







之前学习Python爬虫采集,为了练手用Scrapy写了一个爬虫,整整采集了京东平台vivo旗舰店7万多条评论。一直也没觉得这些评论数据有啥用,就留在MongoDB中吃灰。最近学了jieba和wordcloud之后,突发奇想着分析下这7万多条评论数据,然后生成一个词云图(如下图)。从词云图中可以知道vivo的口碑还是挺好的,拍照效果、外形外观和运行速度这三方面是消费者比较认可的。

一、导入评论数据集
7万多条评论数据,假设每条评论分词后有10个词,那可就是70多万个词,说多不算多,但是说少也不少了。
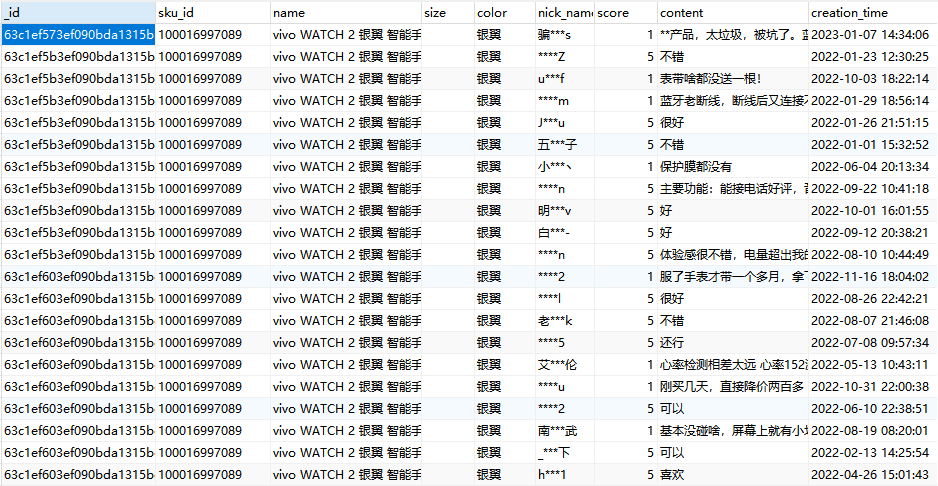
如果传统地使用循环语句逐条读取数据处理,那还真不知道得处理多久。所以这里使用数据分析神器(pandas)来处理,先将数据集导入:
df = pd.read_csv('jd_goods_comment.csv')
如果需要数据集“jd_goods_comment.csv”的,可以关注微信公众号【愤怒的it男】,私聊号主获取。
二、评论分词拼接
通过apply()方法对每一条评论数据进行分词,然后再使用join()将每个词以空格为间隔拼接成字符串,最后使用聚合函数sum()将每一条处理后的评论字符串拼接成一长串字符串。
def segmentation(x):
return ' '.join(jieba.lcut(x))+' '
text = df['content'].apply(segmentation).sum()
三、生成词云图
这里将上面的长串字符串生成词云图,设置词云图背景为白色,字体为“FZYTK.TTF”,蒙版为“angry_it_man_mask.png”
mask_picture = np.array(Image.open('angry_it_man_mask.png'))
wc = WordCloud(background_color='white',font_path='FZYTK.TTF',mask=mask_picture)
wc.generate(text)
wc.to_file('wordcloud.png')
如果需要字体文件“FZYTK.TTF”和蒙版图片“angry_it_man_mask.png”的,可以关注微信公众号【愤怒的it男】,私聊号主获取。
四、完整代码
import pandas as pd
import jieba
from PIL import Image
from wordcloud import WordCloud
import numpy as np
import time
start_time = time.time()
def segmentation(x):
return ' '.join(jieba.lcut(x))+' '
df = pd.read_csv('jd_goods_comment.csv')
text = df['content'].apply(segmentation).sum()
mask_picture = np.array(Image.open('angry_it_man_mask.png'))
wc = WordCloud(background_color='white',font_path='FZYTK.TTF',mask=mask_picture)
wc.generate(text)
wc.to_file('wordcloud.png')
end_time = time.time()
print("代码执行时间:", end_time - start_time)
从数据处理到词云图生成,整个过程只用了3分钟左右,个人还是挺满意的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









