







InnoDB中的事务完全符合ACID特性《mysql事务》。
- 原子性(atomicity)
- 一致性(consistency)
- 隔离性(isolation)
- 持久性(durability)
其中 一致性,隔离性基本上与锁密切相关。
事务的四种隔离级别
- READ UNCOMMITTED(未提交读)。在RU的隔离级别下,事务A对数据做的修改,即使没有提交,对于事务B来说也是可见的。这种问题叫脏读。这是隔离程度较低的一种隔离级别,在实际运用中会引起很多问题,因此一般不常用。
- READ COMMITTED(提交读)。在RC的隔离级别下,不会出现脏读的问题。事务A对数据做的修改,提交之后会对事务B可见。举例,事务B开启时读到数据1,接下来事务A开启,把这个数据改成2,提交,B再次读取这个数据,会读到最新的数据2。在RC的隔离级别下,会出现不可重复读的问题。这个隔离级别是许多数据库的默认隔离级别。
- REPEATABLE READ(可重复读)。在RR的隔离级别下,不会出现不可重复读的问题。事务A对数据做的修改,提交之后,对于先于事务A开启的事务是不可见的。举例,事务B开启时读到数据1,接下来事务A开启,把这个数据改成2,提交,B再次读取这个数据,仍然只能读到1。在RR的隔离级别下,会出现幻读的问题。幻读的意思是,当某个事务在读取某个范围内的值的时候,另外一个事务在这个范围内插入了新记录,那么之前的事务再次更新这个范围的值,直接覆盖另一事务的变更。Mysql默认的隔离级别是RR,然而mysql的innoDB引擎间隙锁成功解决了幻读的问题。(不可重复读是读异常,但幻读则是写异常)
- SERIALIZABLE(可串行化)。可串行化是最高的隔离级别。这种隔离级别强制要求所有事物串行执行,在这种隔离级别下,读取的每行数据都加锁,会导致大量的锁征用问题,性能最差。
锁问题
1.脏读(Read Uncommitted)
异常结果:事务B中2次读取结果不一样。第二次读到没提交的数据(脏数据)。
2.不可重复读 (READ COMMITTED)
异常结果:事务B中2次读取结果不一样。
3.丢失更新(幻读)(REPEATABLE READ):
| 时间点 | 事务A | 事务B |
|---|---|---|
| 1 | 开启事务A | |
| 2 | 开启事务B | |
| 3 | 查询当前商品S库存为100 | |
| 4 | 查询当前商品S库存为100 | |
| 5 | 业务逻辑处理,确定要将商品S库存增加10,故更新库存为110(update stock set amount= amount + 10 where sku_id=S;) | |
| 6 | 业务逻辑处理,确定要将商品S库存增加20,故更新库存为120(update stock set amount= amount +20 where sku_id=S;) | |
| 7 | 提交事务A | |
| 8 | 提交事务B |
暂时忽略锁的异常结果:商品S库存为100,如果不存在锁, 第一次的10,会被第二次加20所覆盖得结果为120,首先提交的事务A的更新『丢失了』!!! 但实际上针对商品S进行了两次入库操作,最终商品S库存应为100+10+20=130,所以就需要锁机制来保证这种上述情况不会发生。
InnoDB存储引擎中的锁
锁的作用域
行锁是实现在索引上的,而不是锁在物理行记录
锁的类型
InnoDB存储引擎实现如下两种标准的行级锁
-
共享锁(S LOCK) : 允许事务读一行(表)数据
- 排它锁(X LOCK) : 允许事务删除或更新一(表)数据
加锁及释放
- 加锁:需要用的锁的时候自动加载,例 select for update, update ,delete
- 释放:显式或者隐式commit
锁的粒度
InnoDB支持多粒度(granular)锁定,这种锁定允许事务在行级上的锁和表级上的锁同时存在。为了支持在不同粒度上进行加锁操作,InnoDB存储引擎支持一种额外的锁方式,称之为意向锁(Intention Lock)。意向锁是将锁定的对象分为多个层次,意向锁意味着事务希望在更细粒度上进行加锁。即对记录上行锁(S,X)时,必须获取表的意向锁
- 意向共享锁(IS Lock) : 事务想要获得一张表中某几行的共享锁
- 意向排它锁(IX Lock) : 事务想要获得一张表中某几行的排它锁
意向锁与行级锁的兼容性
| IS | IX | S | X | |
|---|---|---|---|---|
| IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 兼容 | 兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 兼容 | 不兼容 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
IS,IX 对应的 S,X 都是表级别的
事务1获取表A的IX(想修改表A中记录a),,如果表A已被事务2锁住X。不兼容,获取失败。
事务1获取表A要获取表的IX,记录a上X锁。事务2也获想改a记录,获取表A的IX兼容,但获取a记录X则不兼容
锁的算法
- Record Lock : 单个行记录上的锁
- Gap Lock : 间隙锁,锁定一个范围,单不包含记录本. 另外有种特殊的间隙锁叫插入意向锁(Insert Intention Locks)
- Next-Key Lock : Gap Lock + Record Lock,锁定一个范围,并且锁定记录本身
// 使用以下语句创建测试表
create table z( a INT, b INT, c INT default 0, PRIMARY KEY(a), KEY(b));
INSERT INTO z SELECT 1,1,1;
INSERT INTO z SELECT 3,1,2;
INSERT INTO z SELECT 5,3,3;
INSERT INTO z SELECT 7,6,4;
INSERT INTO z SELECT 10,8,5;此时z分别建立了一个唯一索引a(主键)和 普通索引b.如下图
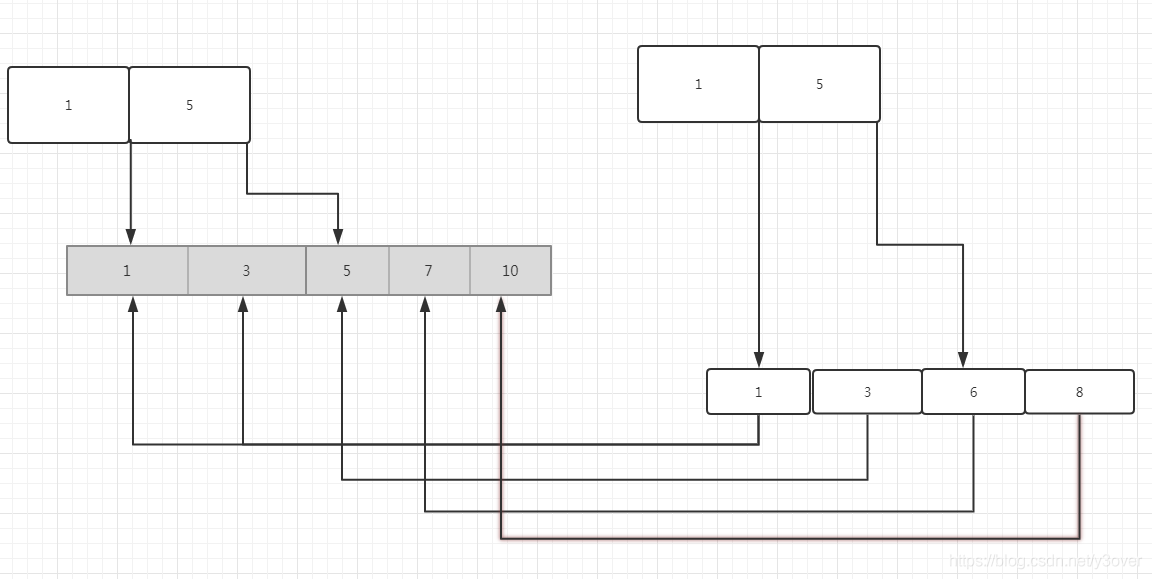
ps: 普通索引1对应主键1,3二条记录
场景1:
select * from z where b = 3 for update;-
其中b是辅助索引,使用next-keyLocking加锁,对2个索引进行分别锁定。加锁顺序为:
-
辅助索引加上(1<b<3)及(3<b<6)的grap 和 其叶子 Record Lock(3,5)
-
聚焦索引对(a=5)记录上Record Lock.
如果此时执行
select * from z where a = 5 lock in share mode;
insert into z select 4,2;
-
第1句SQL语句不能执行,因为聚焦索引对(a=5)记录上,有X锁,执行此SQL要有此记录S锁,冲突。
-
第2句SQL语句不能执行,因为主键4插入没问题,插入辅助索引2,被上有(1,3)的grap锁,冲突。
当修改数据隔离级别调整为RC,第2句语句就可以使用了。因为(1<b<3)及(3<b<6)的grap在RC级别不存在
场景2:
// 删除(a=1)记录后,把b换成唯一锁索
ALTER TABLE `z` DROP INDEX `b`, ADD UNIQUE INDEX `b`(`b`) USING BTREE;
select * from z where a =3 FOR UPDATE;-
其中b是唯一索引,使用next-keyLocking加锁,对1个索引进行分别锁定。
- 唯一索引 其叶子 Record Lock(3,5)
-
聚焦索引对(a=5)记录上Record Lock.
如果此时执行
select * from z where a = 5 lock in share mode;
insert into z select 4,2;
-
第1句SQL语句不能执行,因为聚焦索引对(a=5)记录上,有X锁,执行此SQL要有此记录S锁,冲突。
-
第2句SQL语句能执行,因为主键4插入没问题,插入辅助索引2,没有被上有(1,3)的grap锁,没冲突。
关于唯一比较普通索引的锁退化总结:

唯一索引,唯一性检测即“Duplicate entry”,会加上Next-Key Lock锁。《主键重复和唯一索引冲突_insert唯一键冲突的加锁情况分析》
场景3:
insert z select 22, 9-
其中b是辅助索引,因为不存在b=9的记录 使用gap加锁,对1个索引进行锁定。
- 辅助索引加上(8,正无穷)的gap,并对 (9,22)进行一个插入意向锁(相似与记录错)
如果些时执行
insert into z select 8,11;
select * from z where b = 9 for update;
insert z select 22, 9-
第1句SQL语句不能执行,因为辅助索引对(8,正无穷)有间隙锁,冲突
-
第2句SQL语句能执行,它也申请的是辅助索引上(8,正无穷)有间隙锁,间隙锁不冲突
-
第3句SQL语句不能执行,它也申请的是辅助索引上(8,正无穷)有间隙锁,间隙锁不冲突。但它申请辅助索引上(9,22)的插入意向锁冲突
插入意向锁也是间隙锁,它也只作用在间隙。因为insert场景比较特殊,其不存在记录,因此插入意向锁其实是可理解成记录锁。 获取插入意向锁会把插入的数据放到mysql提供的插入缓存中,如果事务回滚则不提交,否则提交。

RR模式下Gap锁的作用:
RR模式下引入MVCC做版本控制,实现快照读。当对数据发生修改时,总是要基于最新的数据,获取最新数据的过程称为当前读。
// 当前读语句
select ... lock in share mode、select ... for update
insert、update、delete但RR模式,要保证其事务内当前读是最新的(防止幻读),因此只能采用gap锁阻止当前读。比如以下语句:
// 事务A,快照读
select * from z where b=3
// 事务B
insert into z select 4,3;
或者
update z set b=3 where id=1;
// 事务A,当前读(可以读到b事务的变更)
select * from z where b=3 for update;
// 事务A,快照读(不可以读到b事务的变更)
select * from z where b=3 ;- 在RR级别下,快照读是通过MVCC(多版本控制)和undo log来实现的
- 在RR级别下,当前读是通过加record lock(记录锁)和gap lock(间隙锁)来实现的。
- RR级别防止幻读是基于当前读的,如果先快照读然后当前读会不一致。
Mysql的锁相关命令
// 查看正在被锁定的的表
// in_use:多少个线程在使用
// name_locked:是否被锁
show OPEN TABLES where In_use > 0;
// 查询哪些线程正在运行,最关键的就是state列
show processlist;
// 查看正在锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
// 查看等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
// 查mysql当前默认的存储引擎:
show variables like '%storage_engine%';
// INNODB监控器,查看当前sql运行日志
SHOW ENGINE INNODB STATUS
// 查询会话隔离级别
SELECT @@tx_isolation
// 设置会话隔离级别
set session transaction isolation level repeatable read;
全局锁
全局锁就是对整个数据库实例加锁。MySQL 提供了一个加全局读锁的方法,命令是Flush tables with read lock (FTWRL)。 当你需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:
-
数据更新语句(数据的增删改)
-
数据定义语句(包括建表、修改表结构等)
-
更新类事务的提交语句
全局锁的典型使用场景是,做全库备份。可参考《mysql的复制及备份》
表锁
表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)。
表锁
-
在InnoDB中在对记录上行锁时,必须获取表的共享锁和意向排它锁(上文提到)
-
InnoDB 的行锁是实现在索引上的,而不是锁在物理行记录上。所以如果访问没有命中索引,也无法使用行锁,将要退化为表锁(准确的说应该是全表的行锁)
-
显示加表锁的语法是 lock tables … read/write,功能与 FTWRL 类似,可以用 unlock tables 主动释放锁。
元数据锁MDL
元数据锁不需要显式使用,在访问一个表的时候会被自动加上。MDL的作用是,保证读写的正确性。你可以想象一下,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,删了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。即对一个表做增删改查操作的时候,加 MDL读锁;当要对表做结构变更操作的时候,加 MDL 写锁.
对表t执行以下操作
1. sessionA:
select * from t limit 1;
#mdl读锁
2. sessionB:
select * from t limit 1;
#mdl读锁
3. sessionC:
alter table t add f int;
#会mdl写锁
4. sessionD:
select * from t limit 1;
#会mdl读锁,会被block
只有 session C 自己被阻塞,但是之后sessionD要在表 t 上新申请 MDL 读锁的请求也会被 session C 阻塞。前面说了,所有对表的增删改查操作都需要先申请MDL读锁,而这时读锁没有释放,对表alter ,产生了mdl写锁,把表t锁住了,这时候就对表t完全不可读写了。一般行锁都有锁超时时间。但是MDL锁没有超时时间的限制,只要事务没有提交就会一直锁注。所以只能通过提交事务,回滚事务解决。因此,给一个小表加个字段,也有可能导致整个库挂的风险。
online ddl
为了解决ddl变更会锁表,导致库上大量线程处于“Waiting for meta data lock”的状态。mysql 5.6提出online ddl特性这个特性解决了执行ddl锁表的问题。具体将ddl分类实现,针对不同类型的ddl进行不同的算法操作。
| 类型 | 并发DML | 算法 | 备注 |
| 添加/删除索引 | Yes | Online(no-rebuild) | 全文索引不支持 原来是 inplace方式执行的 |
| 修改default值 修改列名 修改自增列值 添加/删除外键约束 | Yes | Nothing | 仅需要修改元数据 |
| 添加/删除列 交换列顺序 修改NULL/NOT NULL 修改ROW-FORMAT 添加/修改PK Optimize table | Yes | Online(rebuild) | 由于记录格式改变,需要重建表 |
| 修改列类型 删除PK 转换字符集 添加全文索引 | No | Copy | 需要锁表,不支持online |
copy方式(原来就有)
-
新建带索引的临时表
-
锁原表,禁止DML,允许读
-
将原表数据拷贝到临时表(无排序,一行一行拷贝)
-
进行rename,升级MDL,禁止读写
-
完成创建索引操作
inplace方式(原来就有的)
-
新建索引的数据字典
-
锁表,禁止DML,允许读
-
读取聚集索引,构造新的索引项,排序并插入新索引
-
等待打开当前表的所有只读事务提交
-
创建索引结束
online ddl主要思路是用简单的全量+增量的方式实现,主要包括3个阶段,rebuild方式比no-rebuild方式实质多了一个ddl执行阶段。
Prepare阶段:
-
创建新的临时frm文件
-
持有EXCLUSIVE-MDL锁,禁止读写
-
根据alter类型,确定执行方式(copy,online-rebuild,online-norebuild)
-
更新数据字典的内存对象
-
分配row_log对象记录增量(记录了ddl变更过程中新产生的dml操作)
-
生成新的临时ibd文件
ddl执行阶段:
-
降级EXCLUSIVE-MDL锁,允许读写
-
扫描old_table的聚集索引每一条记录rec
-
遍历新表的聚集索引和二级索引,逐一处理
-
根据rec构造对应的索引项
-
将构造索引项插入sort_buffer块
-
将sort_buffer块插入新的索引
-
处理ddl执行过程中产生的增量(仅rebuild类型需要,因为重建表操作,量大,尽可能减少锁的时间)
commit阶段
-
升级到EXCLUSIVE-MDL锁,禁止读写
-
重做最后row_log中最后一部分增量(将新产生的dml操作应用到新的表中,保证数据完整性)
-
更新innodb的数据字典表
-
提交事务(刷事务的redo日志)
-
修改统计信息
-
rename临时idb文件,frm文件
-
变更完成
主要参考
《Innodb技术内幕》














 3082
3082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









