







论文题目:Synthetic to Real Adaptation with Generative Correlation Alignment Networks
作者:Xingchao Peng,Kate Saenko
来源: arxiv2017
1. 摘要
文章的想法是如果使用3D CAD建模的合成图片进行训练数据的数据增强,将会是一件非常有意义的事。然而,合成图片与真实图片之间存在较大的domain discrepancy,所以直接使用的效果甚微。本文提出了一种DGCAN的网络结构,使用shape preserving loss和low level statistic matching loss来减小特征空间中域之间的差异。
具体的,CAD合成图片具有很大的非真实性,其原因如下:
1)前景与背景的不匹配性很大
2)物体边缘和背景之间有很大的对比度
3)不逼真的场景
以上原因导致了合成图片与真实图片有很大的域差异
2. 文章的思路
2.1 总体的思路
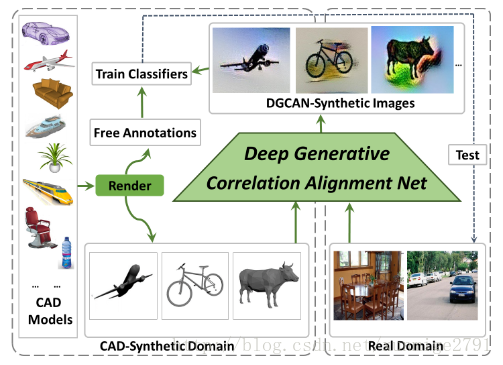
上图是总体的方法概略,使用DGCAN(Deep Generative Correlation Alignment Network)来生成inexpensive annotated training data。通过
综合物体的形状(从易获取的3D CAD中得到)以及结构纹理(从少量的真实图片中获得),最终在DGCAN-合成图片上进行训练,其效果有很大的改善。
设
Is={Ci,Yi}nsi=1
,其中
ns
是有标签的source domain的CAD合成图的数目,而设
It={Ri}nti=1
,其中的
nt
是所有target domain所有真实图片(无标签)的数目。本文的目的是合成一个有标签的中间数据集
I={Di,Yi}ni=1
,每个
Di∈I
的图片都与
Ci∈Is
包含类似的物体形状和轮廓,以及每个
Di∈I
的图片都与
R∈It
图片相类似的模式,颜色,纹理结构等。
为了从
C
和
R
中得到
D
,最直接的方法是直接对两个图片求平均。传统的方法如:half-half alpha blending以及pyramid blending仍会造成很大的domain shift。而本文的方法是在DCNN中将生成的
D
align到
C
,
R
中,或者反过来,用
D∼p(D|C,R)
来从
C
中合成
D
。
2.2 DGCAN的实现
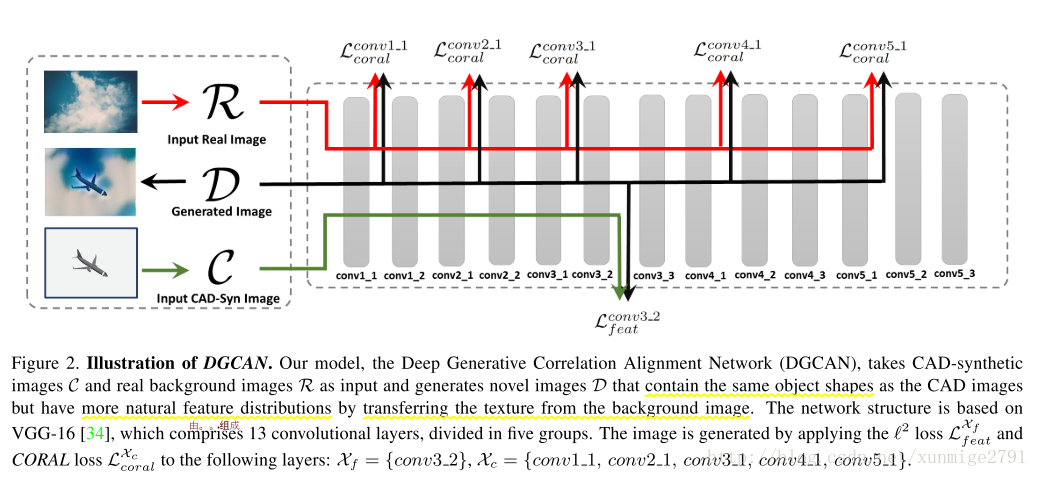
使用VGG-16作为基础架构,包含13个卷积层(conv1_1-conv5_3),3个全连接层(fc6-fc8),5个pooling层(pool1-pool5)。
令
Hl(⋅)
是DCNN的第
l
层的表达矩阵,
Hli(⋅)
是
Hl(⋅)
的第
i
个维度,
Hli,j(⋅)
是
Hli(⋅)
的第
j
个值
第一个loss是为了保证物体的轮廓保持一致,第二个Loss是为了图像与真实图片有相似的low-level的特征。
2.2.1 shape preserving loss
其中 D∈I,C∈Is ; ωsf 是第l层的loss weight; Xf 是所有加了 l2 loss的集合。 αl=NlFl , Nl 是第l层特征的通道数, Fl 是每个通道的特征长度
该loss关于激活值的导数是
2.2.2 naturalness loss
为了使生成的图片具有与真实图片相似的low-level的特征(纹理,边缘对比度,颜色等),这里使用了CORAL loss。Correlation Alignment(CORAL) 是[1]论文中提出的loss。用于match the second-order statistics of feature distributions for domain adaptation。
其中 D∈I,R∈It ; ωlc 是第l层的 COARL loss weight; Xc 是所有加了CORAL loss的集合。
参考原论文,协方差矩阵如下:
其中 M∈{D,R} , 1 是恒1列向量, Nl 是第l层的特征通道数
利用链式法则对CORAL求导得导数为:
最后总的loss是将两个结合起来。先对原始图像增加一个扰动 ϵ∼N(0,Σ) 。然后将图像送入DGCAN中关于 D 计算 l2 loss。关于 R 去计算 CORAL loss。合成图片通过如下规则得到:
2.3 实验结果
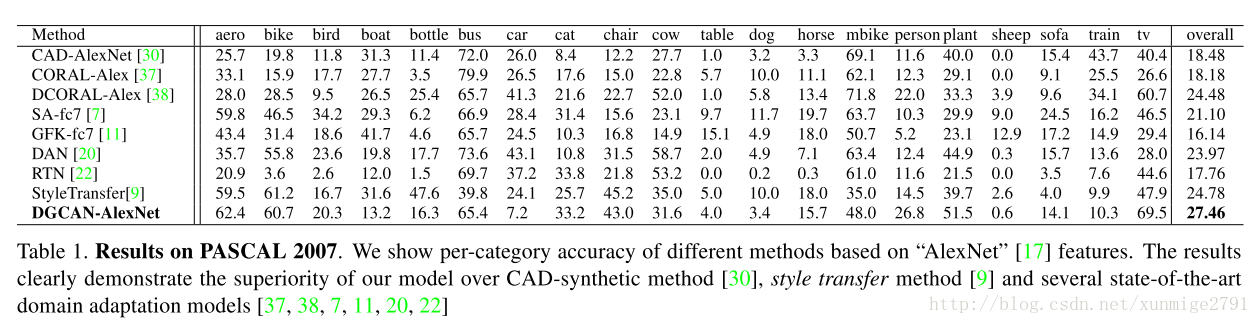
实验分两部分:1)用CAD合成图片和真实图片一起生成DGCAN合成图片;2)用现有的分类器在DGCAN合成图上进行训练

上图展示了根据两个输入(source domain:CAD合成图,target domain:真实图片)而产生的合成图。
1) 把
Lfeat
和
Lcoral
分别总用与不同的卷积层找到最合适的方案。左图展示了当把
Lfeat
作用于浅层卷积层时,DGCAN可以生成清晰的物体轮廓。当把
Lcoral
作用于更高层的卷积层时,DGCAN可以合成出更具结构化的纹理特征
2)改变trade-off参数
λ
,找到
λ
的最优值。右图显示当
λ
较小时,物体轮廓比背景纹理更占优势,反之亦然。

左侧的一组图是CAD合成图和它对应的生成好的DGCAN合成图,可以看到着色后的图片具有真实的图像轮廓和真实的纹理。使用【2】中的工具进行图像可视化处理。可以发现,DGCAN的合成图片与真实图片的差异较小。而单一的灰度图像(CAD合成图)仅提供了边缘信息(edge information).
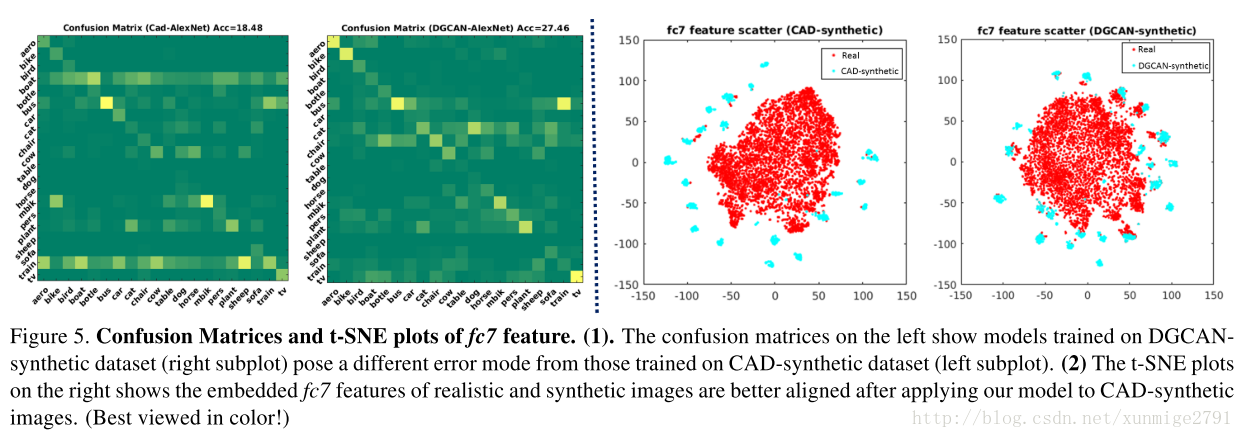
左边的是混淆矩阵(confusion matrix)大概理解是DGCAN合成图的错误模式和CAD合成图的错误模式大大不同,右图是t-SNE可视化的效果,可以得出DGCAN-合成图与原图的domian shift更小。
(混淆矩阵刚考完数据挖掘然后想起来了,以下摘自百度百科:混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类像比较计算的。混淆矩阵的每一列代表了预测类别 ,每一列的总数表示预测为该类别的数据的数目;所以上图中对角线值越高,表示分类越准确),
3.参考文献
[1] B. Sun, J. Feng, and K. Saenko. Return of frustratingly easy domain adaptation. arXiv preprint arXiv:1511.05547, 2015. 1, 2, 4, 6, 7, 8
[2]A. Mahendran and A. Vedaldi. Visualizing deep convolutional neural networks using natural pre-images. International Journal ofComputer Vision, pages 1–23, 2016. 5














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









