







在解决了线性求解问题之后,我们开始挑战更复杂的问题,开始研究非线性划分的问题,类似求解异或问题这样,而解决这类问题,我们先要学习一个概念,就是梯度下降(Gradient Descent),这个方法是解决机器学习领域最常采用的方法之一。
梯度
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T,简称grad f(x,y)或者▽f(x,y)。对于在点(x0,y0)的具体梯度向量就是(∂f/∂x0, ∂f/∂y0)T.或者▽f(x0,y0),如果是3个参数的向量梯度,就是(∂f/∂x, ∂f/∂y,∂f/∂z)T,以此类推。
那么这个梯度向量求出来有什么意义呢?他的意义从几何意义上讲,就是函数变化增加最快的地方。具体来说,对于函数f(x,y),在点(x0,y0),沿着梯度向量的方向就是(∂f/∂x0, ∂f/∂y0)T的方向是f(x,y)增加最快的地方。或者说,沿着梯度向量的方向,更加容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是 -(∂f/∂x0, ∂f/∂y0)T的方向,梯度减少最快,也就是更加容易找到函数的最小值。
先看一个平面函数:y=(x-2)^2
图形为:
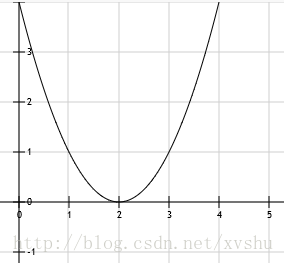
(x-2)^2 是上图 求导:y=2(x-2) = 2x-4 ,在图中低点 导数求值为0
导数描述y的变化,导数为负,y在变小,导数为正,y在变大,求得函数最小值,要找梯度最小的地方,就是定点
重申:导数为负数,Y在减少,咬着导数反方向,就是要增加X的值,那么Y肯定也是减少,所以最终求得最小值。按照这个去理解下边的概念就容易些。
梯度下降与梯度上升
在机器学习算法中,在最小化损失函数时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数,和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。
梯度下降法和梯度上升法是可以互相转化的。比如我们需要求解损失函数f(θ)的最小值,这时我们需要用梯度下降法来迭代求解。但是实际上,我们可以反过来求解损失函数 -f(θ)的最大值,这时梯度上升法就派上用场了。
下面来详细总结下梯度下降法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









