







k-means算法进行员工发展潜力分组
背景
数据集 https://datahack.analyticsvidhya.com/contest/wns-analytics-hackathon-2018-1/
您的客户是一家大型跨国公司,在整个组织中有9个广泛的垂直行业。客户面临的问题之一是确定合适的培训方向(仅适用于经理职位及以下职位)并及时做好准备。目前该过程如下:
1.收集员工信息
2.将员工分组
3.分析各组特征,结合实际情况进行培训课制定
本篇将进行员工分组及外行肤浅式的特征分析两步
数据预处理
1.删除无关信息:培训预算分配应本着公平公正的原则,与性别,部门,区域无关(虽然肯定是有关的,但也是在分完组后后进行调整)
2.探索缺失值:未发现缺失值
3.探索异常值:未发现异常值
4.重编码变量
5.标准化
df = pd.read_csv(r'C:\Users\Administrator\Downloads\train_LZdllcl.csv')
OneHot_df = pd.get_dummies(data=df,columns=['education', 'recruitment_channel'])# OneHot编码
OneHot_df = OneHot_df.iloc[:, 1:] # 删除员工id列
std_df = (OneHot_df - OneHot_df.mean(axis=0))/(OneHot_df.std(axis=0)) # 标准化
k-means分组
对于K-Means方法,k的取值是一个难点,因为是无监督的聚类分析问题,所以不寻在绝对正确的值,需要进行研究试探。这里采用计算SSE的方法,尝试找到最好的K数值。
def distEclud(vecA, vecB):
"""
计算两个向量的欧式距离的平方,并返回
"""
return np.sum(np.power(vecA - vecB, 2))
def test_Kmeans_nclusters(data_train):
"""
计算不同的k值时,SSE的大小变化
"""
data_train = data_train.values
nums=range(2,10)
SSE = []
for num in nums:
sse = 0
kmodel = KMeans(n_clusters=num, n_jobs=4)
kmodel.fit(data_train)
# 簇中心
cluster_ceter_list = kmodel.cluster_centers_
# 个样本属于的簇序号列表
cluster_list = kmodel.labels_.tolist()
for index in range(len(data_train)):
cluster_num = cluster_list[index]
sse += distEclud(data_train[index, :], cluster_ceter_list[cluster_num])
print("簇数是",num , "时; SSE是", sse)
SSE.append(sse)
return nums, SSE
nums, SSE = test_Kmeans_nclusters(std_df)
'''
簇数是 2 时; SSE是 422388.18314035854
簇数是 3 时; SSE是 364360.23507114867
簇数是 4 时; SSE是 317459.9231693121
簇数是 5 时; SSE是 278501.9665155248
簇数是 6 时; SSE是 251983.83008386526
簇数是 7 时; SSE是 227596.44245812204
簇数是 8 时; SSE是 210731.41327592355
簇数是 9 时; SSE是 198322.66405387426
'''
#画图,通过观察SSE与k的取值尝试找出合适的k值
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['font.size'] = 12.0
plt.rcParams['axes.unicode_minus'] = False
# 使用ggplot的绘图风格
plt.style.use('ggplot')
## 绘图观测SSE与簇个数的关系
fig=plt.figure(figsize=(10, 8))
ax=fig.add_subplot(1,1,1)
ax.plot(nums,SSE,marker="+")
ax.set_xlabel("n_clusters", fontsize=18)
ax.set_ylabel("SSE", fontsize=18)
fig.suptitle("KMeans", fontsize=20)
plt.show()
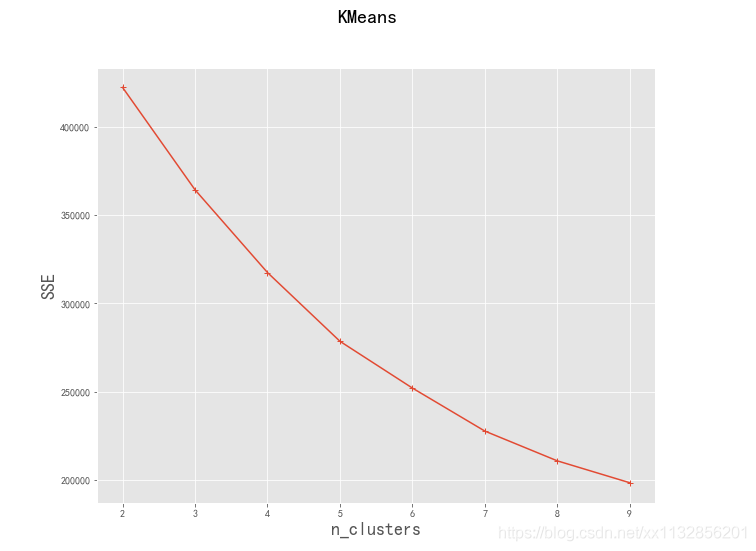
无明显肘点,考虑到有9个属性,故分为4,5, 6类三种情况分析
kmodel = KMeans(n_clusters=4, n_jobs=4) #分别取n_clusters=4 5 6
kmodel.fit(std_df)
r1 = pd.Series(kmodel.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) #找出聚类中心
# 所有簇中心坐标值中最大值和最小值
max = r2.values.max()
min = r2.values.min()
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(std_df.columns) + [u'类别数目'] #重命名表头
# 绘图
fig=plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, polar=True)
center_num = r.values
feature = ["学历水平", "上一次培训时间", "年龄", "上一年员工评分", "企龄", "KPI得分", "上一年得奖", "当前培训评估得分", "将晋升"]
N =len(feature)
for i, v in enumerate(center_num):
# 设置雷达图的角度,用于平分切开一个圆面
angles=np.linspace(0, 2*np.pi, N, endpoint=False)
# 为了使雷达图一圈封闭起来,需要下面的步骤
center = np.concatenate((v[:-1],[v[0]]))
angles=np.concatenate((angles,[angles[0]]))
# 绘制折线图
ax.plot(angles, center, 'o-', linewidth=2, label = "第%d簇人群,%d人"% (i+1,v[-1]))
# 填充颜色
ax.fill(angles, center, alpha=0.25)
# 添加每个特征的标签
ax.set_thetagrids(angles * 180/np.pi, feature, fontsize=15)
# 设置雷达图的范围
ax.set_ylim(min-0.1, max+0.1)
# 添加标题
plt.title('群特征分析图', fontsize=20)
# 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True)
# 显示图形
plt.show()
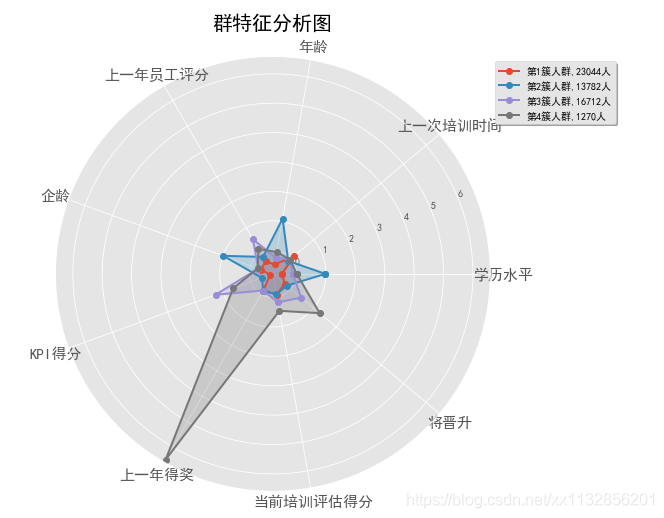
分4组时各组都有突出点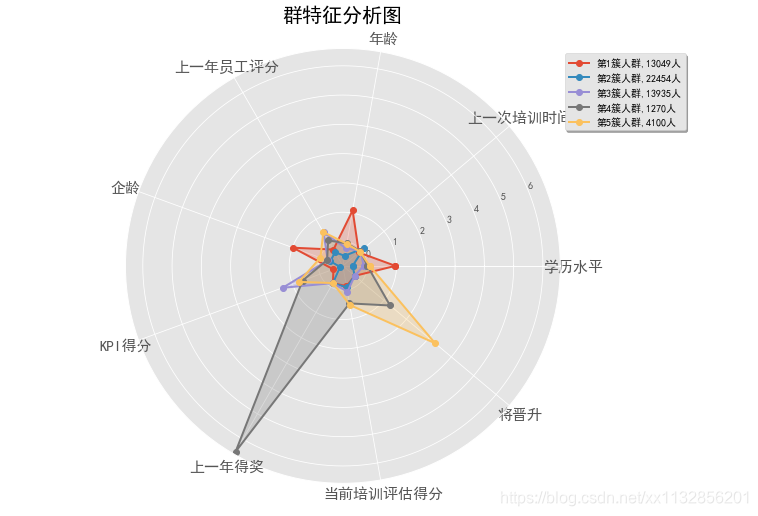
分5组时各组都有突出点
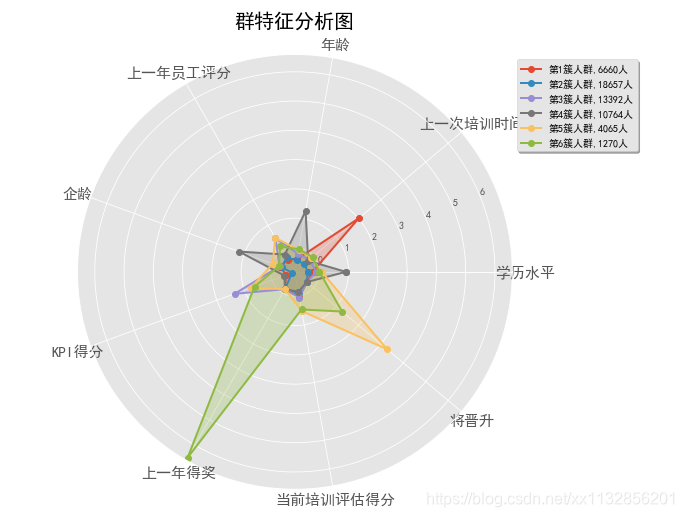
分6组时第二簇被其他簇包含了,不适合
分4 5组的分组里,’上一次培训时间‘特征都不明显,故相当于少了一个属性,故最终选取分组多的,分5组
外行肤浅式的特征分析
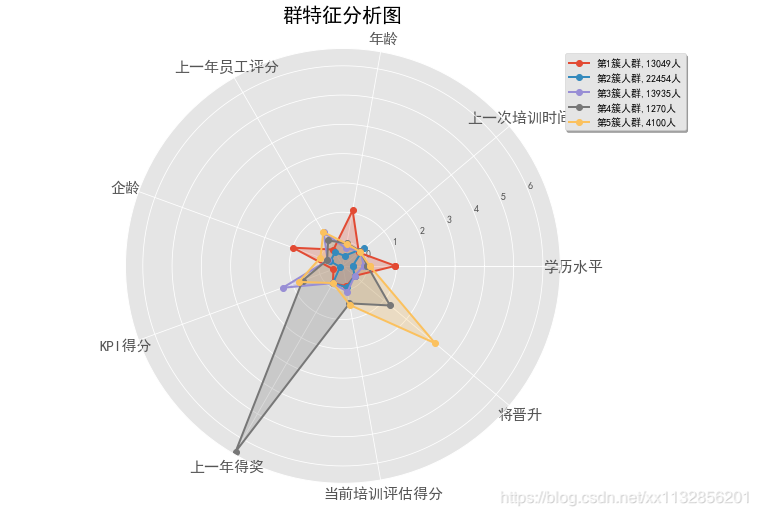
第1簇:企龄、年龄、学历都高,大多为管理层,这类人员应该注重通用的工商管理学的培训
第2簇:学历低,KPI低,年龄小,多为入职不久的新人,且占比最多,这类人员应注重专业技能、基本素质、公司忠诚度的培训
第3簇:KPI最高,却难晋升,说明可能是工作之外的技能欠缺,应该注重非专业技能,如人际、职场等培训
第4簇:最近表现突出,企龄较短,将晋升,多为公司准备重用的新人,应该注重综合技能(技术+管理)的培训
第5簇:KPI较高,晋升可能最大,可能公司看重这类人其他(未在提供数据里的)能力,这类人的培训方向需再做调查确定…
保存标记
df = pd.read_csv(r'C:\Users\Administrator\Downloads\train_LZdllcl.csv')
df['label'] = pd.Series(kmodel.labels_)
df.to_excel('员工培训分类.xlsx')














 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









