
Dirty: 8 kB
Writeback: 0 kB
Mapped: 345360 kB
Slab: 112344 kB
Committed_AS: 535292 kB
PageTables: 2340 kB
VmallocTotal: 536870911 kB
VmallocUsed: 272696 kB
VmallocChunk: 536598175 kB
HugePages_Total: 0
HugePages_Free: 0
Hugepagesize: 2048 kB
用free -m查看的结果:
[root@scs-2 tmp]# free -m
total used free shared buffers cached
Mem: 3189 3173 16 0 107 2605
-/+ buffers/cache: 460 2729
Swap: 2000 78 1921
查看/proc/kcore文件的大小(内存镜像):
[root@scs-2 tmp]# ll -h /proc/kcore
-r-------- 1 root root 4.1G Jun 12 12:04 /proc/kcore
备注:
占用内存的测量
测量一个进程占用了多少内存,linux为我们提供了一个很方便的方法,/proc目录为我们提供了所有的信息,实际上top等工具也通过这里来获取相应的信息。
/proc/meminfo 机器的内存使用信息
/proc/pid/maps pid为进程号,显示当前进程所占用的虚拟地址。
/proc/pid/statm 进程所占用的内存
[root@localhost ~]# cat /proc/self/statm
654 57 44 0 0 334 0
输出解释
CPU 以及CPU0。。。的每行的每个参数意思(以第一行为例)为:
参数 解释 /proc//status
Size (pages) 任务虚拟地址空间的大小 VmSize/4
Resident(pages) 应用程序正在使用的物理内存的大小 VmRSS/4
Shared(pages) 共享页数 0
Trs(pages) 程序所拥有的可执行虚拟内存的大小 VmExe/4
Lrs(pages) 被映像到任务的虚拟内存空间的库的大小 VmLib/4
Drs(pages) 程序数据段和用户态的栈的大小 (VmData+ VmStk )4
dt(pages) 04
查看机器可用内存
/proc/28248/>free
total used free shared buffers cached
Mem: 1023788 926400 97388 0 134668 503688
-/+ buffers/cache: 288044 735744
Swap: 1959920 89608 1870312
我们通过free命令查看机器空闲内存时,会发现free的值很小。这主要是因为,在linux中有这么一种思想,内存不用白不用,因此它尽可能的cache和buffer一些数据,以方便下次使用。但实际上这些内存也是可以立刻拿来使用的。
所以 空闲内存=free+buffers+cached=total-used
top命令 是Linux下常用的性能 分析工具 ,能够实时显示系统 中各个进程的资源占用状况,类似于Windows的任务管理 器。下面详细介绍它的使用方法。
top - 02:53:32 up 16 days, 6:34, 17 users, load average: 0.24, 0.21, 0.24
Tasks: 481 total, 3 running, 474 sleeping, 0 stopped, 4 zombie
Cpu(s): 10.3%us, 1.8%sy, 0.0%ni, 86.6%id, 0.5%wa, 0.2%hi, 0.6%si, 0.0%st
Mem: 4042764k total, 4001096k used, 41668k free, 383536k buffers
Swap: 2104472k total, 7900k used, 2096572k free, 1557040k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32497 jacky 20 0 669m 222m 31m R 10 5.6 29:27.62 firefox
4788 yiuwing 20 0 257m 18m 13m S 5 0.5 5:42.44 konsole
5657 Liuxiaof 20 0 585m 159m 30m S 4 4.0 5:25.06 firefox
4455 xiefc 20 0 542m 124m 30m R 4 3.1 7:23.03 firefox
6188 Liuxiaof 20 0 191m 17m 13m S 4 0.5 0:01.16 konsole
统计信息区前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
01:06:48 当前时间
up 1:22 系统运行 时间,格式为时:分
1 user 当前登录用户 数
load average: 0.06, 0.60, 0.48 系统负载 ,即任务队列的平均长度。
三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
Tasks: 29 total 进程总数
1 running 正在运行的进程数
28 sleeping 睡眠的进程数
0 stopped 停止的进程数
0 zombie 僵尸进程数
Cpu(s): 0.3% us 用户空间占用CPU百分比
1.0% sy 内核 空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
98.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0% hi
0.0% si
最后两行为内存 信息。内容如下:
Mem: 191272k total 物理内存总量
173656k used 使用的物理内存总量
17616k free 空闲内存总量
22052k buffers 用作内核缓存 的内存量
Swap: 192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量。
内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,
该数值即为这些内容已存在于内存中 的交换区的大小。
相应的内存再次被换出时可不必再对交换区写入。
进程信息区统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境 下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存 百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理 内存大小,单位kb
s DATA 可执行代码以外的部分(数据 段+栈)占用的物理 内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。
D =不可中断的睡眠状态
R =运行
S =睡眠
T =跟踪/停止
Z =僵尸进程
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
更改显示内容通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
==============================
top命令使用过程中,还可以使用一些交互的命令来完成其它参数的功能。这些命令是通过快捷键启动的。
<空格>:立刻刷新。
P:根据CPU使用大小进行排序。
T:根据时间、累计时间排序。
q:退出top命令。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据使用内存大小进行排序。
W:将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
可以看到,top命令是一个功能十分强大的监控系统的工具,对于系统管理员而言尤其重要。但是,它的缺点是会消耗很多系统资源。
应用实例
使用top命令可以监视指定用户,缺省情况是监视所有用户的进程。如果想查看指定用户的情况,在终端中按“U”键,然后输入用户名,系统就会切换为指定用户的进程运行界面。
a.作用
free命令用来显示内存的使用情况,使用权限是所有用户。
b.格式
free [-b -k -m] [-o] [-s delay] [-t] [-V]
c.主要参数
-b -k -m:分别以字节(KB、MB)为单位显示内存使用情况。
-s delay:显示每隔多少秒数来显示一次内存使用情况。
-t:显示内存总和列。
-o:不显示缓冲区调节列。
d.应用实例
free命令是用来查看内存使用情况的主要命令。和top命令相比,它的优点是使用简单,并且只占用很少的系统资源。通过-S参数可以使用free命令不间断地监视有多少内存在使用,这样可以把它当作一个方便实时监控器。
#free -b -s5
使用这个命令后终端会连续不断地报告内存使用情况(以字节为单位),每5秒更新一次。
负载(load)是linux机器的一个重要指标,直观了反应了机器当前的状态。如果机器负载过高,那么对机器的操作将难以进行。
Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。
查看服务器负载有多种命令,w或者uptime都可以直接展示负载,
$ uptime
12:20:30 up 44 days, 21:46, 2 users, load average: 8.99, 7.55, 5.40
$ w
12:22:02 up 44 days, 21:48, 2 users, load average: 3.96, 6.28, 5.16
load average分别对应于过去1分钟,5分钟,15分钟的负载平均值。
这两个命令只是单纯的反映出负载,linux提供了更为强大,也更为实用的top命令来查看服务器负载。
$ top
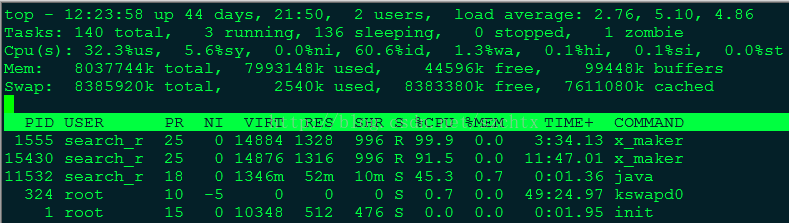
top命令能够清晰的展现出系统的状态,而且它是实时的监控,按q退出。
Tasks行展示了目前的进程总数及所处状态,要注意zombie,表示僵尸进程,不为0则表示有进程出现问题。
Cpu(s)行展示了当前CPU的状态,us表示用户进程占用CPU比例,sy表示内核进程占用CPU比例,id表示空闲CPU百分比,wa表示IO等待所占用的CPU时间的百分比。wa占用超过30%则表示IO压力很大。
Mem行展示了当前内存的状态,total是总的内存大小,userd是已使用的,free是剩余的,buffers是目录缓存。
Swap行同Mem行,cached表示缓存,用户已打开的文件。如果Swap的used很高,则表示系统内存不足。
在top命令下,按1,则可以展示出服务器有多少CPU,及每个CPU的使用情况
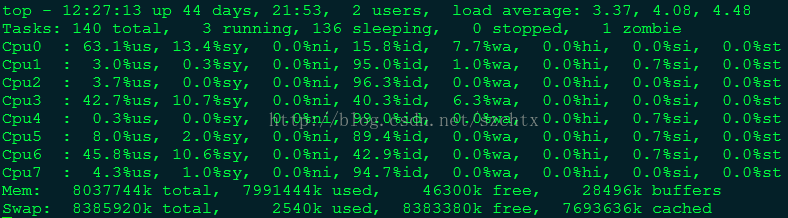
一般而言,服务器的合理负载是CPU核数*2。也就是说对于8核的CPU,负载在16以内表明机器运行很稳定流畅。如果负载超过16了,就说明服务器的运行有一定的压力了。
在top命令下,按shift + "c",则将进程按照CPU使用率从大到小排序,按shift+"p",则将进程按照内存使用率从大到小排序,很容易能够定位出哪些服务占用了较高的CPU和内存。
仅仅有top命令是不够的,因为它仅能展示CPU和内存的使用情况,对于负载升高的另一重要原因——IO没有清晰明确的展示。linux提供了iostat命令,可以了解io的开销。
输入iostat -x 1 10命令,表示开始监控输入输出状态,-x表示显示所有参数信息,1表示每隔1秒监控一次,10表示共监控10次。
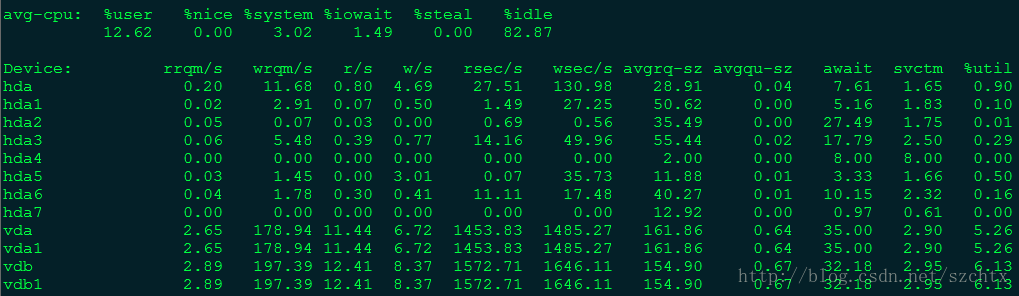
其中rsec/s表示读入,wsec/s表示每秒写入,这两个参数某一个特别高的时候就表示磁盘IO有很大压力,util表示IO使用率,如果接近100%,说明IO满负荷运转。
总结:
(1)使用top命令查看负载,在top下按“1”查看CPU核心数量,shift+"c"按cpu使用率大小排序,shif+"p"按内存使用率高低排序;
(2)使用iostat -x 命令来监控io的输入输出是否过大
参考:《鸟哥的Linux私房菜》
http://www.cnblogs.com/mfryf/archive/2012/03/12/2392012.html
最近一台linux服务器出现异常,系统反映很慢,相应的应用程序也无法反映,而且还出现死机的情况,经过几天的观察了解,发现服务器压力很大,主要的压力来自硬盘的IO访问已经达到100%
为了方便各位和自己今后遇到此类问题能尽快解决,我这里将查看linux服务器硬盘IO访问负荷的方法同大家一起分享:
首先 、用top命令查看
top - 16:15:05 up 6 days, 6:25, 2 users, load average: 1.45, 1.77, 2.14
Tasks: 147 total, 1 running, 146 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.2% us, 0.2% sy, 0.0% ni, 86.9% id, 12.6% wa, 0.0% hi, 0.0% si
Mem: 4037872k total, 4003648k used, 34224k free, 5512k buffers
Swap: 7164948k total, 629192k used, 6535756k free, 3511184k cached
查看12.6% wa
IO等待所占用的CPU时间的百分比,高过30%时IO压力高
其次、 用iostat -x 1 10
如果 iostat 没有,要 yum install sysstat
avg-cpu: %user %nice %sys %iowait %idle
0.00 0.00 0.25 33.46 66.29
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 1122 17.00 9.00 192.00 9216.00 96.00 4608.00 123.79 137.23 1033.43 13.17 100.10
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
查看%util 100.10 %idle 66.29
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
同时可以结合vmstat 查看查看b参数(等待资源的进程数)
vmstat -1
如果你想对硬盘做一个IO负荷的压力测试可以用如下命令
time dd if=/dev/zero bs=1M count=2048 of=direct_2G
此命令为在当前目录下新建一个2G的文件
我们在新建文件夹的同时来测试IO的负荷情况
再通过如下脚本查看高峰的进程io情况
monitor_io_stats.sh
#!/bin/sh
/etc/init.d/syslog stop
echo 1 > /proc/sys/vm/block_dump
sleep 60
dmesg | awk '/(READ|WRITE|dirtied)/ {process[$1]++} END {for (x in process) \
print process[x],x}' |sort -nr |awk '{print $2 " " $1}' | \
head -n 10
echo 0 > /proc/sys/vm/block_dump
/etc/init.d/syslog start
或者用iodump.pl脚本















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









