



近来transformer在cv领域十分火热,但是将其用于low-level方面的文章并不多,本文发表于ICCV2021,在此对文章做一个翻译与解读,具体细节内容请看文章,如有错误,请指正!
文章:pdf
代码:github
引用:Zhang, Zhaoyang, et al. “STAR: A Structure-Aware Lightweight Transformer for Real-Time Image Enhancement.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
文章目录
Abstract
low-level任务部署在端侧智能设备上十分困难,因为要用有限的计算花销来处理通常是高质量的图像。不像之前的深层CNN和大型Transformer,本文作者提出了一个structure-aware lightweight Transformer(STAR),用于实时图像质量提升。
STAR可以捕捉分块图像之间的长依赖关系(long-range dependencies),这样就很自然而然地捕捉了一张图像不同区域中的结构关系(structural relationships)。
STAR可以很轻易地适用于不同底层视觉任务,例如光照提升,自动白平衡,图像修饰。并且其模型的复杂度很低,效果也比SoTA好(在MIT-Adobe FiveK数据集中相比DCE-Net提升1.8dB PSNR,仅用其25%的参数量以及13%的浮点计算量)。
1. Introduction
近年来用于提升图像和视频质量的深度学习算法在部署上主要有两个挑战,第一是必须要用有限的计算资源处理高分辨率图像。第二是需要结合输入低质图像的结构信息和全局信息来输出稳定的高质量图像。
为了解决这两个问题,通常使用的方式可以分为1.deep CNN:为了保持其高频细节信息,空间分辨率通常不能改变,因此计算量和内存消耗巨大。2.估计一系列的全局调整函数(estimate one set of global adjustment function),但在缺少处理复杂真实场景的灵活性。3.直接利用分割网络将图片分成不同区域并且分别处理。
STAR基于transformer模块,主要包含MSA和FFN,避免了卷积模块的堆叠,能更有效的提取结构信息。在STAR中图像块被embedding成一个个token,与直接计算像素之间的依赖不同,STAR直接学习token之间的依赖关系。也可以隐式地学习语义结构,从而比CNN提供更多的有意义的语义结果。
作者提出了一个特殊设计的双路long short Range Transformer确保STAR能够集中在捕获图像全局上下文信息(global contexts)并且减少计算量。
3. Structure-Aware Transformer Network
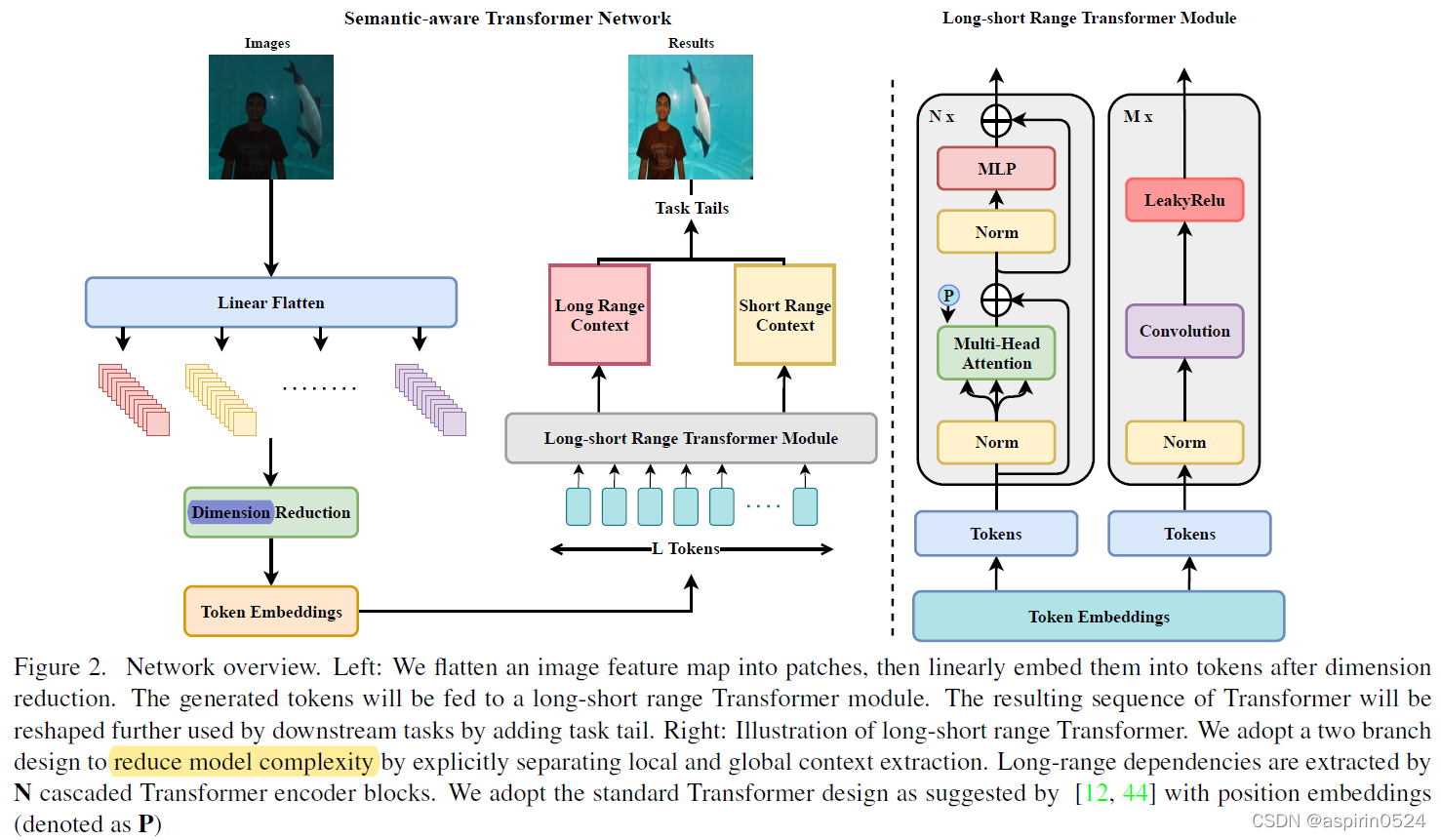
STAR整体结构如图所示,首先将图
I
∈
R
H
×
W
×
C
I
\mathbf{I}\in\mathbb{R}^{H\times W\times C_I}
I∈RH×W×CIembedding为token序列
I
T
∈
R
L
×
C
T
\mathbf{I}_T\in \mathbb{R}^{L\times C_T}
IT∈RL×CT输进long-short range Transformer模块,,输出两structural maps
S
l
,
S
s
\mathbf{S}_l,\mathbf{S}_s
Sl,Ss,可进一步用于后续图像增强任务等。
3.1. Tokenization
最常见的将图像转换成token序列的方式一个就是如IPT里将图像展平成图像块(i.e., T ∈ R ( H P × W P ) ( P 2 × C I ) \mathbf{T}\in \mathbb{R}^{(\frac{H}{P}\times \frac{W}{P})(P^2\times C_I)} T∈R(PH×PW)(P2×CI)),这样会导致大量的内存消耗,并且输入的token向量维度 t i ∈ R P 2 × C I t_i\in \mathbb{R}^{P^2\times C_I} ti∈RP2×CI太大,需要大量的参数来训练(IPT,33M)。另一种方式是从CNN的feature map中获取输入token,这种情况下在经过CNN对空间分辨率下采样后patch size可以为1×1。
为减少计算量,达到实时图像增强效果,如上图,作者先将全尺寸图片展平为图像块序列,然后再对图像块做维度缩减,之后再通过可学习的线性embedding层对每个图像块提取token。

本文比较了三种tokenization的方法,如图所示,第一种Linear Head,vit和ipt中使用的,将图片分成patch后再通过线性embedding,计算量太大。第二种Conv Head,通过卷积层和下采样将空间分辨率降低。token序列就是将低分辨率的feature map展开。第三种Mean Head通过Adaptive Average Pooling来降低空间分辨率,极大地减少了产生token的复杂度和计算量。
3.2. Long-short Range Transformer Module
Long-short Range Transformer模块有两条支路,一条卷积一条Transformer,卷积处理各图像块short range之间的依赖关系,Transformer处理各图像块long range之间的关系。作者将token embedding分成两部分分别输入卷积和transformer支路(但是公布的代码好像两边都是全输进去的),具体结构减图一以及文章和公布的代码。
实验与结论部分略
具体请参考文章内容

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









