








 本文详细介绍了如何将MongoDB与Hadoop结合使用,通过Python、Ruby与JavaScript实现MapReduce函数进行数据统计,而不局限于Java。演示了从Twitter API导入数据、编写Map和Reduce函数、配置Hadoop环境并运行数据处理脚本的全过程。
本文详细介绍了如何将MongoDB与Hadoop结合使用,通过Python、Ruby与JavaScript实现MapReduce函数进行数据统计,而不局限于Java。演示了从Twitter API导入数据、编写Map和Reduce函数、配置Hadoop环境并运行数据处理脚本的全过程。
MongoDB 本身可以做一些简单的统计工作,包括其内置的基于 Javascript 的 MapReduce 框架,也包括在MongoDB 2.2版本中引入的新的统计框架。除此之外,MongoDB 还提供了对外部统计工具的接口,这就是本文要说的MongoDB-Hadoop的数据中间件。文章内容来源于MongoDB官方博客。
原理图解
MongoDB与Hadoop相结合的方式如下图所未,MongoDB作为数据源存储以及数据结果存储。而具体的计算过程在Hadoop中进行。

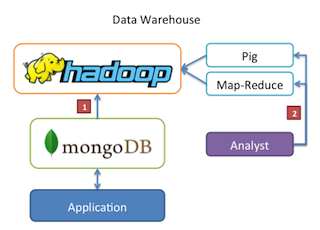
这一套处理流程,允许我们通过 Python, Ruby 与 JavaScript 来写MapReduce函数进行数据统计,而不是使用Java。
例子
首先准备好Hadoop环境,并安装好Hadoop,MongoDB中间件。然后通过下面的方式进行数据处理。
1.数据准备
从Twitter API导入原始数据到MongoDB中
curl https://stream.twitter.com/1/statuses/sample.json -u<login>:<password> | mongoimport -d twitter -c in
2.Map函数
写一个map函数,保存在文件mapper.rb 中
#!/usr/bin/env ruby
require 'mongo-hadoop'
MongoHadoop.map do |document|
{ :_id => document['user']['time_zone'], :count => 1 }
end
3.Reduce函数
然后是reduce函数,保存在文件reducer.rb中
#!/usr/bin/env ruby
require 'mongo-hadoop'
MongoHadoop.reduce do |key, values|
count = sum = 0
values.each do |value|
count += 1
sum += value['num']
end
{ :_id => key, :average => sum / count }
end
4.运行脚本
创建一个运行脚本,写入下面内容,就可以利用上面的MapReduce方法处理第一步中获取的数据。
hadoop jar mongo-hadoop-streaming-assembly*.jar -mapper mapper.rb -reducer reducer.rb -inputURI mongodb://127.0.0.1/twitter.in -outputURI mongodb://127.0.0.1/twitter.out
翻译自:blog.mongodb.org















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









