









这里补充一些:
(1)InnoDB默认加锁方式是next-key locking
(2)在聚集索引中,如果主键有唯一性约束(unique,auto increment),next-key locking 会自动降级为record locking。
(3)由于事务的隔离性和一致性要求,会对所有扫描到的record加锁。比如:update ... where/delete .. where/select ...from...lock in share mode/ select .. from .. for update这都是next-key lock。
(4)注意优化器的选择。包括聚集索引和辅助索引,有时会用全表扫描替代索引扫描,这时整张表(聚集索引表)都会被加锁。
record lock:记录锁,也就是仅仅锁着单独的一行
gap lock:区间锁,仅仅锁住一个区间(注意这里的区间都是开区间,也就是不包括边界值,至于为什么这么定义?innodb官方定义的)next-key lock:record lock+gap lock,所以next-key lock也就半开半闭区间,且是下界开,上界闭。(为什么这么定义?innodb官方定义的)
下面来举个手册上的例子看什么是next-key lock。假如一个索引的行有10,11,13,20
那么可能的next-key lock的包括:
(无穷小, 10]
(10,11]
(11,13]
(13,20]
(20, 无穷大) (这里无穷大为什么不是闭合?你数学不到家~~)
好了现在通过举例子说明:
表test
mysql> show create table test;
+-------+--------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------+
| test | CREATE TABLE `test` (
`a` int(11) NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+--------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> select * from test;
+----+
| a |
+----+
| 11 |
| 12 |
| 13 |
| 14 |
+----+
4 rows in set (0.00 sec)
开始实验:
(一)
session 1:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from test where a=11;
Query OK, 1 row affected (0.00 sec)
session 2:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test values(10);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values(15);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values(9);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values(16);
Query OK, 1 row affected (0.01 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
ok,上面的情况是预期的,因为a上有索引,那么当然就只要锁定一行,所以其他行的插入不会被阻塞。
那么接下来的情况就有意思了
(二)
session 1(跟上一个session 1相同):
delete from test where a=22;
Query OK, 0 rows affected (0.01 sec)
session 2:
mysql> insert into test values (201);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (20);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (19);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (18);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (16);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (9);
Query OK, 1 row affected (0.00 sec)
从上面的结果来看,在a=14后面所有的行,也就是区间(14,无穷大)都被锁定了。先不解释原因,再来看一种情况:
(三)
session 1:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test;
+----+
| a |
+----+
| 7 |
| 9 |
| 10 |
| 12 |
| 13 |
| 14 |
| 15 |
| 22 |
| 23 |
| 24 |
| 25 |
+----+
11 rows in set (0.00 sec)
mysql> delete from test where a=21;
Query OK, 0 rows affected (0.00 sec)
session 2:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test values (20);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (26);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values (21);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (16);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (6);
Query OK, 1 row affected (0.01 sec)
从这里可以看出,现在被锁住的区间就只有[16,21)了。
有了前面对三种类型的加锁解释,现在可以来解释为什么会这样了,在innodb表中 delete from where ..针对扫描到的索引记录加next-key锁(具体的什么语句加什么锁可以查看手册,另外需要说明一下,行锁加锁对象永远是索引记录,因为innodb中表即索引) 。
在(一)中,实际上加的next-key lock就是(11,11] 因此也只有a=11这一条记录被锁住,其他所有插入都没有关系。
在(二)中,因为a=22这条记录不存在,而且22比表里所有的记录值都大,所以在innodb看来锁住的区间就是(14, 无穷大)。所以在插入14以后的值都提示被锁住,而14之前的则可以。
在(三)种,a=21也是不存在,但是在表里面21前后都有记录,因此这里next-key lock的区间也就是(15,21],因此不在这个区间内的都可以插入。
另外next-key lock虽然在很多时候是锁一个区间,但要明白一个区间也可能只有一个元素。
另外还提两点:
1.如果我们的SQL语句里面没有利用到索引,那么加锁对象将是所有行(但不是加表锁),所以建索引是很重要的
2.next-key lock是为防止幻读的发生,而只有repeatable-read以及以上隔离级别才能防止幻读,所以在read-committed隔离级别下面没有next-key lock这一说法。
----------------------------------华丽的分割线------------------------------
当一个表中既存在主键,又存在非唯一索引时,是如何锁定的呢?
自己做实验:
create table t9(id int primary key,b int,key(b));
insert into t9 values(2,98),(5,100),(6,100),(8,105),(7,96),(11,98),(13,99);
表中数据:

在一个会话中开启事务:
BEGIN;
SELECT * FROM t9 WHERE b= 99 FOR UPDATE;
另一个会话:
BEGIN; #rollback
INSERT INTO t9 VALUES(11,100);
报错:
Error Code: 1062
Duplicate entry '11' for key 'PRIMARY'
而:
BEGIN; #rollback
INSERT INTO t9 VALUES(13,100);会被阻塞。
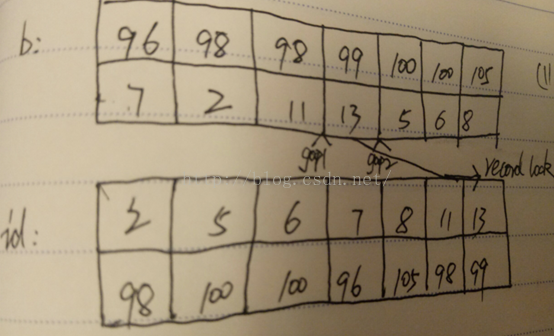
加锁范围是:
1):对gap1,gap2加间隙锁
gap1范围:
注意:gap1不是只包括(12,98), (12,99)。b=98时,id范围是(11,无穷大)。因为该索引是按照b列排序的,不是按照id排序。
如:插入这几个值时(12,98),(12,99),(25,98),(1000,98)会被阻塞。
b=99时,id范围是[0,12]。但是我发现,当插入id=已存在的主键值的记录时,如:(2,99),(5,99),(6,99),(7,99),(8,99),(11,99)不会被阻塞,会报错误:Duplicate entry '11' for key 'PRIMARY'。
gap2范围:
b=99时,id范围为(13,无穷大)
b=100是,id范围为[0,4]。如:(0,100),(1,100),(2,100),(3,100),(4,100)。
但是(2,100)没有被阻塞,而是报了错误:Duplicate entry '2' for key 'PRIMARY',因为有条记录id=2
2):对主键id=13的记录加个recordlock。
如:(13,100)会被阻塞。
--本篇文章转自:http://www.2cto.com/database/201410/343841.html,并增添了些许内容。














 1382
1382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









