










声明:本文只是JDBC和数据库的一个知识路线图,只是给出了一个大概的学习结构,很多东西提到了但是没有细节,需要自行丰富。
一、基本操作
JDBC的基本操作,总结起来就是“注册驱动、获取连接、获取执行对象并执行SQL、获取结果集并处理、关闭资源”,每一个步骤都有一些东西值得沉淀。
1. 注册驱动
a. DriverManager.registerDriver(Driver driver)会导致驱动重复注册问题;
b. Class.forName进行驱动注册:类加载知识、静态代码块知识,需要care和ClassLoader.load的区别;
c. 注册驱动流程;
2. 获取连接
a. CopyOnWriteArrayList知识(作为MVCC中的特例,只存在一个都版本的MVCC,两者在任何时刻都只存在一个加锁写);
b. DriverManager.getConnection细节:遍历CopyOnWriteArrayList,然后从头到尾的尝试driver.connect方法,直到取到第一个不抛异常不为null的连接,返回并break循环;connect方法实际上是通过反射com.MySQL.jdbc.ConnectionImpl,在ConnectionImpl的构造函数中,会常见com.mysql.jdbc.MysqlIO实例,创建成功后会基于socket(jdbc:mysql://localhost:3306/database,主协议jdbc,子协议mysql)与服务器进行doHandshake握手,不抛异常则表示连接成功;否则失败,继续遍历CopyOnWriteArrayList直到结束;这里也是驱动重复注册浪费性能的原因,每一次都是找第一个可用的,但是实际上只有当获取连接对象的时候才会分配端口、网络等资源,因此这个性能浪费可控,并不是那么昂贵;
c. JDBC核心对象:Connection的实现类是整个JDBC的核心对象,基于socket连接应用程序和数据库服务器;
d. 获取数据库元信息(conn.getMetaData);
e. 事务API,需要关注隔离级别(隔离级别和MVCC放在一起讨论,这两个技术的目的是为了什么,弄清楚这个问题,就知道为什么要放在一起讨论了)和持久性(例如mysql的undo、redo);
f. readonly的含义;
3. 获取执行对象并执行SQL
3.1 ResultSet的设定
a. Statement createStatement(int resultSetType, int resultSetConcurrency, nt resultSetHoldability) throws SQLException;
b. PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException;
c. CallableStatement prepareCall(String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException;
其中:
a. resultSetType:只读、滚动但是对数据变化不敏感、滚动但是对数据变化敏感,ResultSet.TYPE_FORWARD_ONLY、ResultSet.TYPE_SCROLL_INSENSITIVE、ResultSet.TYPE_SCROLL_SENSITIVE;
b. resultSetConcurrency:结果集并发类型,只读和可通过ResultSet对象更新,ResultSet.CONCUR_READ_ONLY、ResultSet.CONCUR_UPDATABLE;
c. resultSetHoldability:连接对象关闭之后结果集是否能继续使用,ResultSet.HOLD_CURSORS_OVER_COMMIT、ResultSet.CLOSE_CURSORS_AT_COMMIT;
3.2 插入自增主键
a. int executeUpdate(String sql, int autoGeneratedKeys) throws SQLException;
b. PreparedStatement prepareStatement(String sql, int autoGeneratedKeys) throws SQLException;
其中,autoGeneratedKeys分成返回自增主键Statement.RETURN_GENERATED_KEYS和无自增主键Statement.NO_GENERATED_KEYS;
3.3 查询超时原理
见下文。
3.4 大数据量防止OOM的配置;
见下文。
3.5 PreparedStatement
PreparedStatement正确使用才能提高效率,否则其效率是比Statement还要低,至于怎么用,还需要考虑防止SQL注入等安全性。
3.6 CallableStatement
这个使用只需要关注数据库中procedure的参数input/output类型的对应即可。
4. 获取结果集并处理
a. 根据设定的ResultSet类型进行查询处理;
b. 根据设定的ResultSet的并发类型进行更新;
c. 获取数据库表的元信息(getMetaData);
d. fetch size问题,下文中大数据量查询防止OOM中介绍;
5. 关闭资源
关闭资源没有太多需要注意的地方,只不过需要更好的容错,先判断null再关闭,至于资源的分配时机,则是在DriverManager.getConnection的时候分配。
二、高级操作
1. 批处理
a. 批处理是容易导致死锁的,因为需要自己控制事务,否则mysql JDBC中的批处理和一个一个的提交操作没有区别,才考mysql最新版本的驱动源码,ConnectorJ,本文源码摘自最新版本5.1.38;
b. 再次重申一遍,批处理需要自己控制事务,否则和单独提交没有区别,当然有优化,在连接的时候url添加服务器端参数rewriteBatchedStatements=true,这样就会把批处理的SQL一次性发送到服务端,而不是一次一次的发送;
c. api:addBatch、clearBatch、executeBatch;
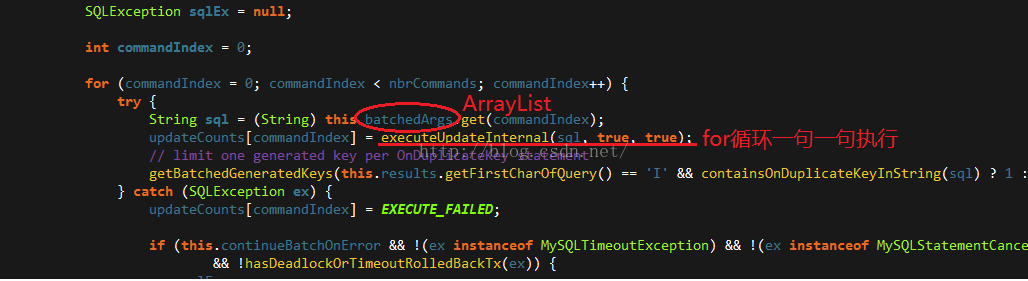
c. mysql批处理原理及源码参考:源码截图如下,实际上批处理就是在addBatch的时候把sql放入一个ArrayList,然后在executeBatch调用的时候for循环出来一个一个执行,最后清空这个ArrayList,因此要想使用真正的批处理,则JDBC获取连接的时候就需要和服务器进行沟通,因此需要在URL中添加服务器端参数rewriteBatchedStatements=true。
源码参见com.mysql.jdbc.StatementImpl.executeBatchInternal(),关键部分截图如下所示:
2. Blob/Clob
至于Blob和Clob,就是字节流和字符流的操作,重点在数据库要不要给全文索引这些东西;
3. 连接池
至于连接池,常用的DBCP、C3P0、JNDI、HikariCP等等,其使用的关键和设计的关键:
a. 基本配置,譬如什么空闲连接数、总连接数啊等等;
b. 事务配置,隔离级别、自动提交等;
c. 健康性检查,取时测试、还回时测试、mysql8小时问题等等;
三、关键知识点
1. 连接和事务管理
做持久层的东西,必然要关注事务,否则数据一致性无法保证。至于JDBC的事务,需要从几个方向来了解:
a. 数据库锁基本操作和原理;
b. 连接管理的应用设计:基于方法栈、基于线程局部变量、基于同步加锁,要提高并发,采用MVCC、copy on write技术等等;
在事务的ACID中(当然,spring基于线程局部变量的传播特性在这里就不讨论了,Spring这部分的源码并不晦涩,多看几次就懂了),AID的提出都是为了保证C(数据一致性),至于A原子性通过加锁来保证,需要跟深入的讨论的是则是I和D,隔离性和持久性。
隔离性描述的是并发事务中数据一致性问题,不同的隔离级别能看到其他事务中数据的中间状态的程度不一样,当然隔离级别是基于数据库锁的,因此对读写并发性会照成很大的影响,因此引入了MVCC;不同数据库对MVCC的支持不一样,从mysql的角度来讨论,只有RC和RR才支持MVCC,而从RC的角度看MVCC和RR的角度来实现MVCC是不一样的,需要分开来讨论,否则不可能掌握隔离级别和MVCC。
至于持久性,既要追求性能又要保证数据安全,因此mysql插入缓存和redo\undo log配套出现,通过内存缓冲和磁盘日志的顺序写异步了磁盘的随机写,从而提高性能又保证数据持久安全。
2. 查询超时原理
之前简写了一篇博客,基于connectorJ 5.1.37,和最新版的jar包并无变化。
mysql查询超时原理:点击打开链接
3. 大数据量查询时防止OOM
3.1. 服务器端fetch_size(不建议)
这种方式会在服务器生成临时表,因此性能上表现并不好。
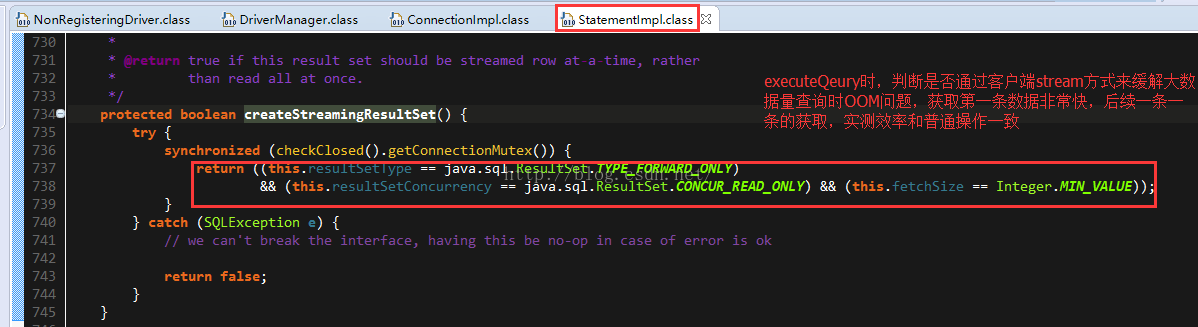
3.2. 客户端stream
参见实现源码截图。
参见博客:点击打开链接
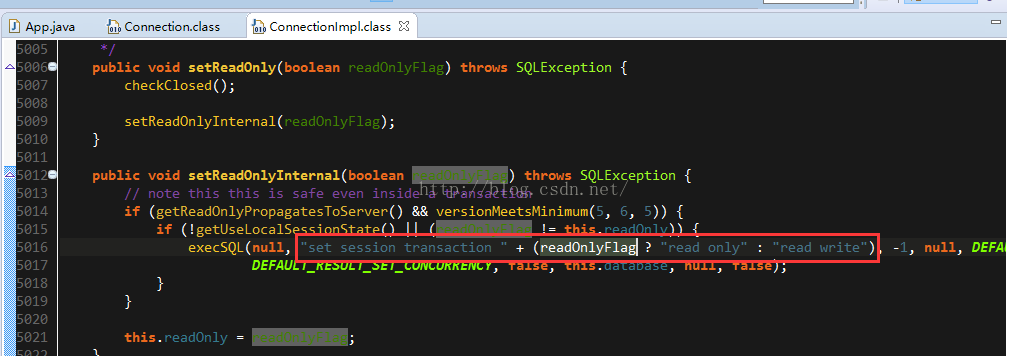
4. ReadOnly原理
a. 参见mysql开发手册:点击打开链接
b. 参见源码实现:
5. 批操作原理
见上文。
附注:
本文是自己总结的持久层知识,当然不包括一些持久层框架,譬如DButils、Spring JDBC和Spring Transaction、mybatis、hibernate,但是这些持久层框架的实现,必然离不开这些原理。
没有提及的内容,后续工作用发现将会持续补充,谢谢!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









