







原文地址:http://mp.weixin.qq.com/s/eZeA4P2uyRSZdiF-rjb7Pw
一、互联网架构为什么要进行服务化-总结
上一篇和大伙交流了一下,随着数据量、并发量、业务复杂度的增长,互联网架构会出现以下问题:
(1)代码到处拷贝
(2)底层复杂性扩散
(3)基础库(so/jar/dll)耦合
(4)SQL质量得不到保障,业务相互影响
(5)数据库耦合
“服务化”是一个很好的解决上述痛点的方案。
不少评论也提出了不少有建设性的观点,汇总出来分享给大伙:
@田卫 同学提到:
服务化之后,可能会引发分布式事务的问题,“没人愿意引入分布式事务,当基于业务水平拆分的时候,要业务专家介入,合理拆分服务化,以后就服务内高内聚,事务可以保证,对于夸服务调用,通过补偿等手段,只要最终一致性就行,毕竟连现在的银行转账都不是强一致性。”
如@田卫所说,分布式事务是业界没有彻底解决的难题,任何架构设计都是一个折衷,吞吐量?时延?一致性?哪个是主要矛盾,优先解决哪个问题。大数据、高并发、业务复杂性是主要矛盾的时候,或许“最终一致性”是一个替代“事务”更好的,或者说业务能够接受的方案。
@侯滇滇 同学提到:
多了一层服务层,架构实际上是更复杂了,需要引入一系列机制对服务进行管理,RPC服务化中需要注意:
(1)RPC服务超时,服务调用者应有一些应对策略,比如重发
(2)关键服务例如支付,要注意幂等性,因为重发会导致重复操作
(3)多服务要考虑并发操作,相当单服务的锁机制比如JAVA中的synchronized
@黄明 同学提到:
服务化之后,随着规模的扩大,一定要考虑“服务治理”,否则服务之间的依赖关系会乱成麻
二、互联网微服务架构多“微”才适合
大家也都认可,随着数据量、流量、业务复杂度的提升,服务化架构是架构演进中的必由之路,今天要讨论的话题是:微服务架构多“微”才合适?
【粗粒度:一个服务层】
最粗犷的玩法,所有基础数据的访问,都通过一个service访问,在业务不是特别复杂的时候还好,一旦业务变复杂了,这个service层会变得非常重,成为耦合点之一,以微信场景为例,假设有一个通用的服务层来访问基础数据,这个服务层可能是这样的:
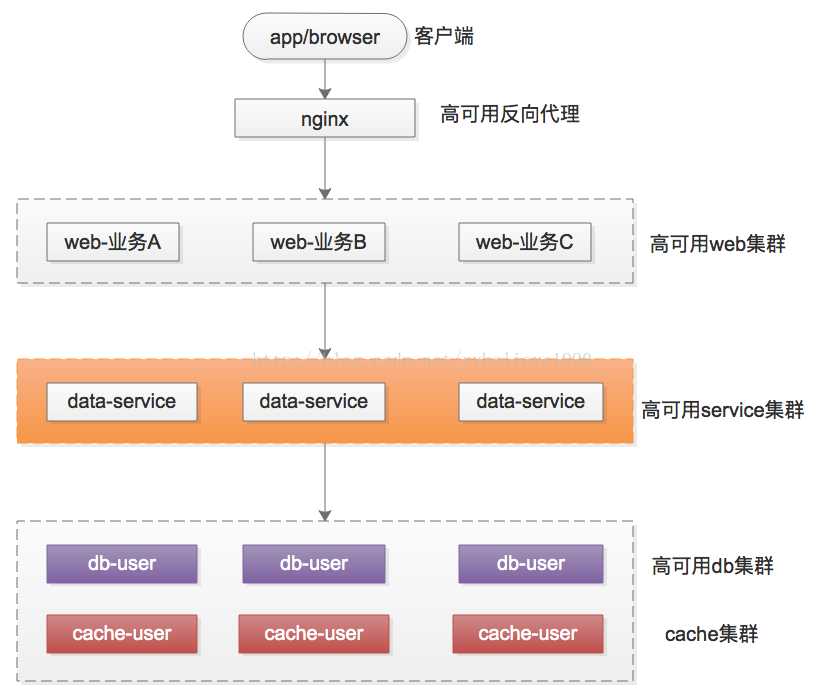
有一个统一的service层,用户信息,好友信息,群组信息,消息信息都通过这个service层来走。
细节:微信单对单消息是一个写多读少的业务,故没有缓存。
【一个子业务一个service】
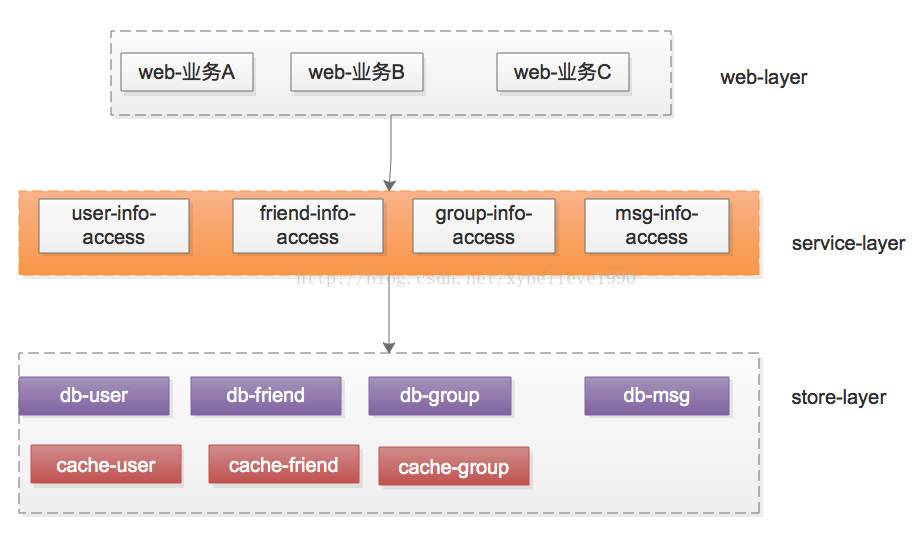
如果所有的信息存储都在一个service里,那么一个地方出bug,就将影响整个业务,所以更合理的做法是在服务层进行细分,架构如何细分?垂直拆分是个好的方案,将子业务一个个拆出来:
(1)用户相关的子业务有user-service
(2)好友相关的子业务有friend-service
(3)群组相关的子业务有group-service
(4)消息相关的子业务有msg-service
这样的话,一个service出问题也不会影响其他service,同时数据层也按照业务垂直拆分开了。
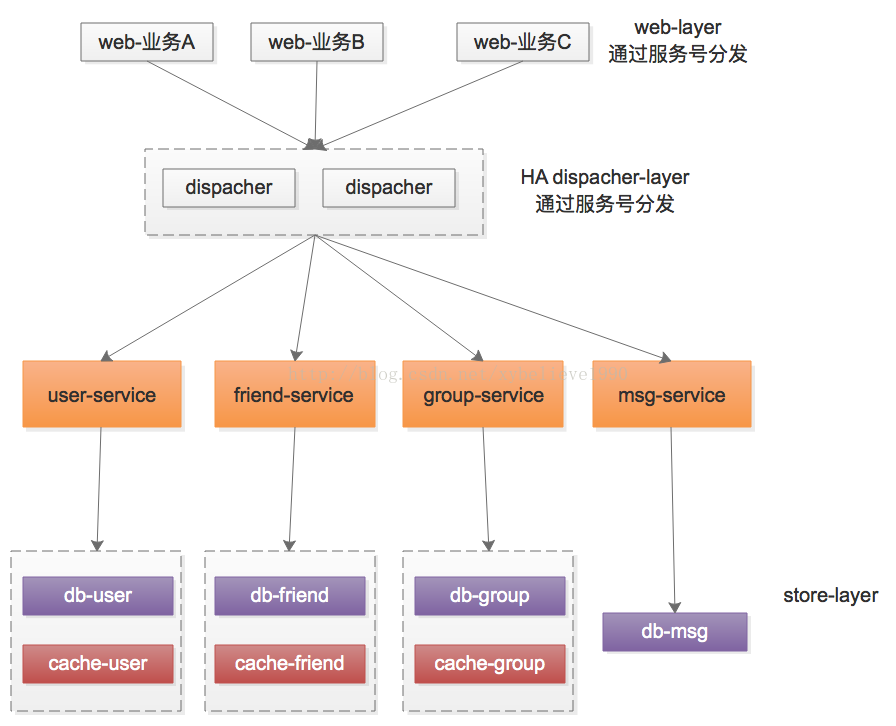
服务粒度变细之后,出现一个新的问题,业务与服务的连接关系变复杂了,有什么好的优化方案么?
常见的,加入一个高可用服务分发层集群,并在协议设计时加入服务号,可以减少蜘蛛网状的依赖关系:
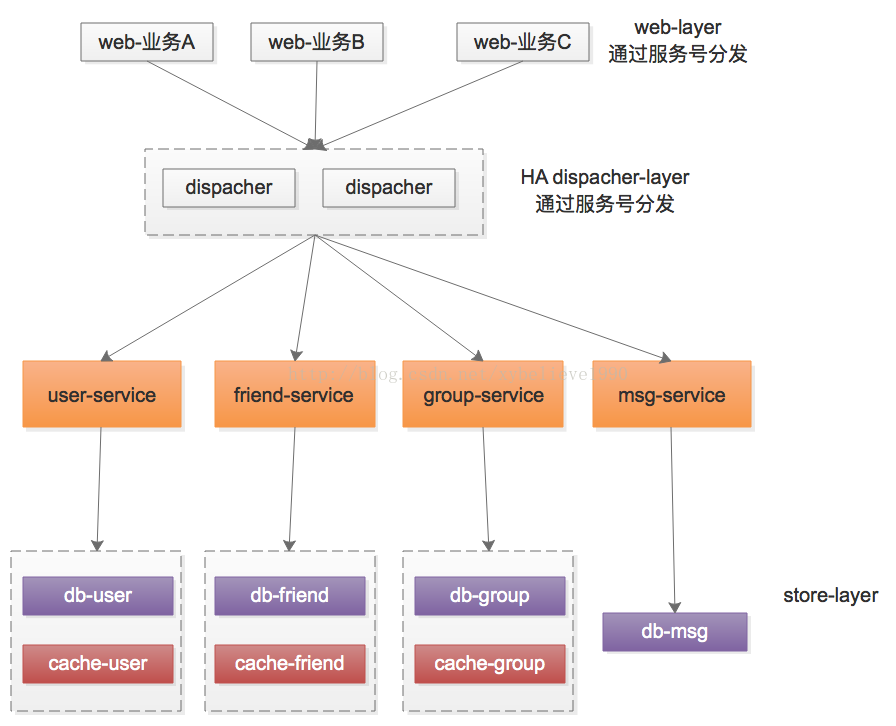
(1)调用方依赖分发层,传入服务号
(2)分发层依赖服务层,通过服务号参数分发
【一个数据库对应一个service】
数据访问service最初是从DAO/ORM的数据访问需求过来的,所以有些公司也有一个数据表一个service的玩法。
一个子业务对应一个service的玩法是:
(1)服务层,整个群业务是一个service
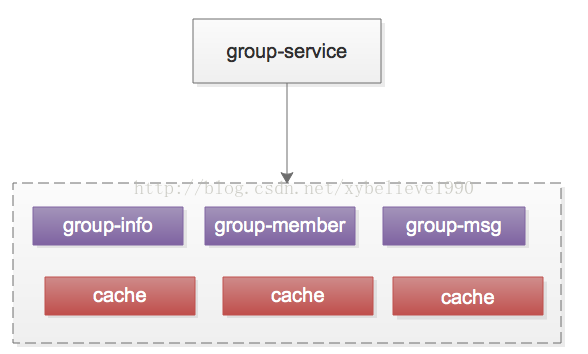
(2)存储层,实际可能对应了群信息、群成员、群消息等多个数据表
拆分成一个数据表一个service,则架构会变成这样:
群信息表,群成员表,群消息表等各个数据表之间也解耦开了,不会相互影响了。
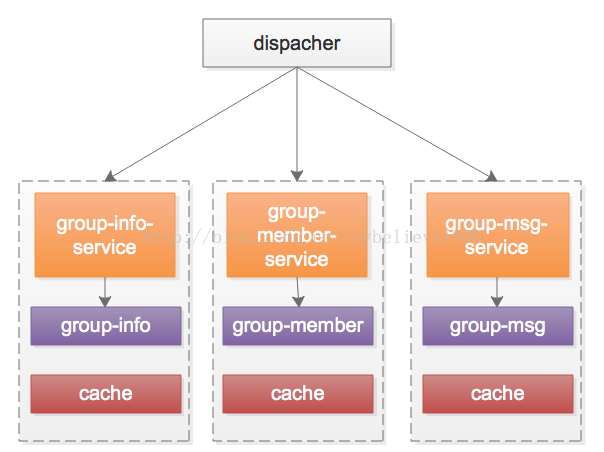
【一个接口对应一个service】
微服务架构中更极端的,甚至一个接口对应一个微服务,这样的话,架构就演化为:
(1)修改群信息服务
(2)增加群信息服务
(3)获取群信息服务
多个服务操纵同一个数据表,使用同一片缓存,每个接口出问题,都不会影响其他接口。
三、粒度粗细的优劣
上文中谈到的服务化与微服务,不同粒度的服务化各有什么优劣呢?
总的来说,细粒度拆分的优点有:
(1)服务都能够独立部署
(2)扩容和缩容方便,有利于提高资源利用率
(3)拆得越细,耦合相对会减小
(4)拆得越细,容错相对会更好,一个服务出问题不影响其他服务
(5)扩展性更好
(6)…
细粒度拆分的不足也很明显:
(1)拆得越细,系统越复杂
(2)系统之间的依赖关系也更复杂
(3)运维复杂度提升
(4)监控更加复杂
(5)出问题时定位问题更难
(6)…
关于微服务架构的“粒度”问题,以及各粒度的优劣,大伙有什么好的看法,欢迎补充,建设性的意见将在后续文中和大伙share。
四、结束的话
聊了许多,有网友问,笔者对待服务化以及微服务粒度的看法,个人觉得,以“子业务系统”粒度作为微服务的单位是比较合适的:
末了,讨论完微服务架构的粒度,后续文章和大家聊一聊微服务的最佳实践,需要什么样的框架、组件、技术能够将服务化在较短的时间内开展起来。














 1671
1671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









