







######################
######################
相似度算法介绍
相似度算法主要任务是衡量对象之间的相似程度,是信息检索、推荐系统、数据挖掘等的一个基础性计算。下面重点介绍几种比较常用的相似度算法。
通常假设对象X和Y都具有N维的特征,即
X=(x_1,x_2,…x_n) Y=(y_1,y_2,…y_n)
在推荐场景下,假设用户物品矩阵为:

item1=(0,1,1) item2=(1,0,1)
1.欧氏距离
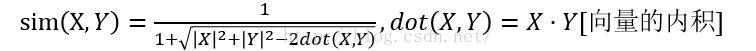
欧式距离相似度算法需要保证各个维度指标在相同的刻度级别,比如对身高、体重两个单位不同的指标使用欧氏距离可能使结果失效。
并且,欧氏距离适合比较稠密的矩阵。
增量计算说明:
2.余弦相似
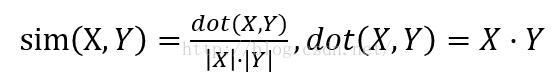
数据稀疏性强,就考虑用夹角余弦相似度算法
缺点:余弦相似度受到向量的平移影响,上式如果将x平移到x+1,余弦值就会改变【即当各个对象的评分指标不一致的时候,余弦相似度不能稳定刻画其相似,这种情况下使用皮尔逊相似度会更好】
3. 皮尔逊相似度
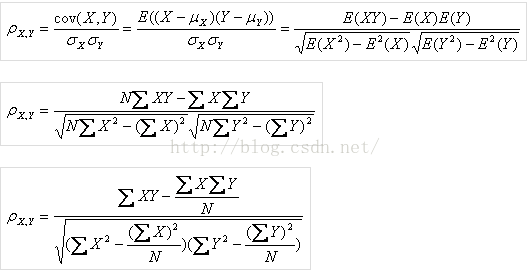
计算相对比较复杂,只能应用于带评分的场景,对不同刻度的评分(如一个对象评分集中在4分,另一个集中在3分)衡量相似度时具有良好的效果。在计算相似度时采用了这种方法,近似的可以把最后一个带N的去掉(默认N很大,作为分母几乎趋近于0)。出现一次的计为1,出现多次的统一计为2.
4. 简单粗暴的N/M
应用于元素值为1或者0的向量。
当计算与A相似对象的相似值的时候, 如A与X,Y之间的相似,则计算公式为
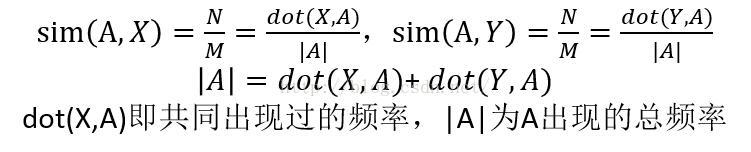
计算结果不是特别准,适用于数据量非常庞大,对若干对象的近似估计
5. IUF相似度(基于用户活跃度倒数的参数)
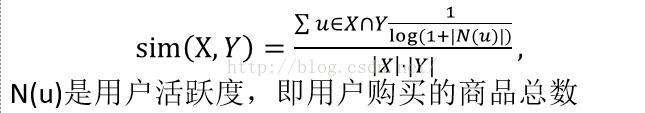
对比前面的余弦相似,余弦相似也可以表示为
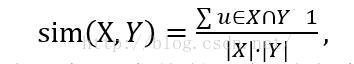
这里即为对每一个值的累加时考虑了用户的因素。
效果:能推出更多的商品来,提高召回率
相似度算法效果测试


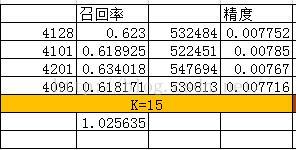
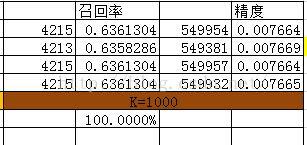
结论
当推荐坑位商品曝光数小于15时,如果追求更多的商品曝光建议采用IUF相似度,如果追求精确度建议采用N/M+, 当曝光商品足够多时,相似度算法已经成为传说~~恩 对,只是传说而已。 然而在博主实际项目使用中发现,可以根据相似度矩阵的稀疏程度,对K取阈值,多种相似度算法协同使用~~~在此基础之上后 续可以考虑增加商业因子进行二次排序~~空间很大,看你能触摸到多少~推荐系统的应用案例剖析
在《程序员》杂志12期A中,我们介绍了推荐系统的数学原理和应用案例,本章将继续讲述推荐系统的应用案例。为了说明推荐系统的详细实施方案,本章首先详细介绍了一个音乐系统推荐的实施案例,之后为了让读者清晰大型推荐系统的原理,简要介绍一个淘宝周边兴趣点推荐的技术方案。
音乐推荐
音乐推荐系统是一个很好的说明说明推荐系统工作原理的例子。
1. 音乐推荐特点
- 物品空间大。物品数很多,物品空间很大,这主要是相对于书和电影而言。
- 消费每首歌的代价很小。对在线音乐来说,音乐都是免费的,不需要付费。
- 物品种类丰富。音乐种类丰富,有很多的流派。
- 听一首歌耗时很少。听一首音乐的时间成本很低,不太浪费用户的时间,而且用户大都把音乐作为背景声音,同时进行其他工作。
- 物品重用率很高。每首歌用户都会听很多遍,这和其他物品不同,比如用户不会反复看一个电影,不会反复买一本书。
- 用户充满激情。用户很有激情,一个用户会听很多首歌。
- 上下文相关。用户的口味很受当时上下文的影响,这里的上下文主要包括用户当时的心情(比如沮丧的时候喜欢听励志的歌曲)和所处情境(比如睡觉前喜欢听轻音乐)。
- 次序很重要。用户听音乐一般是按照一定的次序一首一首地听。
- 很多播放列表资源。很多用户都会创建很多个人播放列表。
- 不需要用户全神贯注。音乐不需要用户全神贯注地听,很多用户将音乐作为背景声音。
- 高度社会化。用户听音乐的行为具有很强的社会化特性,比如我们会和好友分享自己喜欢的音乐。
上面这些特点决定了音乐是一种非常适合用来推荐的物品。
2. 音乐推荐的实现方案
目前大部分做推荐的应用推荐逻辑应该都是多种逻辑并行。编辑推荐和用户推荐的歌曲一般会有专门的版块展示。
个性化推荐理论上来讲都是通过算法直接从音乐库里面由程序产出的。
- 冷启动(用户第一次使用)的时候基于热度的推荐会比较多,推荐流行热点音乐总是不会错的。
- 在用户使用一段时间,用户行为达到一定样本量以后,程序开始通过内容和社交关系逻辑产出内容,并且与热门内容按照一定比例推送给用户。
- 程序推荐和编辑人员人工推荐结合。
- 各个用户好友的歌单的交互。
用户所有的行为(包括下载/喜欢、评论、播放完成度、播放次数等)都会以不同的权重呈现在后续的推荐逻辑中。比如,一种权重的设置方法为:
下载+播放 > 喜欢+播放 > 搜索+播放 > 播放 > 下载 > 喜欢
至于准确不准确,合不合口味这个事情,与推荐算法的关系其实是不大的。做内容推荐的关键是内容质量是否过关。也就是音乐库里面对不同歌曲,不同歌手的音乐基因标记的是否正确,是否够专业,Jing.FM可能是近两年相对专业一些的个性化电台。
3. 关于实现方案的分析
先从相似度的问题说起。大多数用户一开始会先从自己熟悉的歌曲开始,然后一般都会给出非常相关的推荐,比如你听周杰伦的任何歌曲,他的其他热门歌曲肯定都会非常相关,比如周杰伦的《东风破》,周杰伦的《游园会》,周杰伦的《七里香》,也不失为一个好的推荐。但是你会发现全都是周杰伦,单调死了。全是周杰伦的理由很简单,因为很多用户都连着听下去呀,听完一首周杰伦到下一首周杰伦,听完这个专辑听下个专辑。如果你往后再翻翻,估计还能找到别歌手的歌曲,但是请记着:你的屏幕就这么大,坑就这么多,再好的推荐不能在靠前的位置被用户看到和消费到终归也还是没用。现在我们来尝试解决这个问题,我们先来做个简单的多样化过滤,我们限制来自同一个歌手的推荐数量,这样后面更多歌手的歌去被推上来了。
现在出现了一个新的问题,陈奕迅这时候发新专辑了,用户一下子蜂拥去听他的新专辑了,包括周杰伦的拥趸们也跑去观望了一下,这样的情况持续了一个多月,这下好了,用户看到的推荐里面现在几乎都能看到陈奕迅的这些歌了,尽管他这的歌跟周杰伦的歌原本不至于这么相关。而且由于这个效应,更多的人从推荐里面点进去了听陈奕迅的这些歌,造成了一个恶性循环,使得你的基于相似度的算法以为他们真的相关,这时候其他真正相关的优质推荐却被挤压到后面了。我们来尝试解决这个问题,最简单的莫过于是计算相似度的时候过滤掉“过于”热门的歌曲了,把这些歌曲推后吧,感觉问题应该也能解决了。
这种结合就是基于热度的推荐和用户行为推荐的结合。
现在一波未平一波又起,假设现在一个非常优秀的新歌手,唱的歌也好有周杰伦的早年的风采,反正就是非常相关,周杰伦的歌迷肯定会喜欢那种。这位新歌手刚出道,宣传力度不大,也只有少数几个地方能听到他的歌曲,只有被小数的几个周杰伦迷给发掘出来了,现在问题来了,我们该如何使得这个歌手被发掘出来呢?这个基本上与上一个问题相反,这是冷门的优秀推荐很难被发掘。这时候我们可以用归一化(Normalization)的小伎俩微调一下。值得一提的是,归一化更能给解决一下上一个提及的太过热门的问题。可以说怎样归一化才是各大厂家的杀手锏吧,虽然都可能大同小异,但是不同行业还是需要细分。
实际上,基于相似度的算法的确是非常自然的推荐算法,事实上当数据足够大、足够干净和精确的时候,基于相似度的算法是很难被打败的。但是设想如果是网易音乐发展初期,没有很多用户数据的情况下呢?又如果是网易音乐急速扩张时期,用户数据很多但是很稀疏的时候呢?又从用户角度切入,设想是一个刚加入的新用户,并没有其它用户数据来源来提供推荐的情况下呢?这些冷启动问题,又该如何解决呢?难道就应该放弃这些用户?可能我们可以做更多的小把戏来调整我们的算法,也可以去尝试一些其他算法,尝试去做一些混合推荐算法系统。但是由于产品的研发周期会变长,开发投入变大,系统变复杂,维护的消耗更大,然后更糟糕的是因为进展缓慢,用户一直看的就是不好的推荐,用户开始流失,数据更加稀疏,最后导致恶性循环。
这时,可以尝试通过别的途径来解决这些问题。
我们先从做一个首页显示热门榜单开始,这是一个非常容易实现的功能,计数、排序、简单分类:中国、欧美、日本和韩国,按流派也行:流行、摇滚、古典,甚至按年龄段或者群体,不外乎是几个数据库搜索的事情。但是这些热门排行榜却作用非凡,用户可以从中发现当前的大趋势(Trending),比如说,现在张杰比周杰伦风头要盛,听听张杰的看看怎样。由此榜单也能帮助用户发现他本来兴趣圈以外的东西。这么容易实现的功能,却也可以带来不少的好处。
然后我们来聘请一批专业的媒体编辑员,让他们根据我们歌曲库里的内容,生成比较专业的榜单,比如:“高逼格小清新”,“喧嚣中,不妨试的调调” 还有 “被遗忘的经典华语女声”。用过其它的歌曲软件的人估计对这个也不陌生,比如说虾米。这个也能很大程度上帮助用户发现兴趣圈以外的东西,而且由专业人员生成的歌单,更有目的性,比如说你喜欢苏打绿是因为“小清新”,那么在“小清新”的歌单里的,就是一大批高质量的,对你而言非常优秀的推荐了。这样的功能也能很快组织和实现起来,好处也是大大的。
这其实就是人工推荐和程序推荐的结合。
最后,看到了知乎的威力以后,我们考虑做UGC。从做一个简单的UGC功能开始,我们现在另开一个数据库,允许用户保存自己的歌单,并在个人主页推荐这些歌单。同时我们在主页中定期置顶一些访问量较大的歌单。功能上非常容易实现。UGC所激发的用户潜能可以使得用户产生与专业编辑员质量相当的、甚至更高的歌单。功能上的实现实在是再简单不过,效果更是不言而喻。
这就是不同歌单之间的交互。
这时,我们的很大一部分问题得到解决,就算是我们的基于相似度的算法所产生的推荐并不是那么好的时候,我们的用户并不会由此而失去发现音乐的途径。听歌的人多了,老用户们持续产生高质量的数据,之前的个性化推荐算法也能有更好数据来调整参数,从而产生更好的音乐推荐,更好好的用户群体也能推动热门榜单与UGC的发展,进入良性循环。
大型推荐系统的技术方案
我们知道,电子商务的公司需要定制化界面。否则手机那么小的界面,根本没有办法呈现用户所需的信息,用户很容易流失。所以,因人而异,制定不同的定制化页面是移动互联网时代的制胜关键。那么如何制作一个大型的商品推荐系统呢?比如制作一个类似淘宝口碑那样的兴趣点商品推荐系统。
在制作技术方案时,要考虑用户需求的种类,无非是分:
- 你可能需要买的东西(普遍性需求);
- 你现在想要买的东西(即时刚需);
- 你潜在想要买的东西(潜在普遍性需求和潜在即时刚需)。
通投就是所有的人都可以看到的
地域是按不同的地方投放,
兴趣点就是淘宝对你以往的购买记录进行分析,以及你的搜索情况等,计算出你可能感兴趣的。
在具体的商品推荐技术实现上,淘宝/天猫的商品推荐采用了逻辑回归算法,用了上百亿的特征,并基于库存等约束来进行商品推荐。由于逻辑回归的算法本质上属于一种单层神经网络系统,所以大致的结构如下所示:

其中layer1代表输入的商品特征,比如可以是目前的所有商品,以及其他所能想到的各种特征,layer2可以是目前的所有商品。目的是:当用户购买了一些商品之后,向用户推荐别的**商品。所以训练数据是:输入用户购买的数据的各种特征(没购买或浏览的商品的特征可以为零),输出是用户随后购买的商品(没购买的商品可以设置输出为零)。所以通过大量数据训练后,可以得到一个神经网络,这个神经网络就是所求的推荐系统。这样,每一个用户所看到的商品都是不同的,而且都是她/他很有可能要购买的。
值得一提的是,谷歌或者facebook的推荐系统也采用了逻辑回归算法。
综上所述,我们已经把推荐系统的应用案例剖析讲完了。我们将从下一期开始讲述LBS应用中的数据挖掘方法。
作者简介:
贾双成,阿里巴巴资深工程师,擅长于数据编译、数据挖掘的系统分析和架构设计,主持研发过多个高端车载导航及adas数据编译器。曾发表发明专利、论文四十余篇,著有《LBS核心技术揭秘》、《数据挖掘核心技术揭秘》。














 4133
4133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









