




【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
二、重要方法整理
2.1 【LDM】High-Resolution Image Synthesis with Latent Diffusion Models
(Stable Diffusion 核心算法)
- 改进点:扩散在潜空间(latent space)实现【对比:DDPM是图像像素层面的扩散,效率低】
- Pipeline:
- 由 VQ-VAE【编码图像
到离散特征
,再解码回图像】和 Diffusion【对离散特征
- 前向:图像【输入】→ VQVAE的编码器【得离散特征
- 反向:
→ U-Net去噪【每层由CNN和交叉注意力实现,并加入条件控制生成】→

- 由 VQ-VAE【编码图像
- 条件机制:
- 先用领域编码器
将不同条件转化为特征(比如文本用Bert,图像用CLIP)
- 特征作为U-Net中交叉注意力的 key 和 value
- 先用领域编码器
- 为什么在潜空间扩散会加速?
- 潜空间的特征是VQVAE压缩之后的特征,比图像特征小很多
2.2 【DiT】Scalable Diffusion Models with Transformers
- 改进点:用Transformer 架构替换 UNet 架构
- Pipeline:
- Image Token生成:图片 → Patchify【每个patch由
个像素组成】→ Tokens(一个patch为一个token)
- DiT Block(针对如何引入额外信息探索了四种策略)
( 举例时间步长和类别标签作为额外信息: timesteps token;
: class label token)
- In-Context Conditioning:将
- Cross-Attention:用交叉注意力实现 图像tokens和
- Adaptive layer norm (adaLN):用
和
)
- adaLN-Zero:除了回归缩放
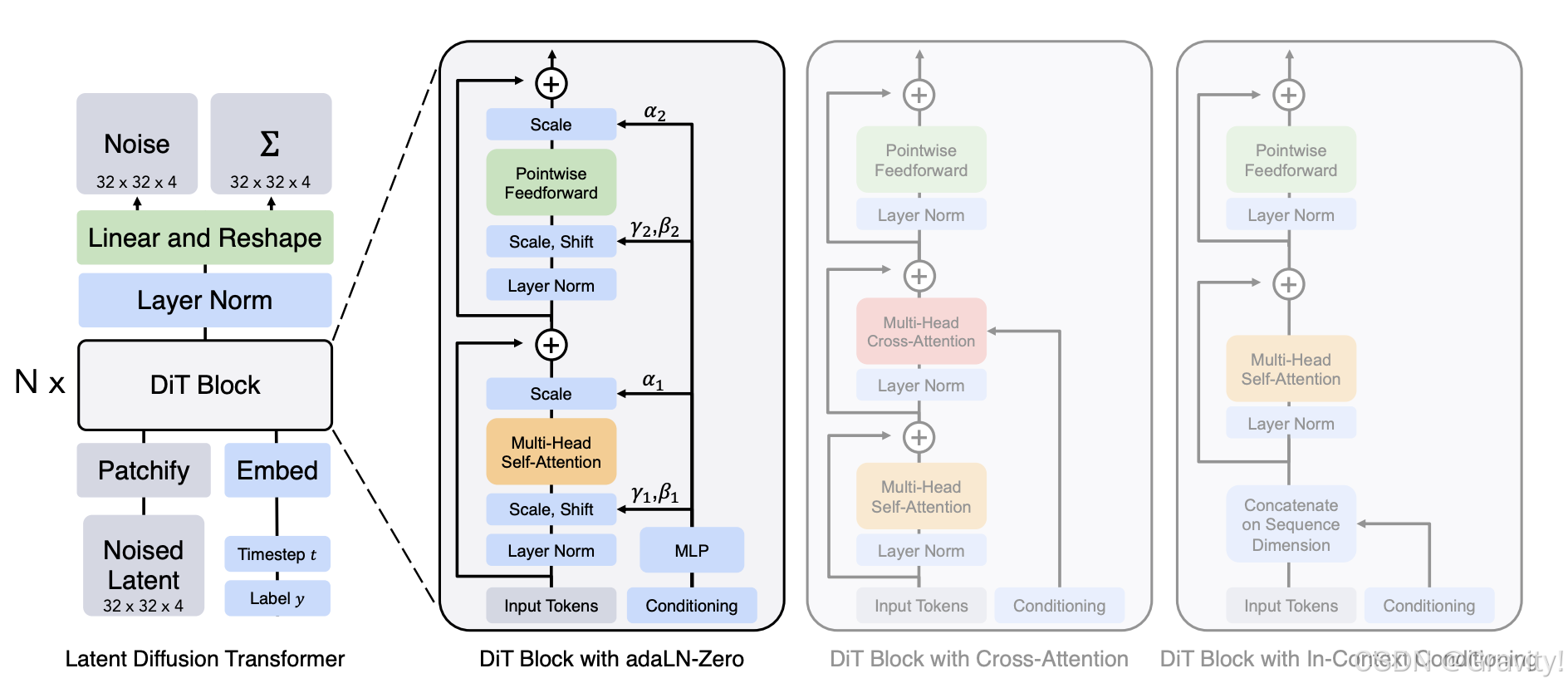
- In-Context Conditioning:将
- 四种策略性能对比
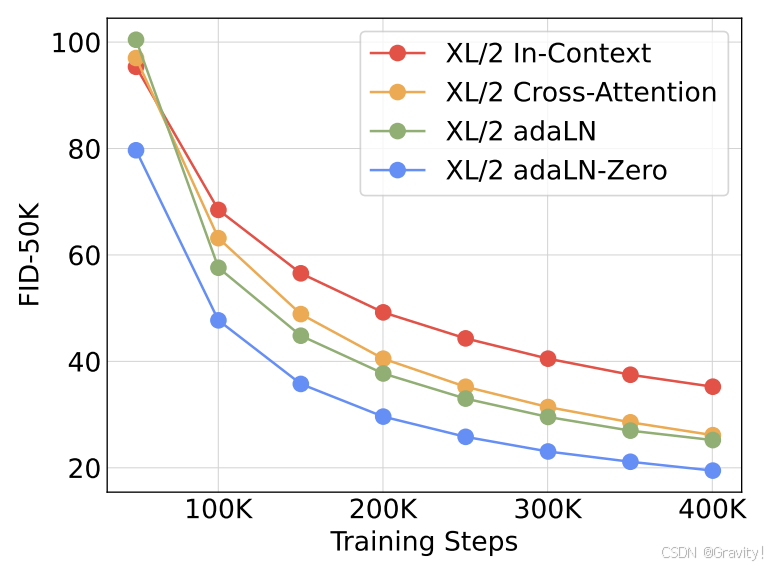
- Image Token生成:图片 → Patchify【每个patch由

















 4777
4777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









