







原文:PostgreSQL源码修改 ——查询优化(三)
第三章 解决方案设计与实现
3.1 总体思路
3.1.1 参数的传递思路
从第二章的分析可以看出,在进入ExecLimit(LimitState *node) 函数之后,先调用recompute_limits(node);来计算limit_count和limit_offset,但这两个数据都是存入了LimitState *node中,而没有传入到其子结点(sort)的执行状态中去。因此,如果要让PostgreSQL对limit_count和limit_offset进行优化,首先要解决的问题就如何把这两个参数传入进去。
对于传递参数,我们有两种方案,其一是修改状态数据结构,在其成员域里增加我们需要传的变量。其二是修改被调用的函数的参数列表,但为了修改此函数的时候不影响PostgreSQL的其他部分的调用,最好的方式是增加一个新的函数,用这个新的函数来代替以前的函数,并在其形参里增加几个我们要传入的变量。
3.1.2 执行流程修改思路
现在假设在ExecSort(SortState *node) 中已经通过上述的思路获得了需要的数据,那又应该如何修改函数执行的流程以取得我们需要的优化呢?
从上一章的流程详细分析中,我们看到,ExecSort是调用tuplesort_performsort(Tuplesortstate *state)来完成排序,因此考虑对这个函数进行修改,在tuplesort_performsort内部,当为内排序时,直接调用快速排序来完成。从这个流程中我们可以很轻易的看出内排序的修改的地方:假设limit_count和limit_offset两个参数成功的传入到tuplesort_performsort函数,则可以写一个函数来代替快速排序来全排序,而只是把需要返回的元组放到正确的位置即可。
下面我们就对针对上述思路来设计和实现具体的解决方案。
3.2 简单选择置换方案
3.2.1 方案设计思路
阅读快速排序可以知道,在qsort_arg(void *a, size_t n, size_t es, qsort_arg_comparator cmp, void *arg)中,只是对以地址a开始的n个元组数据,对每项长为es元组排序后还是放在a处。
参数传入之后,如果limit_count和offset比较小的话,便只需用简单的比较选择算法(0、limit_count+limit_offset)个元组到(0、limit_count+limit_offset)位置上。
下面就如何传入参数和修改流程两个方面,设计和实现具体的解决方案来实现上述简单的比较选择算法。
3.2.2参数传递
在ExecLimit中,为了把limit_count 和limit_offset传入到ExecSort中,我们选择了第一种参数传递方案,即修改SortState结构体。在结构体增加三个域 bool hasLimit;int64 sort_count;int64 sort_offset;具体代码如下所示:
| // execnodes.h typedef struct SortState { ScanState ss; /* its first field is NodeTag */ bool randomAccess; /* need random access to sort output? */ bool sort_Done; /* sort completed yet? */ void *tuplesortstate; /* private state of tuplesort.c */
//ouyang 12-12—在代码中搜索ouyang,即可得到所有修改的地方. bool hasLimit; //是否为limit结点排序 int64 sort_count; //只需要排序的项数.在limit中,为limit_count int64 sort_offset; //从第几项开始排序.在limit中,为limit_offset } SortState; |
图表 15:SortState修改关键代码及注释
然后,在ExecLimit(LimitState *node)的计算完count/offset之后,添加几行代码,以把这两个参数传入到SortState中。关键代码列表如下:
| //nodeLimit.c TupleTableSlot * ExecLimit(LimitState *node) /* return: a tuple or NULL */ { TupleTableSlot *slot; PlanState *outerPlan; //获取子计划结点 outerPlan = outerPlanState(node); /* * ExecLimit状态变化及运动的逻辑主体 */ switch (node->lstate) { case LIMIT_INITIAL: //处理offset限制 //计算limit_count和offset等数据 recompute_limits(node); //判断参数是否合法 if (node->count <= 0 && !node->noCount) { node->lstate = LIMIT_EMPTY; return NULL; }
/*ouyang 12-11*/ if(outerPlan->type == T_SortState) { ((SortState *)outerPlan)->hasLimit = true; ((SortState *)outerPlan)->sort_count = node->count; ((SortState *)outerPlan)->sort_offset = node ->offset; } else { ((SortState *)outerPlan)->hasLimit = false; }
//处理至offset for (;;) { /*这里开始了第一次递归调用,在此递归调用中,会引有子计划结点的执行 根据我们的示例select * from teacher order by name limits 2 offset 1 和图,其子计划结点为T_SortState在即将运行的ExecProcNode中,将会运行result = ExecSort((SortState *) node); */ slot = ExecProcNode(outerPlan); if (TupIsNull(slot)) { //如果子计划返回的元组为空,即元组不够 node->lstate = LIMIT_EMPTY; return NULL; } //…… } /* * 我们已经通过执行子结点,获取了正确的元组,将状态修改为LIMIT_INWINDOW */ node->lstate = LIMIT_INWINDOW; //接下来返回的原组是满足要求的。 break; }
case LIMIT_INWINDOW: …… } return slot; } |
图表 16:ExecLimit修改关键代码及注释
最后,在ExecSort(SortState *node)函数中调用自己新添加的函数my_tuplesort_performsort(Tuplesortstate *state,int64 limit_count,int64 limit_offset),以传入两个加入的参数int64 limit_count,int64 limit_offset。
| //nodeSort.c TupleTableSlot *ExecSort(SortState *node) { EState *estate; Tuplesortstate *tuplesortstate; TupleTableSlot *slot; //获取执行状态 estate = node->ss.ps.state; tuplesortstate = (Tuplesortstate *) node->tuplesortstate; //如果还没有排序,则排序 if (!node->sort_Done) { tuplesortstate = tuplesort_begin_heap(tupDesc, plannode->numCols, plannode->sortOperators, plannode->sortColIdx, work_mem, node->randomAccess); //分配空间
//ouyang 12-12—在第二种优化的选择方案中,将添加下面几行,在此方案中,还无须添加 /*tuplesortstate -> hasLimit = node ->hasLimit; tuplesortstate -> sort_count = node ->sort_count; tuplesortstate -> sort_offset = node ->sort_offset;*/ node->tuplesortstate = (void *) tuplesortstate; //下面的循环是调用其子计划结点来获取待排序的元组,在示例语句中,此子计划为T_SeqScan类型,由ExecSeqScan来执行 for (;;) { slot = ExecProcNode(outerNode); //在这里outerNode是一种方法取出数据库中数据,比方说ExecSeqScan() 方式 //运行:每一次从outerNode返回一个元组 if (TupIsNull(slot)) break; tuplesort_puttupleslot(tuplesortstate, slot); //放入刚取出的元组 } /*ouyang 12-10――当父计划结点hasLimit时,调用my_tuplesort_performsort 否则还调用以前的函数*/ if(node->hasLimit) { my_tuplesort_performsort(tuplesortstate,node ->sort_count,node->sort_offset); } else { tuplesort_performsort(tuplesortstate); } //完成排序――现在被上面的语句代替 //tuplesort_performsort(tuplesortstate); //分为内排序(快速排序)和外排序两种情况 //…… } slot = node->ss.ps.ps_ResultTupleSlot; //返回一个排序后的元组,关键的是puttuple_common()函数的实现 (void) tuplesort_gettupleslot(tuplesortstate, ScanDirectionIsForward(dir), slot); return slot; } |
图表 17:ExecSort修改关键代码 及注释
在参数传递成功之后,来看一下最为关键的排序的完成函数的方案及实现。
3.2.3 流程修改
在my_tuplesort_performsort(Tuplesortstate *state,int64 limit_count,int64 limit_offset)函数内部,我们添加了一个分支,用来处理需要优化的分支:代码及注释如下:
| // tuplesort.c void my_tuplesort_performsort(Tuplesortstate *state,int64 limit_count,int64 limit_offset) { MemoryContext oldcontext = MemoryContextSwitchTo(state->sortcontext); switch (state->status) { case TSS_INITIAL: //如果有足够的内存来完成排序,则直接在内存中调用快速排序来完成 if (state->memtupcount > 1) //limit_count+limit_offset in (0 ,logn),只有此时才优化执行 if(state -> hasLimit && state -> sort_count>0&& state -> sort_count<=log(state->memtupcount)&& state -> sort_offset>=0 && (state -> sort_offset+state -> sort_count) < (state->memtupcount +1)) { // 此时调用简单选择算法将极大的优化执行 my_simple_select_sort((void *) state->memtuples, state->memtupcount, sizeof(SortTuple), (qsort_arg_comparator) state->comparetup, (void *) state,limit_count,limit_offset);//12-10:have not think about the offset.wrong!! //12-11:correct it } else { qsort_arg((void *) state->memtuples, state->memtupcount, sizeof(SortTuple), (qsort_arg_comparator) state->comparetup, (void *) state); } //以前的分支,现在注释掉 /*qsort_arg((void *) state->memtuples, state->memtupcount, sizeof(SortTuple), (qsort_arg_comparator) state->comparetup, (void *) state);*/ state->current = 0; //output run number,初始值为 //…… break; case TSS_BUILDRUNS: //否则进入外排序分支 //…… break; default: elog(ERROR, "invalid tuplesort state"); break; } MemoryContextSwitchTo(oldcontext); } |
图表 18:my_tuplesort_performsort关键代码及注释
最后是我们的终极目标:设计my_simple_select_sort算法。我们采用的最简单的比较选择算法。关键代码及注释如下:
| //qsort_arg.c /*ouyang 12.10*/ void my_simple_select_sort(void *a, size_t n, size_t es, qsort_arg_comparator cmp, void *arg,int64 select_count, int64 select_offset) { char *pi,*pIterator,*pMin; int64 i,j; int swaptype;
if(select_count<=0|| select_count+select_offset > n+1) return;
SWAPINIT(a, es);
/*select_count in 0 to logn*/ if(select_count<=0||select_count >n-1) return;
for(i=select_offset;i<select_count+select_offset;++i) { pi=(char *)a+es*i; pMin=(char *)a+es*i; /*find the i min item and swap*/ for( j=i+1;j<n;++j)//compare items after offset { pIterator = (char *)a+es*j; if(cmp(pMin,pIterator,arg) > 0) { pMin = pIterator; } } for( j=select_offset-1;j>=0;--j)//compare items before offset { pIterator = (char *)a+es*j; if(cmp(pMin,pIterator,arg) > 0) { pMin = pIterator; } }
if(pMin!=pi)//swap if necesary { swap(pMin,pi); } } } |
图表 19:my_simple_select_sort算法实现代码及注释
最后让我们看一下优化后的执行代价分析。
3.2.4 代价分析
当limit_count+limit_offset 为常数时,总体代价为O(N),当limit_count+limit_offset在 (0 ,logn)范围时,最差代价也为O(N*logN).因此,还是取得了比较大的优化效果。
但是,当limit_offset比较大时,而limit_count比较小,比如为1,也就是只需返回1个元组时,此算法却必须对limit_offset+limit_count个元组选择排序,这也增加了算法了复杂度,而且也使得这个算法的适用性大为的降低,按要求,应该是limit_count比较小时都应该得到优化。
因此,在此基础上,我们将实现更为高效的Select(S,K)算法,从而解决这些问题。这也是本文将要介绍的下一个方案:Select(S,K)。
3.3 Select(S,K)算法方案
3.3.1 方案设计思路
在前一个简单选择方案中,算法的代价和适用性都受限于本来“无关紧要”的limit_offset参数,为了解决此问题,我们设计了一个Select(S,K)算法方案,该算法采用分置算法,每次在集合S中选择一个第K小的数来,无论K为多大,当然要在(0,N)中,总体代价均为O(N)。
基本的实现思路和前一个方案大同小异,只是最后的排序排序算法比较复杂。我们将简要的介绍参数的传递,再集中精力放在Select(S,K)算法上。
Select(S,K)的算法思想和伪码如下:
| 1.将S划分成5个一组,共nM=n/5个组 2.每组找中位数,nM个中位数放到集合M. 3.m*←Select(M,|M|/2) 将S中的数划分成A,B,C,D四个 集合 4.把A和D中的每个元素与m*比较,小的构成S1, 大的 构成S2; 5.S1←S1∪C; S2←S2∪B; 6.if k =|S1|+1 then 输出m* 7.else if k≤|S1| 8. then Select(S1,k) 9. else Select(S2,k-|S1|-1) |
图表 20:Select(S,K)的算法思想和伪码
其中算法第4步示意图如下:
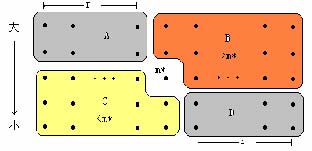
图表 21:Select(S,K)中子问题示意图
3.3.2参数传递
可以和前面的相同,只是把my_simple_select_sort换成my_opt_select_sort
3.3.3 流程修改
select_s_k算法及其他相关函数的代码及注释如下表:
| //qsort_arg.c /*ouyang 12.11*/ /*ouyang*/ char * select_s_k(char * * p,size_t k, void *a, size_t n, size_t es, qsort_arg_comparator cmp, void *arg,int64 select_count, int64 select_offset); char * findSmallN(char **p,size_t n,size_t k,qsort_arg_comparator cmp, void *arg); #define SELECTSK 5 //5个为一组 #define SELECTSKMID 3 //5的中间数为
/*ouyang 12.11*/ //何用select_s_k算法来实现的更复杂而优化的选择“部分排序”算法 void my_opt_select_sort(void *a, size_t n, size_t es, qsort_arg_comparator cmp, void *arg,int64 select_count, int64 select_offset) { /*the arrang of point*/ char ** p;//指针数组,每个地址都指向待排序的N个项中的某个项. size_t i; int swaptype; char *temp;
// 检查参数的有效性 if(select_count<=0|| select_count+select_offset > n+1|| select_offset <0) return;
SWAPINIT(a, es); /*指针数组初始化*/ p = (char **)malloc(n*sizeof(char *)); for(i=0;i<n;i++) { p[i]=(char*)a+es*i; } /*循环调用select_s_k算法并,并将选择的第K个元素交换到相应的位置*/ for(i=select_offset;i<select_count+select_offset;i++) { temp = select_s_k(p, i+1, a, n, es, cmp, arg, select_count, select_offset); if(temp!=(char *)a+es*(i)) { swap(temp,(char *)a+es*(i)); } } free(p); }
// select_s_k实现,采用算法课上的select_s_k分置算法 char * select_s_k(char * * p,size_t k, void *a, size_t n, size_t es, qsort_arg_comparator cmp, void *arg,int64 select_count, int64 select_offset) { size_t i,j; size_t t; int swaptype; char ** pSmaller;//比m*小的项的指针数组.m*的意义请参见select_s_k算法思路及示意图. char ** pLarger;//比m*大的或等于的指针数组. char ** pMid;//按个一组分组后,存入每组的中位数. char *pTemp; size_t smallerInder,largerInder;//pSmaller与pLarger指针的索引
smallerInder = largerInder=0;
if(n<=SELECTSK) { return findSmallN(p,n,k,cmp, arg); }
SWAPINIT(a, es);
pSmaller = (char **)malloc(n*sizeof(char *)); pLarger = (char **)malloc(n*sizeof(char *)); pMid = (char **)malloc((n/SELECTSK+1)*sizeof(char *));
/*devide with SELECTSK and find the mid one , and put it's address to pMid*/ for(i=0,j=0;i<n-SELECTSK;i+=SELECTSK,j++) { pMid[j]=findSmallN(&p[i],SELECTSK,SELECTSKMID,cmp, arg); } // 递归调用select_s_k求pMid的中位数 pTemp = select_s_k( pMid, (j+1)/2, a, j, es, cmp, arg, select_count, select_offset); // 下面的两个循环是将ABCD四个集体分配到pSmaller和pLarger两个集合中. for(i=0;i<n-SELECTSK;i+=SELECTSK) { if(cmp(p[i+SELECTSKMID-1],pTemp,arg)>=0) { for(t=0;t<SELECTSKMID-1;t++) { if(cmp(p[t+i],pTemp,arg)>=0) { pLarger[largerInder]=p[t+i]; largerInder++; } else { pSmaller[smallerInder]=p[t+i]; smallerInder++; } } for(t=SELECTSKMID-1;t<SELECTSK;t++) { pLarger[largerInder]=p[t+i]; largerInder++; } } else/*cmp(p[i+SELECTSKMID-1],pTemp,arg)<0*/ { for(t=0;t<SELECTSKMID;t++) { pSmaller[smallerInder]=p[t+i]; smallerInder++; } for(t=SELECTSKMID;t<SELECTSK;t++) { if(cmp(p[t+i],pTemp,arg)>=0) { pLarger[largerInder]=p[t+i]; largerInder++; } else { pSmaller[smallerInder]=p[t+i]; smallerInder++; } } } } // 处理没有除尽SELECTSK时,剩余的元素. for(;i<n;) { if(cmp(p[i],pTemp,arg)>=0) { pLarger[largerInder]=p[i]; largerInder++; } else { pSmaller[smallerInder]=p[i]; smallerInder++; } i++; }
// 如果恰好有smallerInder比pTemp小,则pTemp即为解. if(k==(smallerInder+1)) {
} // 否则缩小子问题,递归调用求解. else if(k<(smallerInder+1)) { pTemp = select_s_k(pSmaller,k, a, smallerInder, es, cmp, arg, select_count, select_offset); } else { if(smallerInder>0) { pTemp = select_s_k(pLarger,k-smallerInder, a, largerInder, es, cmp, arg, select_count, select_offset); } else//!!ouyang 12-15找到一个巨大的BUG,当smallerInder为时,即所选的pTemp刚好就是最小无元素之时,如果不加这个分支,会导致死循环!!!! //由于largerInder中包含和pTemp相等的元素,故不可能为,不用考虑。 {
for(i=0;i<largerInder;i++) { if(pLarger[i]==pTemp) { //swap to position 0 pTemp= pLarger[0]; pLarger[0]=pLarger[i]; pLarger[i]=pTemp;
break; } } pTemp = select_s_k(&pLarger[1],k-smallerInder-1, a, largerInder-1, es, cmp, arg, select_count, select_offset); } } // 释放内存 free(pMid); free(pSmaller); free(pLarger); return pTemp; }
// 当n比较小时,直接调用此函数来找到第k小的数. char * findSmallN(char **p,size_t n,size_t k,qsort_arg_comparator cmp, void *arg) { size_t i,j; char *temp; for (i=1;i<n;i++) //采用插入排序 { for(j=i;j>0;j--) { if(cmp(p[j-1],p[j], arg) > 0) { temp=p[j-1]; p[j-1]=p[j]; p[j]=temp; } } } return p[k-1];//返回k-1,是因为第k小,是从开始记数,而数组下标却从开始记数. } |
图表 22:Select(S,K)所有相关代码及注释
3.3.4 代价分析
对于Select(S,K)算法,每执行一次的代价为O(N).分析如下.下图为子问题情况:
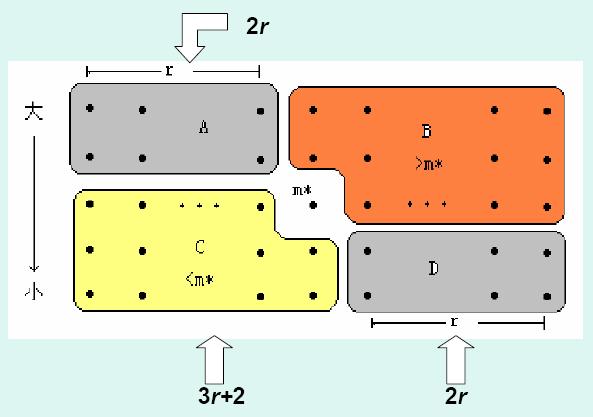
图表 23:Select(S,K)子问题规模示意图
最坏情况:子问题大小为2r+2r+3r+2=7r+2
不妨设n=5(2r+1), |A|=|D|=2r,
r=(n/5-1)/2=n/10-1/2
行2: O(n);
行3: W(n/5);
行4: O(n);
W(7r+2) = W((n/10-1/2)+2)=W(7n/10-3/2)<=W(n/7).
W(n)<=W(n/5)+W(7n/10)+cn<=cn+(9/10)cn+(81/100)*cn+…=O(n)
因此,Select(S,K)每执行一次的代价是:O(n),当limit_count在(n,logn)范围时,算法代价为O(m*n)<O(n*logn),当m<<n,时,算法代价为接近O(n)。
3.4 外存修改方案
3.4.1 方案设计思路
从前面的外存处理的流程分析中可以得知:
mergeruns实现了多阶段算法中的D5与D6步,在mergeruns中,会调用beginmerge(Tuplesortstate *state)来从外存中获取元组数据放入到内存中进行归并排序。在beginmerge(Tuplesortstate *state)中,每次只取一个元组进行归并。
因此,如果我们能知道需要排序的项数,则可以在这个函数中去控制拿的项数,以减少访外的次数。
我们的思路也是如此,要做的工作是把控制排序循环的参数m传入给外排序函数。因为PostgreSQL中的外排序处理为每次将每个tape中选出最前面的一个数据放在一起建堆、排序,再放回一个outputtape。为了进行最少次数的扫描,我们只需让其对每个tape中的前m个进行扫描排序即可。这样循环次数为m即可。
3.4.2 参数传递
由于对于外存的排序,牵涉到的函数比较多,如果我们还以传递参数中的第二种方案来传递sort_count和sort_offset的话,一定要修改更多的函数才行。
为了避免做太大的修改,也为了有更大的扩展性,我们采用第一种方案,即修改Tuplesortstate数据结构。
但是,由于Tuplesortstate的结构定义在C文件,而非头文件中,我们必须得把所有的Tuplesortstate定义代码都行拷贝进需要访问Tuplesortstate结构体的文件nodeSort.c中,和SortState一样,增加三个域: bool、hasLimit; int64 sort_count; int64 sort_offset;,另外,还增加bool isEnough;,用来指示排好序的元组是否已经足够,即大于sort_count+sort_offset,如果已经足够,则无须进行下面的排序 。
对Tuplesortstate的修改代码如下:
| /*修改文件: tuplesort.c nodeSort.c */
/*ouyang 12-12 copy from tuplesort.c*/ typedef struct { void *tuple; /* the tuple proper */ Datum datum1; /* value of first key column */ bool isnull1; /* is first key column NULL? */ int tupindex; /* see notes above */ } SortTuple;
typedef enum { TSS_INITIAL, /* Loading tuples; still within memory limit */ TSS_BUILDRUNS, /* Loading tuples; writing to tape */ TSS_SORTEDINMEM, /* Sort completed entirely in memory */ TSS_SORTEDONTAPE, /* Sort completed, final run is on tape */ TSS_FINALMERGE /* Performing final merge on-the-fly */ } TupSortStatus;
#define MINORDER 6 /* minimum merge order */ #define TAPE_BUFFER_OVERHEAD (BLCKSZ * 3) #define MERGE_BUFFER_SIZE (BLCKSZ * 32)
struct Tuplesortstate { TupSortStatus status; /* enumerated value as shown above */ int nKeys; /* number of columns in sort key */ bool randomAccess; /* did caller request random access? */ long availMem; /* remaining memory available, in bytes */ long allowedMem; /* total memory allowed, in bytes */ int maxTapes; /* number of tapes (Knuth's T) */ int tapeRange; /* maxTapes-1 (Knuth's P) */ MemoryContext sortcontext; /* memory context holding all sort data */
/*ouyang 12.10*/ bool hasLimit; int64 sort_count; int64 sort_offset;
bool isEnough;/*is enough to sort_count+sort_offset.*/ /*used in external sort*/
/* 排序用到的各种函数 */ int (*comparetup) (const SortTuple *a, const SortTuple *b, Tuplesortstate *state); void (*copytup) (Tuplesortstate *state, SortTuple *stup, void *tup); void (*writetup) (Tuplesortstate *state, int tapenum, SortTuple *stup); void (*readtup) (Tuplesortstate *state, SortTuple *stup, int tapenum, unsigned int len); //…… //下面还有一些内排序和外排序需要用到的一些数据。 }; |
图表 24:Tuplesortstate修改代码及注释
然后ExecSort中把SortState *node中的变量值赋值给Tuplesortstate。代码如下:
| //nodeSort.c TupleTableSlot *ExecSort(SortState *node) { EState *estate; Tuplesortstate *tuplesortstate; TupleTableSlot *slot; //获取执行状态 estate = node->ss.ps.state; tuplesortstate = (Tuplesortstate *) node->tuplesortstate; //如果还没有排序,则排序 if (!node->sort_Done) { tuplesortstate = tuplesort_begin_heap(tupDesc, plannode->numCols, plannode->sortOperators, plannode->sortColIdx, work_mem, node->randomAccess); //分配空间
//ouyang 12-12 tuplesortstate -> hasLimit = node ->hasLimit; tuplesortstate -> sort_count = node ->sort_count; tuplesortstate -> sort_offset = node ->sort_offset; node->tuplesortstate = (void *) tuplesortstate; //下面的循环是调用其子计划结点来获取待排序的元组,在示例语句中,此子计划为T_SeqScan类型,由ExecSeqScan来执行 …… return slot; } |
图表 25:Tuplesortstate的参数传递
这样,在后面的所有排序中,只要传递了Tuplesortstate *的参数,就可以获得以上四个变量。
3.4.3 流程修改
在总体思路中,我们已经确定了修改beginmerge(Tuplesortstate *state)来控制一次放入内存中元组的数量。具体代码如下:
| // tuplesort.c static void beginmerge(Tuplesortstate *state) { /*ouyang 12-12*/ int64 j=0; int64 i; int64 nSortedCount = state->sort_count+state->sort_offset; …… /* * Preread as many tuples as possible (and at least one) from each active * tape */ mergepreread(state);
/* Load the merge heap with the first tuple from each input tape */ for (srcTape = 0; srcTape < state->maxTapes; srcTape++) { int tupIndex = state->mergenext[srcTape]; SortTuple *tup; /* ouyang 12-12 每次尽量多的加入元组,如果每组都加入了(sort_count+sort_offset)个,则表示已经足够,算法结束。 */ if(state -> hasLimit && state -> sort_count>0&& state -> sort_offset>=0 && (state -> sort_offset+state -> sort_count) < (state->memtupcount +1)) { for(i=0;i<nSortedCount;i++) { tupIndex = state->mergenext[srcTape]; if (tupIndex) { tup = &state->memtuples[tupIndex]; state->mergenext[srcTape] = tup->tupindex; if (state->mergenext[srcTape] == 0) state->mergelast[srcTape] = 0; tuplesort_heap_insert(state, tup, srcTape, false); /* put the now-unused memtuples entry on the freelist */ tup->tupindex = state->mergefreelist; state->mergefreelist = tupIndex; state->mergeavailslots[srcTape]++;
/*ouyang 12-12*/ j++; } else//this tape is empty. { break; } }
} else//not modefied { if (tupIndex) { tup = &state->memtuples[tupIndex]; state->mergenext[srcTape] = tup->tupindex; if (state->mergenext[srcTape] == 0) state->mergelast[srcTape] = 0; tuplesort_heap_insert(state, tup, srcTape, false); /* put the now-unused memtuples entry on the freelist */ tup->tupindex = state->mergefreelist; state->mergefreelist = tupIndex; state->mergeavailslots[srcTape]++; } } } if(j>=nSortedCount) { state ->isEnough = true; } } |
图表 26:beginmerge修改关键代码及注释
3.4.4 优化分析
由于我们没有找到足够大的数据库来测试外存的情况,因此这个阶段的分析只能停留在理论阶段。由于不用每个tape都取完所有的元素,而最多只需要取count+offset个,显然大大的减少了运算量和访问外存的次数。
第四章 解决方案测评
4.1 测评方案
由于时间比较紧张,我们只对Select(S,K)算法进行了评测。
我们选用的用例是:在运行前一个约950个元组的表,运行语句是:select * from teacher order by name limit 1 offset 930.
采用的方式也比较粗糙,用记录时间的方式来计算在优化前和优化后的运行时间。
具体的代码为:
| //nodeSort.c #include <time.h>//添加此头文件
// 添加这些变量来记录时间,并把时间输出到文件中 clock_t start,end; double duration; FIFE *fp;
//ExecSort加时间 TupleTableSlot *ExecSort(SortState *node) { EState *estate; Tuplesortstate *tuplesortstate; TupleTableSlot *slot; //获取执行状态 estate = node->ss.ps.state; tuplesortstate = (Tuplesortstate *) node->tuplesortstate; //如果还没有排序,则排序 if (!node->sort_Done) { tuplesortstate = tuplesort_begin_heap(tupDesc, plannode->numCols, plannode->sortOperators, plannode->sortColIdx, work_mem, node->randomAccess); //分配空间
node->tuplesortstate = (void *) tuplesortstate; //下面的循环是调用其子计划结点来获取待排序的元组,在示例语句中,此子计划为T_SeqScan类型,由ExecSeqScan来执行 for (;;) { slot = ExecProcNode(outerNode); //在这里outerNode是一种方法取出数据库中数据,比方说ExecSeqScan() 方式 //运行:每一次从outerNode返回一个元组 if (TupIsNull(slot)) break; tuplesort_puttupleslot(tuplesortstate, slot); //放入刚取出的元组 }
//ouyang 12-12 加入时间代价计算 start = clock();
/*ouyang 12-10――当父计划结点hasLimit时,调用my_tuplesort_performsort 否则还调用以前的函数*/ if(node->hasLimit) { my_tuplesort_performsort(tuplesortstate,node ->sort_count,node->sort_offset); } else { tuplesort_performsort(tuplesortstate); }
end = clock();
druation = (end - start)/(double)CLOCKS_PER_SEC; fp = fopen("result.txt","w");//输出时间到文件 fprintf(fp,"%9.4/n",duration); fclose(fp);
//完成排序――现在被上面的语句代替 //tuplesort_performsort(tuplesortstate); //分为内排序(快速排序)和外排序两种情况 //…… } slot = node->ss.ps.ps_ResultTupleSlot; //返回一个排序后的元组,关键的是puttuple_common()函数的实现 (void) tuplesort_gettupleslot(tuplesortstate, ScanDirectionIsForward(dir), slot); return slot; }
|
图表 27:测试方案实现代码
4.2 测试结果
测试结果为当没有优化时:运行时间为0.0200,优化后结果为0.0100。这说明运行时间整整比优化前快了一倍。当然,我们没有选用足够多的用例进行测试,但已经说明了一些优化的有效性,而且与offset无关。
4.3 总体评价
4.3.1 时间复杂度大为降低
其中Select(S,K)算法,当limit_count不超过logn时,最大的代价不会超过n*logn,当limit_count远小于n时,事实上这是实际中最经常遇到的情况,时间复杂度为O(n)。可以说,已经达到了比较明显的优化目的。
在实现完Select(S,K)算法之后,我们本来还准备在内存的优化中还实现堆算法,但发现堆算法和简单选择算法一样,都会极大的受offset影响。比如select * from teacher order by name limit 1 offset 930.语句,无论如何建堆,都要出堆930次,因此,总的时间效率和快速排序一样,没有什么意义。
另外,在Select(S,K)的实现中,我们采用了二重指针,即只对指针排序,只交换和移动指针,这对于元组数据块非常大时有非常明显的优势,可以极大的提高数据存取效率。
4.3.2 扩展性很好
在实现完所有的优化完之后,我们都采用了数据结构的方案来传递参数,这对于未来要修改其他函数有极大的帮助。和修改函数形参列表相比,本方案扩展性也更强。
另外,我们实现的Select(S,K)算法,是和qsort_arg算法一样,直接对字节进行操作排序,也就是说与实际的数据结构无关。在未来以后其他的地方,很容易的就可以移植使用。
4.3.3 健壮性比较强
对于Select(S,K),我们运行测试了几乎所有的测试用例,从offset的有效和无效性,到count的参数有效、无效时,到表比较大的各种情况,在测试时遇到了各种情况,我们都找到了原因并进行了相应的修改。其中有一个匪夷所思所思的死循环花生在当比取的那个各组中位数小的元素和数为0的时候,详细情况在实习总结章节有记录。















 2509
2509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









