









并行程序设计探讨(1)——并行系统
大家可能会有疑问:你一会儿并行,一会儿多核,到底是谁跟谁啊?
我开始也有这个疑问,甚至以为并行就是多核,其实两个并不能对等,一句话就是:多核是并行的一种。
并行本身是一个广泛的概念,其实早在多核之前并行处理就已经存在N久了,大家想想看:IBM、SUN、HP的小型机,哪个不是多CPU的?甚至连DELL的工作站,都是两CPU的,更不用说那些中型机、大型机、巨型机了。所以说“并行处理”是一个比“多核处理”要广泛、要早的多的技术,多核只是在PC领域实现了并行处理而已(当然,如果再把多核CPU放到以前的多CPU系统中,那自然系统就更加强大了)。
言归正传,我们还是看看大师们是怎么划分这个并行系统的。
1 费林分类Flynn's Taxonomy
费林分类法(Flynn's Taxonomy),是一种高效能计算机的分类方式。1972年费林(Michael J. Flynn)根据资讯流(information stream)可分成指令(Instruction)和资料(Data)两种。据此又可分成四种计算机类型:SISD, SIMD, MISD, and MIMD.
注意:费林分类是划分计算机的,不是划分CPU的。
1.1 SISD (Single Instruction Single Data)
单处理指令单数据,一条指令处理一个数据,所有的冯诺依曼体系结构的“单处理器计算机”都是这类,基本上07年前的PC都是这类。
1.2 SIMD (Single Instruction Multiple Data)
单指令多数据,一个指令广播到多个处理器上,但每个处理器都有自己的数据。
这种系统主要应用在“专有应用”系统上,例如数字信号处理、向量运算处理,其并行功能一般都是由编译器完成的。
1.3 MISD (Multiple Instruction Single Data)
多指令单数据,没有系统按照这个结构设计,这种类别仅仅是为了分类完整而提出来的。
1.4 MIMD (Multiple Instruction Multiple Data)
多指令多数据,每个处理单元有独立指令和数据。
这是并行处理系统中最常见的结构,现代流行的并行处理结构都可以划入这一类。

2 MIMD详细分类
大家可能会有疑问:前面不是已经分类了么?为什么还要单独拿出来将MIMD又分一下呢?
既然是单独拿出来,要么就是原来的分类不够细,要么就是很重要,要单独进行说明,而这两个理由在将MIMD分类时都有:一是MIMD确实太粗了,在实际应用中不会直接说某某系统是一个MIMD系统;二是MIMD是目前并行处理系统中最常见、使用最广泛的系统。
费林分类的标准是指令和数据,那么MIMD的分类标准又是什么呢?CPU、内存、总线、还是其它?
MIMD的分类标准是“内存结构”,也就是内存是如何组织的,而内存结构又可以简单的分为两大类:共享内存和消息驱动。顾名思义,共享内存就是处理器之间共享内存,通过共享内存进行通信;消息驱动就是处理器之间不共享内存,靠消息驱动来进行通信s。
根据这个原则,一般分为如下几种:
共享内存:SMP,NUMA
消息驱动:DMA。
2.1 SMP(symmetric multiprocessors)对称多处理机
所有CPU都共享同一内存。
SMP又叫UMA(uniform memory access),至于为什么叫这个,看完下面的NUMA你就会知道了。
所以按照SMP的定义,目前Intel和AMD推出的多核CPU应该划归到SMP这一类。

2.2 NUMA (nonuniform memory access) 非一致内存访问
所有CPU共享所有的内存,但不同的CPU访问不同的内存时速度不一样。
中文翻译为“非一致内存访问”,我感觉很拗口,还不如直接翻译成“牛马”, 牛马本来就不是一个东东,而且正好牛和马一快一慢:)。
下面的图是从《并行程序设计模式》中摘出来的,图画的有点误导人,从图中来看好像是内存之间进行了连接,实际上内存之间是没有连接的,CPU访问离自己近的内存是通过本地s直接访问的(像马一样快),访问离自己远的内存是通过总线访问(像牛一样慢)的,因此很明显两者速度差别很大,这也是之所以叫做nonuniform的原因。
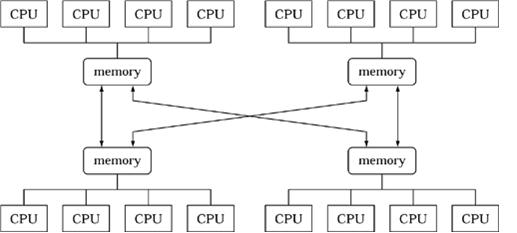
与NUMA类似的还有一个ccNUMA,前缀cc是cache-coherent(一致性高速缓存)的缩写。 为什么会冒出这样一个系统呢?其实就是为了解决nonuniform的问题,即:解决访问不同内存速度不一样的问题。
2.3 DM (Distributed memory)分布式内存
每个CPU都有自己的内存,CPU之间通过消息来通信。
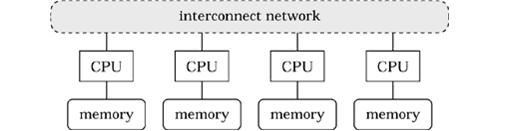
根据interconnect network的不同,DM又分为两种:MPP、Cluster、Grid。三者的差别简单的来说就是:MPP是一台机器,Cluster是一群类似的机器,Grid是一堆任意的机器。
2.3.1 MPP (massively parallel processors) 大规模并行处理系统
这样的系统是由许多松耦合的处理单元组成的,要注意的是这里指的是处理单元而不是处理器。每个单元内的CPU都有自己私有的资源,如总线,内存,硬盘等。在每个单元内都有操作系统和管理数据库的实例复本。这种结构最大的特点在于不共享资源。

2.3.2 Cluster集群
集群应该是大家最常见的,就是一堆相同或者类似的机器通过网络连起来组成一个计算机群,相互之间通过网络进行通信。
2.3.3 Grid网格系统
网格系统其实和集群差不多,都是一堆机器通过网络连接起来,但两者还是不同的东西:
1)集群中机器都是同质的,所谓“物以群分”;而网格中是异质的,可能一个大型机、一台PC机、一台手机都是网格系统中的一个机器;
2)集群中的机器都是属于某一个实体的,需要“集中管理”,例如一个公司、一个组织、一个人;而网格中的机器属于不同的实体的,只需要“分散管理”即可,甚至大家都不知道有哪些机器在这个网格中。
3)大部分情况下,集群是通过局域网进行连接,网格是通过互联网连接。s
仔细数了数,和并行系统相关的名词就有10个了,本文知识提纲挈领的将这些并行系统介绍了一下,详细的研究还需要各位根据自己的情况亲自完成了。
==========================未完待续===============================

















 2135
2135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









