



Spring容器的启动
博客链接:
从Spring容器的启动开始,一篇文章带你搞懂SpringIOC加载过程
SpringBean的生命周期
非常建议看看这个视频,这位up主讲的真的太清楚了
教学视频:小白也能懂的最详细之spring-bean生命周期讲解
总的来说就是
- 调用构造方法实例化Bean对象
- 设置Bean属性(调用Bean的set方法)
- 如果Bean实现各种Aware接口,则会注入Bean对容器基础设施层面的依赖。Aware接口具体包括BeanNameAware、BeanFactoryAware、ApplicationContextAware,分别注入Bean ID、Bean Factory或者ApplicationContext
- 如果定义了一个类实现了BeanPostProcessor,调用重写BeanPostProcessor的前置初始化方法postProcessBeforeInitialization
- 如果Bean实现InitializingBean接口,则会调用afterPropertiesSet方法
- 调用Bean自身的init方法(配置init-method)
- 如果定义了一个类实现了BeanPostProcessor,调用重写BeanPostProcessor的后置方法postProcessAfterInitialization(aop的处理在这里进行)
- 使用Bean
- 如果Bean实现DisposableBean,则会调用destroy方法 10、调用Bean自身的destroy方法(配置destroy-method)
什么是Spring的循环依赖问题
在Spring框架中,循环依赖就是指两个或者多个bean之间相互依赖,形成了一个循环引用的情况。如果不加以处理,这种情况会导致应用启动失败
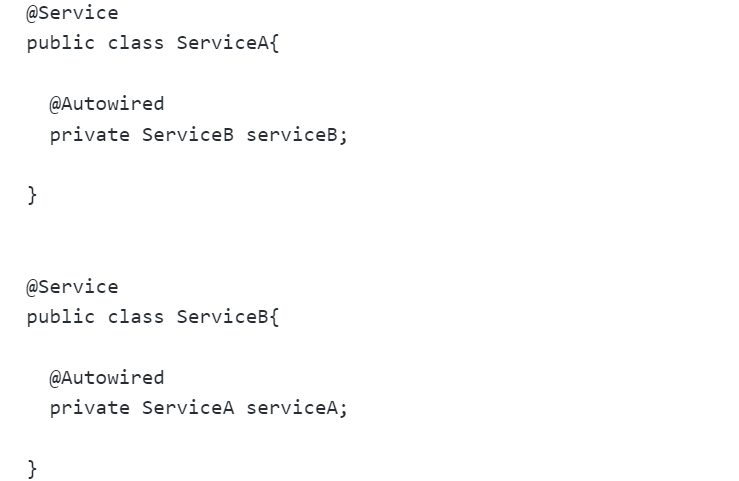
就像下面的情况
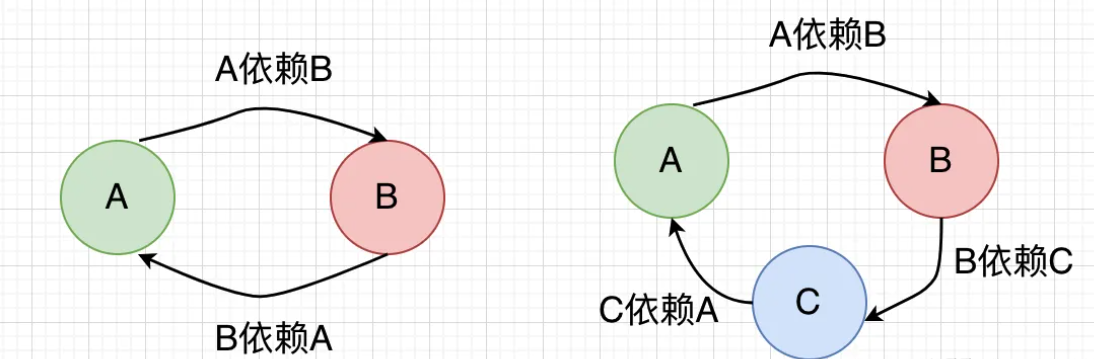
在Spring中,解决循环依赖的方式就行引入三级缓存
什么是Spring的三级缓存
在Spring的BeanFactory体系中,BeanFactory是Spring loC容器的基础接口,其DefaultSingletonBeanRegistry类实现了BeanFactory接口,并且维护了三级缓存。
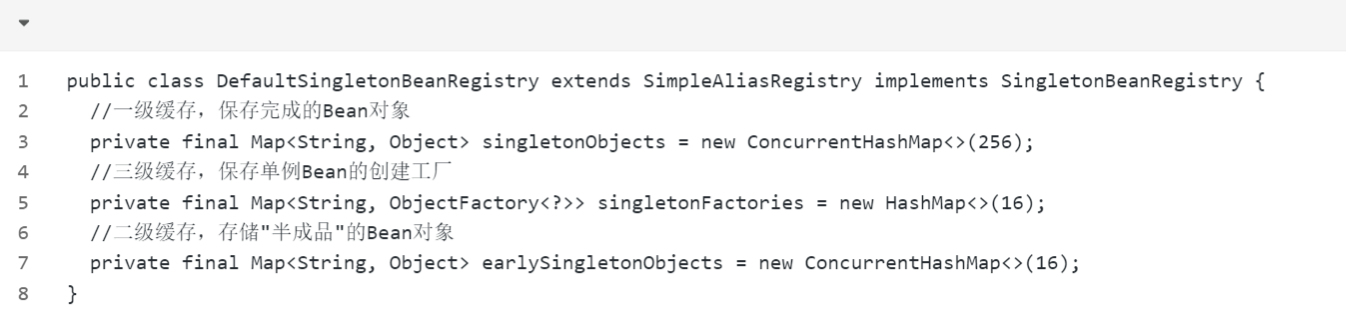
singletonObiects是一级缓存,存储的是完整创建好的单例bean对象。在创建一个单例bean时,会先从singletonObjects中尝试获取该bean的实例,如果能够获取到,则直接返回该实例,否则继续创建该bean。
earlySingletonObjects是二级缓存,存储的是尚未完全创建好的单例bean对象。在创建单例bean时,如果发现该bean存在循环依赖,则会先创建该bean的"半成品“对象,并将"半成品"对象存储到earlvSingletonObjects中。当循环依赖的bean创建完成后,Spring会将完整的bean实例对象存储到singletonObiects中,并将earlySingletonObjects中存储的代理对象替换为完整的bean实例对象。这样可以保证单例bean的创建过程不会出现循环依赖问题。
singletonFactories是三级缓存,存储的是单例bean的创建工厂。当一个单例bean被创建时,Spring会先将该bean的创建工厂存储到singletonFactories中,然后再执行创建工厂的getObject()方法,生成该bean的实例对象。在该bean被其他bean引用时,Spring会从singletonFactories中获取该bean的创建工厂,创建出该bean的实例对象,并将该bean的实例对象存储到singletonObiects中。
如果你觉得理解起来有点复杂,没事儿,接下来用更简单的话告诉你他们的作用。
获取Bean的核心方法:
public class DefaultSingletonBeanRegistry {
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 1. 一级缓存查找(完整的Bean)
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 2. 二级缓存查找(早期引用)
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 3. 三级缓存查找(工厂)
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 执行工厂方法,放入二级缓存
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName); // 关键:移除工厂
}
}
}
}
return singletonObject;
}
}- 一级缓存:存储完整的Bean
- 二级缓存:避免多重循环依赖,重复创建动态代理的情况
- 三级缓存:
- 缓存是函数接口:通过lambda 把方法传进去 (把Bean的实例和Bean名字传进去 (AOP创建))
- 不会立即调:(如果在实例化后立即调用的话:所有的aop 不管bean是否循环依赖都会在 实例化后创建proxy,正常Bean 其实spring还是希望遵循生命周期在初始化创建动态代理,只能循环依赖才创建)
- 会在 ABA(第二次getBean(A)才会去调用三级缓存(如果实现了AOP才会创建动态代理,如果没有实现依然返回的Bean的实例))
- 放入二级缓存(避免重复创建)
带着这些信息,我们进入下一个问题
三级缓存如何解决Spring的循环依赖
Spring中Bean的创建过程其实可以分成两步,第一步叫做实例化,第二步叫做初始化。
实例化的过程只需要调用构造函数把对象创建出来并给他分配内存空间,而初始化则是给对象的属性进行赋值。
而Spring之所以可以解决循环依赖就是因为对象的初始化是可以延后的,也就是说,当我创建一个Bean ServiceA的时候,会先把这个对象实例化出来,然后再初始化其中的serviceB属性。
以这个例子为例
@Servicepublic class ServiceA{
@Autowired
private ServiceB serviceB;
}
@Service
public class ServiceB{
@Autowired
private ServiceA serviceA;
}当一个对象只进行了实例化,但是还没有进行初始化时,我们称之为半成品对象。所以,所谓半成品对象,其实只是 bean 对象的一个空壳子,还没有进行属性注入和初始化。
当两个Bean在初始化过程中互相依赖的时候,如初始化A发现他依赖了B,继续去初始化B,发现他又依赖了A,那这时候怎么办呢?大致流程如下:
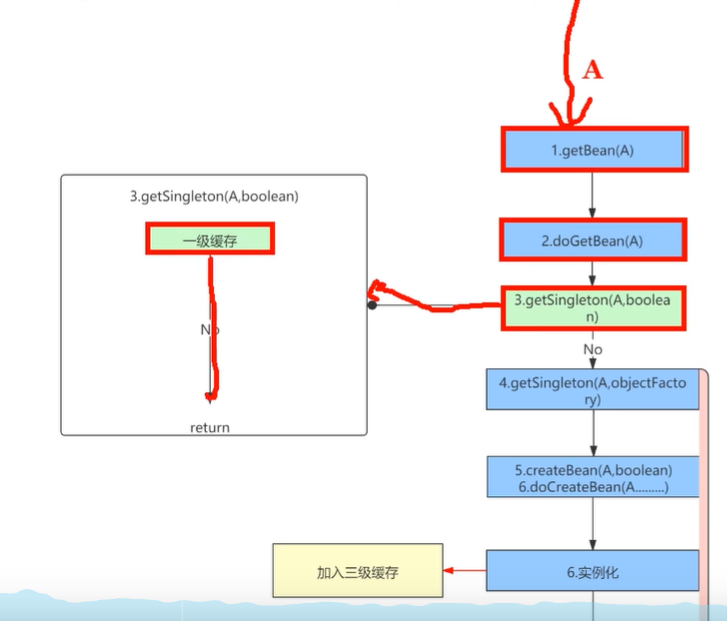
首先创建Bean A 它会调用getBean来进行创建 然后调doGetBean
这个时候,他会首先去一级缓存当中去帮我们找一下,看一下这个A它到底有没有创建好,如果已经创建好了就直接返回说明这个BeanA已经存在了,就没有必要再去创建了,首次肯定是没有的,那么就进行下面的创建。
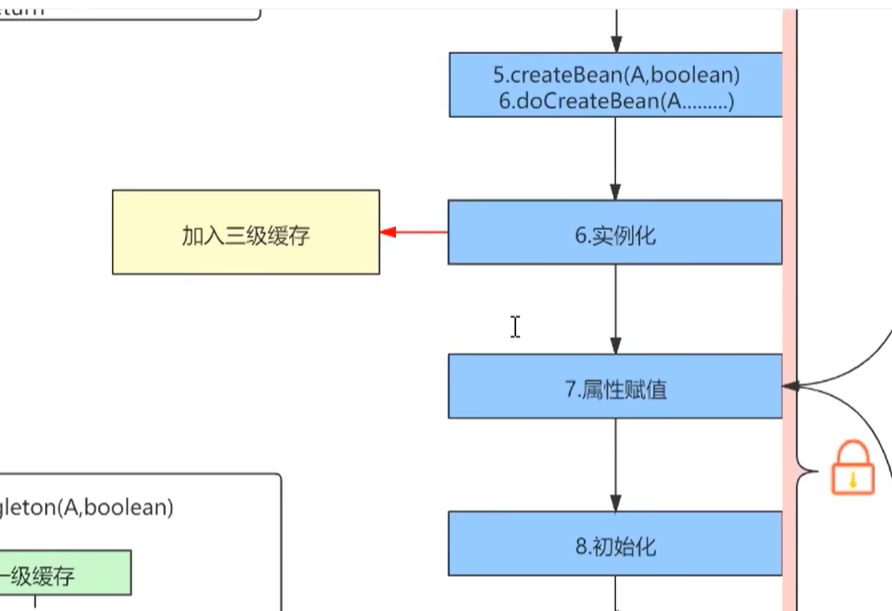
创建调用createBean开始进行创建,会经过bean的一个生命周期,首先会经过实例化,实例化之后加入到三级缓存当中,三级缓存呢它传的是一个函数接口,可以通过lambda的表达式把方法给传进去,它的作用就是帮我们把bean的实例跟bean的名字传到这个方法里面去了,后续可能会进行一个AOP的动态代理创建,或者直接返回原始对象
// 三级缓存中的工厂方法
singletonFactories.put("serviceA", () -> {
// 检查是否需要AOP代理
if (isBeanEligibleForAop("serviceA")) {
return createAopProxy(bean); // 返回代理对象
}
//// 这个lambda是工厂,调用时才创建实例
return getEarlyBeanReference(beanName, bean); // 返回原始对象
});但是它不会立即去调用方法创建动态代理或者实例对象,只是暂时保存而已。
然后属性赋值,发现BeanA依赖BeanB,那么这个时候呢去调用getBeanB。
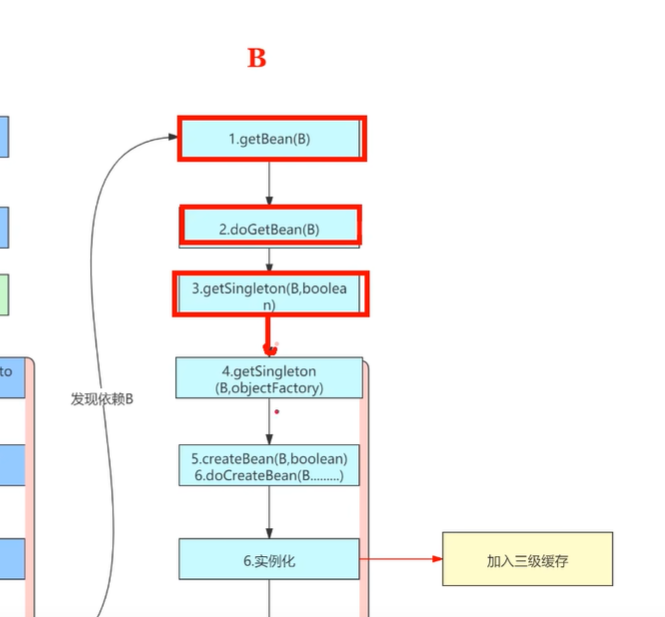
首先他会去这个通过这getSingleton,同样的去一级缓存当中找,首次创建肯定里面也是没有的,就会去创建Bean B了,创建BeanB呢 ,同样的实例化,同样的也加入到三级缓存,也就是说三级缓存这个函数接口把它保存了。
然后进行属性赋值,属性赋值时又发现你呢依赖BeanA。
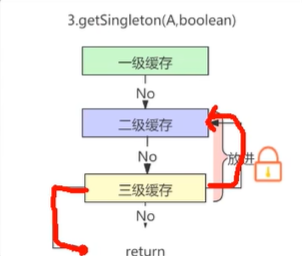
那么这个时候就去getBean(A)了,getBean(A)的时候呢,会先从一级缓存中当中拿。
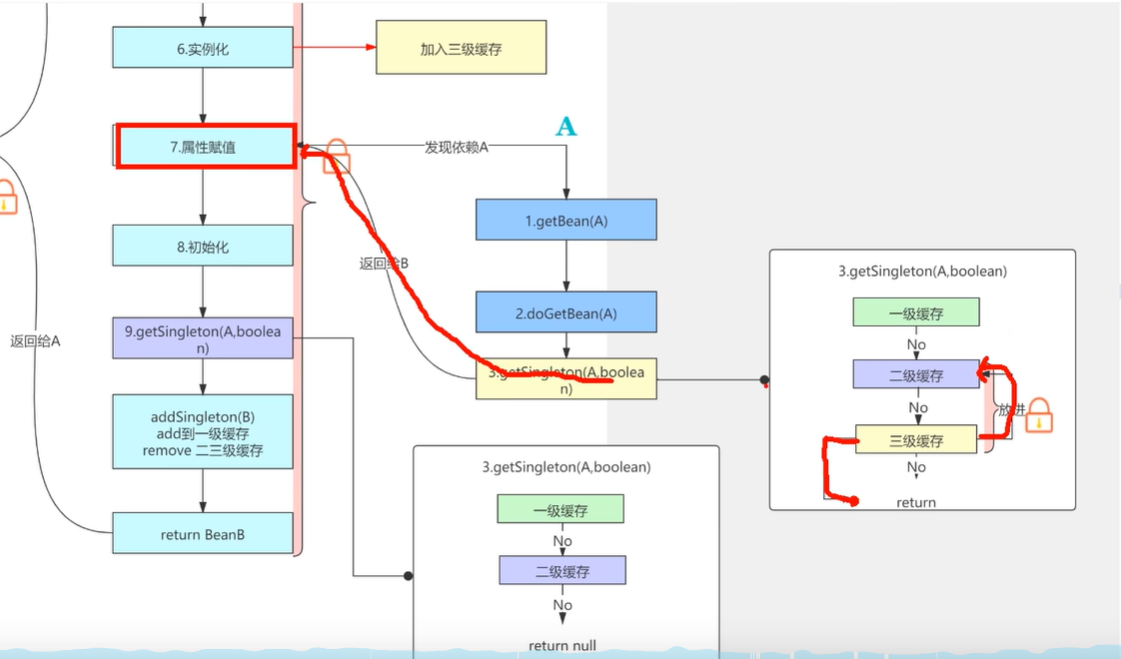
一级缓存它存的是我们最终创建完的一个Bean,也就是说整个流程完了之后,它才会添加到一级缓存,所以说现在这个阶段一级缓存里是肯定是没有的
我们这个Bean还没有创建完成,那么二级缓存也是没有的,因为在这个过程当中,我们还没有看到任何二级缓存的存储。
那么三级缓存有没有?
有的,兄弟,有的
这个时候呢,他就会去调用三级缓存,也就是说调用三级缓存的时候
会在"A-B-A"的时候调用
我创建BeanA的时候发现依赖BeanB,创建BeanB的时候,又发现你依赖BeanA,这个时候获取BeanA的第二次,才会去调用三级缓存。
也就是这个时候如果你的BeanA使用了AOP(比如事务)的话。它就会把你放进到动态代理的方法中,创建动态代理。
然后会保存在二级缓存当中,也就是三级缓存它调用完之后,他会给你放到二级缓存当中
如果没有使用AOP呢,依然返回存在三级缓存中的这个bean的实例,把这个返回的对象放到二级缓存当中。
为什么这里要放到二级缓存呢?
一为的就是避免了重复创建代理对象,如果现在是A依赖B A又依赖C ,A它被依赖了两次可能就会创建两次动态代理,所以我们肯定又要用一个缓存来进行存储,也就是二级缓存。
那么这个二级缓存呢说白了,避免重复创建动态代理,只要有一个了就会查询已经存在的对象,而不是再去创建,避免多重循环依赖的情况重复去创建这个动态代理。
于是BeanA的动态代理就放到二级缓存去了
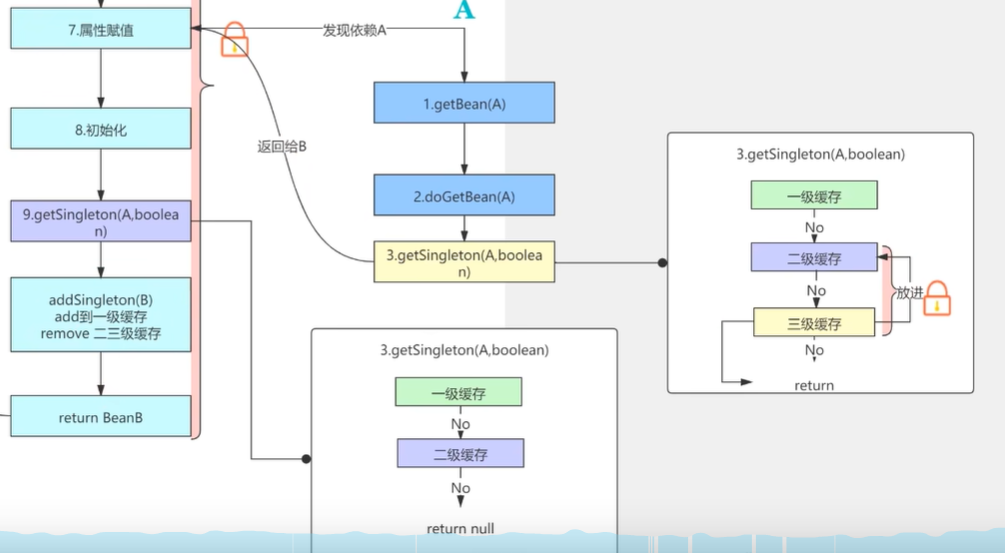
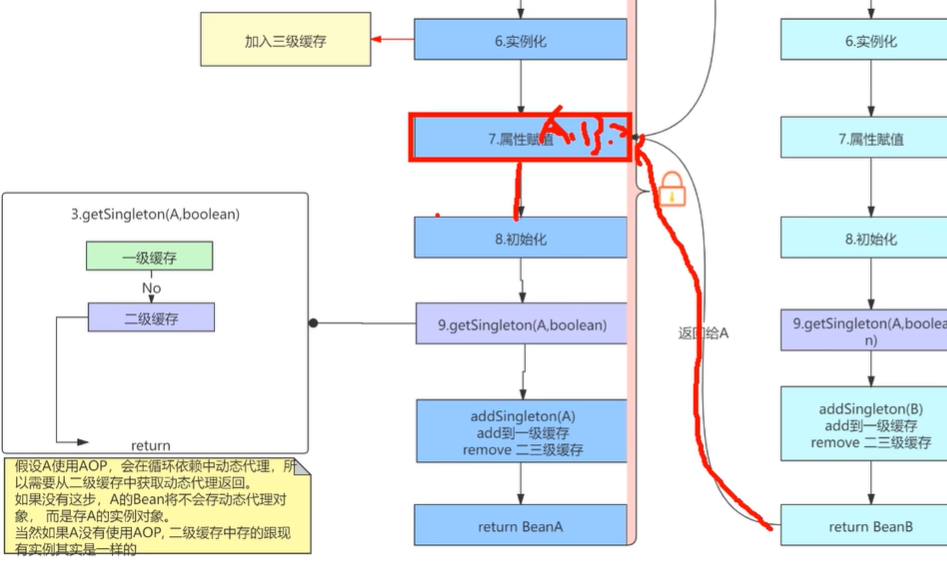
创建完的这个动态代理BeanA返回给BeanB进行属性赋值(三级缓存调用方法,从二级缓存获取),那赋完值之后呢,BeanB的循环依赖它就相当于有了出口了,就不需要再闭环的一直循环下去了,BeanB继续执行他的正常的一个生命周期,把自己存入到一级缓存当中,然后移除掉二级缓存,三级缓存,然后returnB。
那么这个时候呢BeanA里面的BeanB就完成属性赋值了,然后BeanA又进行正常的一个初始化阶段了,最后returnA
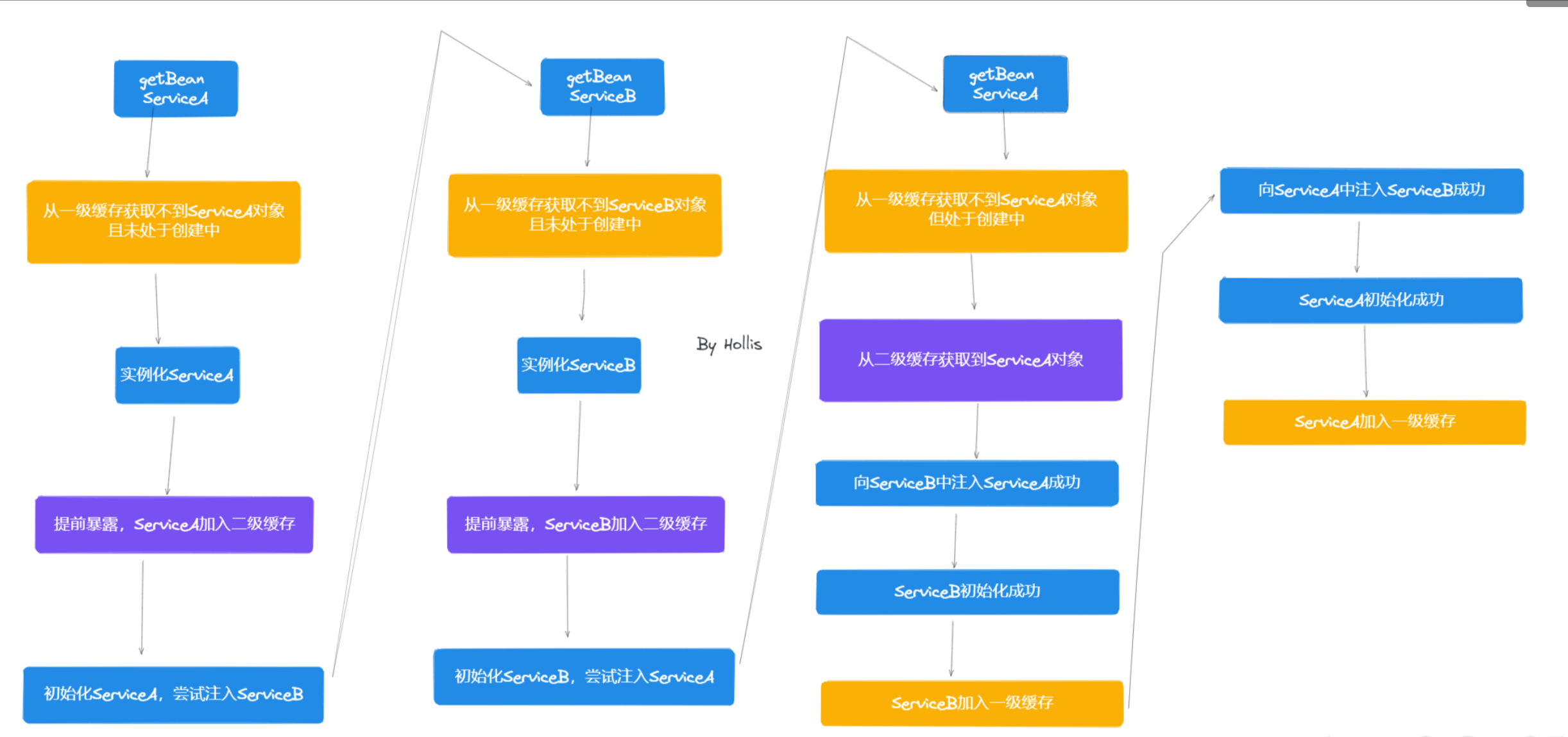
Spring解决循环依赖一定需要三级缓存嘛
其实,只用二级缓存,也是可以解决循环依赖的问题的,如下图,没有三级缓存,只有二级缓存的话,也是可以解决循环依赖的。
那么,为什么还需要引入三级缓存呢?我们看下两个过程的区别主要是什么呢?
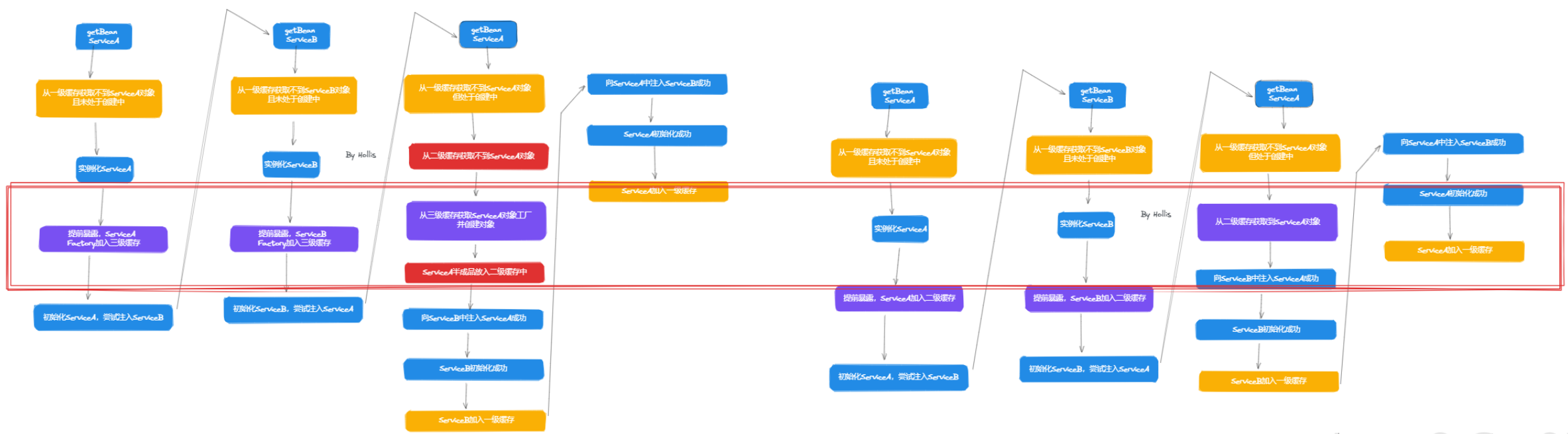
如果使用三级缓存,在实例化之后,初始化之前,向三级缓存中保存的是ObjectFactory。而如果使用二级缓存,那么在这个步骤中保存的就是具体的Object。这就是之前说的
singletonFactories是三级缓存,存储的是单例bean的创建工厂。
earlySingletonObjects是二级缓存,存储的是尚未完全创建好的单例bean对象。
这里如果我们只用二级缓存,对于普通对象的循环依赖问题是都可以正常解决的,但是如果是代理对象的话就麻烦多了,并且AOP又是Spring中很重要的一个特性,代理又不能忽略。
我们都知道,我们是可以在一个ServiceA中注入另外一个ServiceB的代理对象的,那么在解决循环依赖过程中如果需要注入ServiceB的代理对象,就需要把ServiceB的代理对象创建出来,但是这时候还只是ServiceB的实例化阶段,代理对象的创建要等到初始化之后,在后置处理的postProcessAfterlnitialization方法中对初始化后的Bean完成AOP代理的。
@Service
@Transactional // 需要AOP代理
public class ServiceB {
@Autowired
private ServiceA serviceA; // 循环依赖!
// 问题:ServiceA需要注入ServiceB的代理对象,
// 但ServiceB的代理正常应该在初始化后才创建!
}
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB; // 需要B的代理对象
}正常时序:实例化 → 属性赋值 → 初始化 → 创建AOP代理
循环依赖需求:实例化 → 立即需要代理对象 → 但代理还没创建!那怎么办好呢?Spring想到了一个好的办法,那就是使用三级缓存,并且在这个三级缓存中,并没有存入一个实例化的对象,而是存入了一个匿名类ObjectFactory(其实本质是一个函数式接口()->getEarlyBeanReference(beanName,mbd,bean)),具体代码如下:
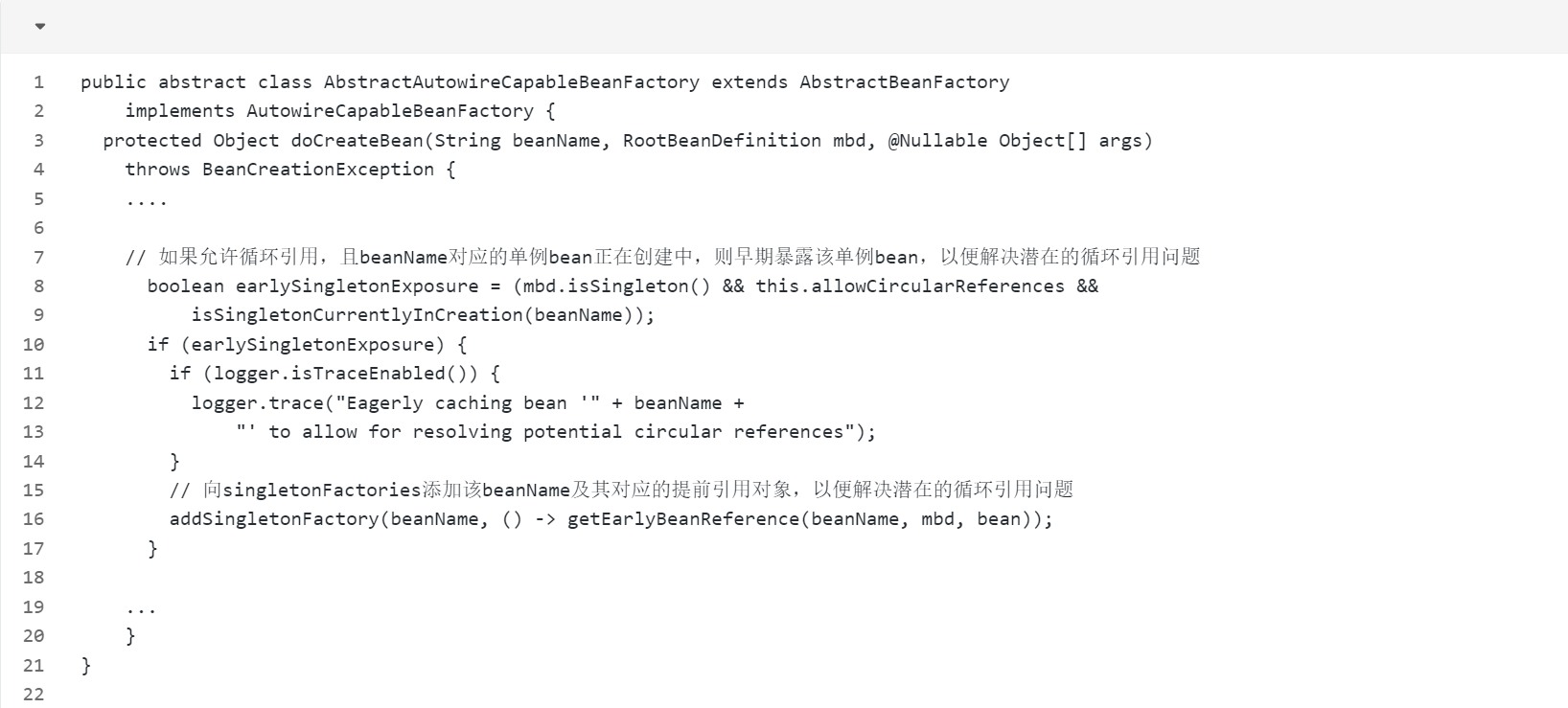
那我们可不可以提前创建AOP代理对象放到二级缓存中呢,这样是不是就不需要三级缓存了?
不管有没有循环依赖,都提前把代理对象创建出来,并将代理对象缓存起来,出现循环依赖时,其他对象直接就可以取到代理对象并注入
方案看上去比较简单,只需要二级缓存就可以了。但是他也意味着,Spring需要在所有的bean的创建过程中就要先生成代理对象再初始化;那么这就和spring的aop的设计原则(前文提到的:在Spring的设计中,为了解耦Bean的初始化和代理,是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理的)是相悖的。
而Spring为了不破坏AOP的代理设计原则,则引入第三级缓存,在三级缓存中保存对象工厂,因为通过对象工厂我们可以在想要创建对象的时候直接获取对象。有了它,在后续发生循环依赖时,如果依赖的Bean被AOP代理那么通过这个工厂获取到的就是代理后的对象,如果没有被AOP代理,那么这个工厂获取到的就是实例化的真实对象。
Spring解决循环依赖的限制
为什么只支持单例
Spring循环依赖的解决方案主要是通过对象的提前暴露来实现的。当一个对象在创建过程中需要引用到另一个正在创建的对象时,Spring会先提前暴露一个尚未完全初始化的对象实例,以解决循环依赖的问题。这个尚未完全初始化的对象实例就是半成品对象。
在 Sprina 容器中,单例对象的创建和初始化只会发生一次,并且在容器启动时就完成了。这意味着,在容器运行期间,单例对象的依赖关系不会发生变化。因此,可以通过提前暴露半成品对象的方式来解决循环依赖的问题。
相比之下,原型对象的创建和初始化可以发生多次,并且可能在容器运行期间动态地发生变化。因此,对于原型对象,提前暴露半成品对象并不能解决循环依赖的问题,因为在后续的创建过程中,可能会涉及到不同的原型对象实例,无法像单例对象那样缓存并复用半成品对象。
因此,Spring只支持通过单例对象的提前暴露来解决循环依赖问题。
为什么不支持构造函数注入
Spring无法解决构造函数的循环依赖,是因为在对象实例化过程中,构造函数是最先被调用的,而此时对象还未完成实例化,无法注入一个尚未完全创建的对象,因此Spring容器无法在构造函数注入中实现循环依赖的解决。
@Service
public class ServiceA {
private final ServiceB serviceB;
@Autowired
public ServiceA(ServiceB serviceB) { // 构造时就需要B!
this.serviceB = serviceB;
}
}
@Service
public class ServiceB {
private final ServiceA serviceA;
@Autowired
public ServiceB(ServiceA serviceA) { // 构造时就需要A!
this.serviceA = serviceA;
}
}构造器注入要求在实例化阶段就完成依赖注入,没有缓冲时间。
在属性注入中,Spring容器可以通过先创建一个空对象或者提前暴露一个半成品对象来解决循环依赖的问题。但在构造函数注入中,对象的实例化是在构造函数中完成的,这样就无法使用类似的方式解决循环依赖问题了。
如何解决构造器注入的循环依赖
1、重新设计,彻底消除循环依赖
循环依赖,一般都是设计不合理导致的,可以从根本上做一些重构,来彻底解决。
2、改成非构造器注
可以改成setter注入或者字段注入。
3、使用@Lazy解决
@Lazy 是Spring框架中的一个注解,用于延迟一个bean的初始化,直到它第一次被使用。在默认情况下Spring容器会在启动时创建并初始化所有的单例bean。这意味着,即使某个bean直到很晚才被使用,或者可能根本不被使用,它也会在应用启动时被创建。@Lazy 注解就是用来改变这种行为的。
也就是说,当我们使用 @Lazy 注解时,Spring容器会在需要该bean的时候才创建它,而不是在启动时。这意味着如果两个bean互相依赖,可以通过延迟其中一个bean的初始化来打破依赖循环。
假设我们有两个类 ClassA 和 ClassB,它们之间存在循环依赖。我们可以使用 @Lazy 来解决这个问题
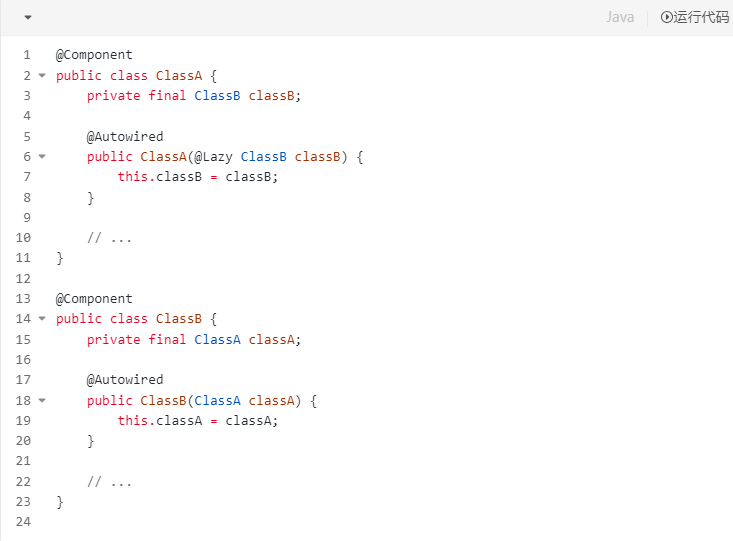
在这个例子中,ClassA 的构造器依赖 ClassB,但我们使用了 @Lazy 注解来标记这个依赖。这意味着 ClassB 的实例会在首次被实际使用时才创建,而不是在创建 ClassA 的实例时。这样,Spring容器可以先创建 ClassA 的实例(此时不需要立即创建 ClassB),然后创建 ClassB 的实例,最后解决 ClassA 对 ClassB 的依赖。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









