









本篇介绍Kmeans算法中计算新的聚类中心部分。这部分主要逻辑:根据计算出的新的分类信息,对全部数据点依次对每个类别求出所属当前类别的数据点个数与坐标和。本质上就是进行规约运算。
V1 Atomic实现全局规约
由于最终生成16个聚类中心,因此这里的规约操作需要针对算法进行一定的调整。V1在实现逻辑为:先在共享内存上分别通过原子操作,对16个类进行规约,再通过原子操作进行设备内存的全局规约操作。
/*V1 atomic规约*/
__global__ void kKmeansSumAtomic(int SrcCount,
int Coords/*[1]*/,
int ClusterCount/*[16]*/,
float* d_pSrc, /*[Coords][SrcCount]*/
int* d_pMembership,/*[SrcCount]*/
float* d_pDst,/*[ClusterCount][Coords]*/
int* d_pMemberCount/*[ClusterCount]*/
)
{
//TODO:local reduce cluster result in share memory
extern __shared__ float sm[];/*[Coords][blockDim.x] + [ClusterCount][Coords] + [ClusterCount]*/
for (size_t i = threadIdx.x; i < Coords * blockDim.x + ClusterCount * Coords + ClusterCount; i += blockDim.x)
{
sm[i] = 0.0f;
}
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int* pClusterCount/*[ClusterCount]*/ = (int*)(sm + blockDim.x * Coords + ClusterCount * Coords);
float* pPointsReduce/*[ClusterCount][Coords]*/ = (float*)(sm + blockDim.x * Coords);
int CurCluster = d_pMembership[tid];
for (size_t iCoord = 0; iCoord < Coords; iCoord++)
{
sm[threadIdx.x + iCoord * blockDim.x] = d_pSrc[tid + iCoord * SrcCount];
}
//Reduce count info
atomicAdd(pClusterCount + CurCluster, 1);
__syncthreads();
if (threadIdx.x < ClusterCount)
{
atomicAdd(d_pMemberCount + threadIdx.x, pClusterCount[threadIdx.x]);
}
//Reduce points info
for (size_t iCoord = 0; iCoord < Coords; iCoord++)
{
atomicAdd(pPointsReduce + CurCluster * Coords + iCoord, sm[iCoord * blockDim.x + threadIdx.x]);
}
__syncthreads();
if (threadIdx.x < ClusterCount)
{
for (size_t iCoord = 0; iCoord < Coords; iCoord++)
{
atomicAdd(d_pDst + threadIdx.x * Coords + iCoord, pPointsReduce[threadIdx.x * Coords + iCoord]);
}
}
}
执行情况如下

此时耗时1720us

block 1024 grid 1024
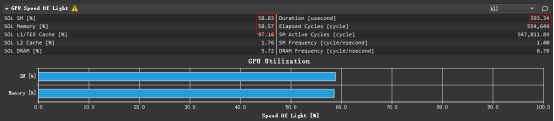
调整执行配置后运行时间393us

grid 8192 block 128
由于原子操作串行执行,因此整个规约计算全部通过原子操作并不是一个很好的选择。这里仅作为一种实现的思路。
V2 分类归约
主要思路:依次按照所属类别中心,在共享内存中对其分别进行归约,最终将每个block的归约的结果通过原子操作更新至设备内存中。
/*V2 分类归约*/
__global__ void kKmeansSum(int SrcCount,
int Coords,
int ClusterCount,
float* d_pSrc, /*[Coords][SrcCount]*/
int* d_pMembership,/*[SrcCount]*/
float* d_pDst,/*[ClusterCount][Coords]*/
int* d_pMemberCount/*[ClusterCount]*/
)
{
//TODO:local reduce cluster result in share memory
extern __shared__ float sm[];/*[Coords][blockDim.x] + [blockDim.x]*/
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int* pClusterCount = (int*)(sm + blockDim.x * kCoords);
int RealCluster = d_pMembership[tid];
//TODO:sum each cluster
for (int itcluster = 0; itcluster < ClusterCount; itcluster++)
{
//TODO:load
bool bCurCluster = (RealCluster == itcluster);
pClusterCount[threadIdx.x] = bCurCluster ? 1 : 0;
for (size_t idim = 0; idim < Coords; idim++)
{
sm[threadIdx.x + idim * blockDim.x] = bCurCluster ? d_pSrc[idim * SrcCount + tid] : 0.0f;
}
//__syncthreads();/*stall barrier 原因*/
//TODO:reduce
for (int step = (blockDim.x >> 1); step > 0; step = (step >> 1))
{
__syncthreads();
if (threadIdx.x < step)
{
pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + step];
for (size_t idim = 0; idim < Coords; idim++)
{
sm[threadIdx.x + idim * blockDim.x] += sm[threadIdx.x + step + idim * blockDim.x];
}
}
}
if (0 == threadIdx.x)
{
atomicAdd(d_pMemberCount + itcluster, pClusterCount[0]);
for (size_t idim = 0; idim < Coords; idim++)
{
atomicAdd((d_pDst + itcluster * Coords + idim), sm[idim * blockDim.x]);
}
}
}
}
执行情况如下

耗时850us。

block128 grid 8192.
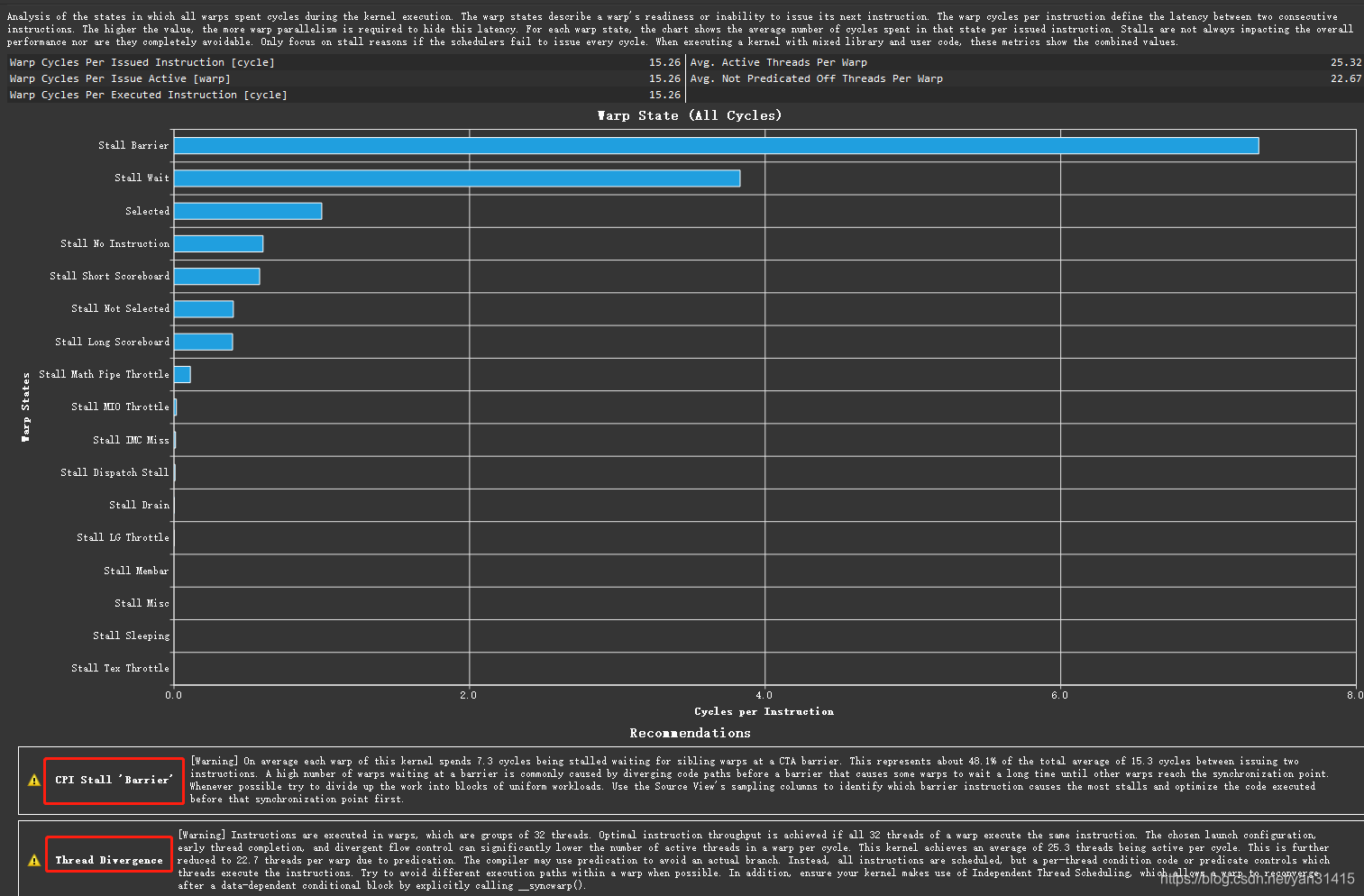
其中性能问题是由block内同步导致的,对应代码位置如下:
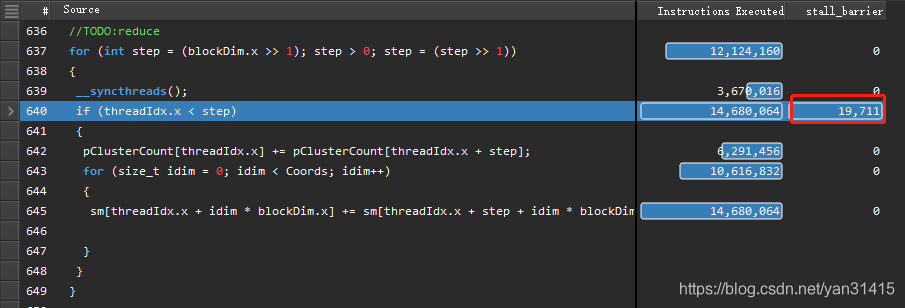
V3 减少block内同步
不同的工作线程处理数据时,由于程逻辑上存在依赖关系,因此block内同步函数__syncthreads()不能省略。但是当归约尺寸小于一个warp的尺寸32时,情况就发生变化了,由于warp SIMT的执行机制,可以消除同步。这里是通过shf指令,通过每个线程的寄存器交换数据。
/*V3 一个warp内归约,通过shf指令交换数据+坐标维度展开*/
template<int COORDS>
__global__ void kKmeansSumCutSync(int SrcCount,
int Coords/*[1]*/,
int ClusterCount/*[16]*/,
float* d_pSrc, /*[Coords][SrcCount]*/
int* d_pMembership,/*[SrcCount]*/
float* d_pDst,/*[ClusterCount][Coords]*/
int* d_pMemberCount/*[ClusterCount]*/
)
{
extern __shared__ float sm[];/*[Coords][blockDim.x] + [blockDim.x]*/
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int* pClusterCount = (int*)(sm + blockDim.x * COORDS);
int RealCluster = d_pMembership[tid];
//TODO:sum each cluster
for (int itcluster = 0; itcluster < ClusterCount; itcluster++)
{
//TODO:load
bool bCurCluster = (RealCluster == itcluster);
pClusterCount[threadIdx.x] = bCurCluster ? 1 : 0;
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
sm[threadIdx.x + idim * blockDim.x] = bCurCluster ? d_pSrc[idim * SrcCount + tid] : 0.0f;
}
//__syncthreads();/*stall barrier 原因*/
//TODO:reduce
int step;
for (step = (blockDim.x >> 1); step > 16; step = (step >> 1))
{
__syncthreads();
if (threadIdx.x < step)
{
pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + step];
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
sm[threadIdx.x + idim * blockDim.x] += sm[threadIdx.x + step + idim * blockDim.x];
}
}
}
//TODO:reduce warp
if (threadIdx.x < kWarpSize)
{
int LocalClusterCount = pClusterCount[threadIdx.x];
float LocalPoints[kCoords];
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalPoints[i] = sm[threadIdx.x + i * blockDim.x];
}
for (; step > 0; step = (step >> 1))
{
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, step, 32);
LocalPoints[0] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[0], step, 32);
}
if (0 == threadIdx.x)
{
atomicAdd(d_pMemberCount + itcluster, LocalClusterCount);
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
atomicAdd((d_pDst + itcluster * Coords + idim), LocalPoints[idim]);
}
}
}
}
}
执行情况如下
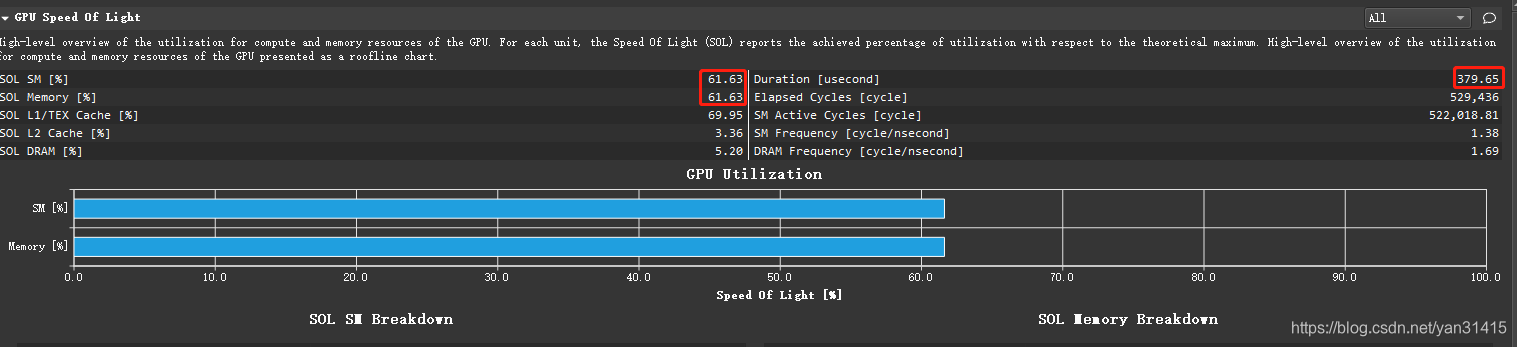
耗时379us,其中内存和计算超过峰值的60%。
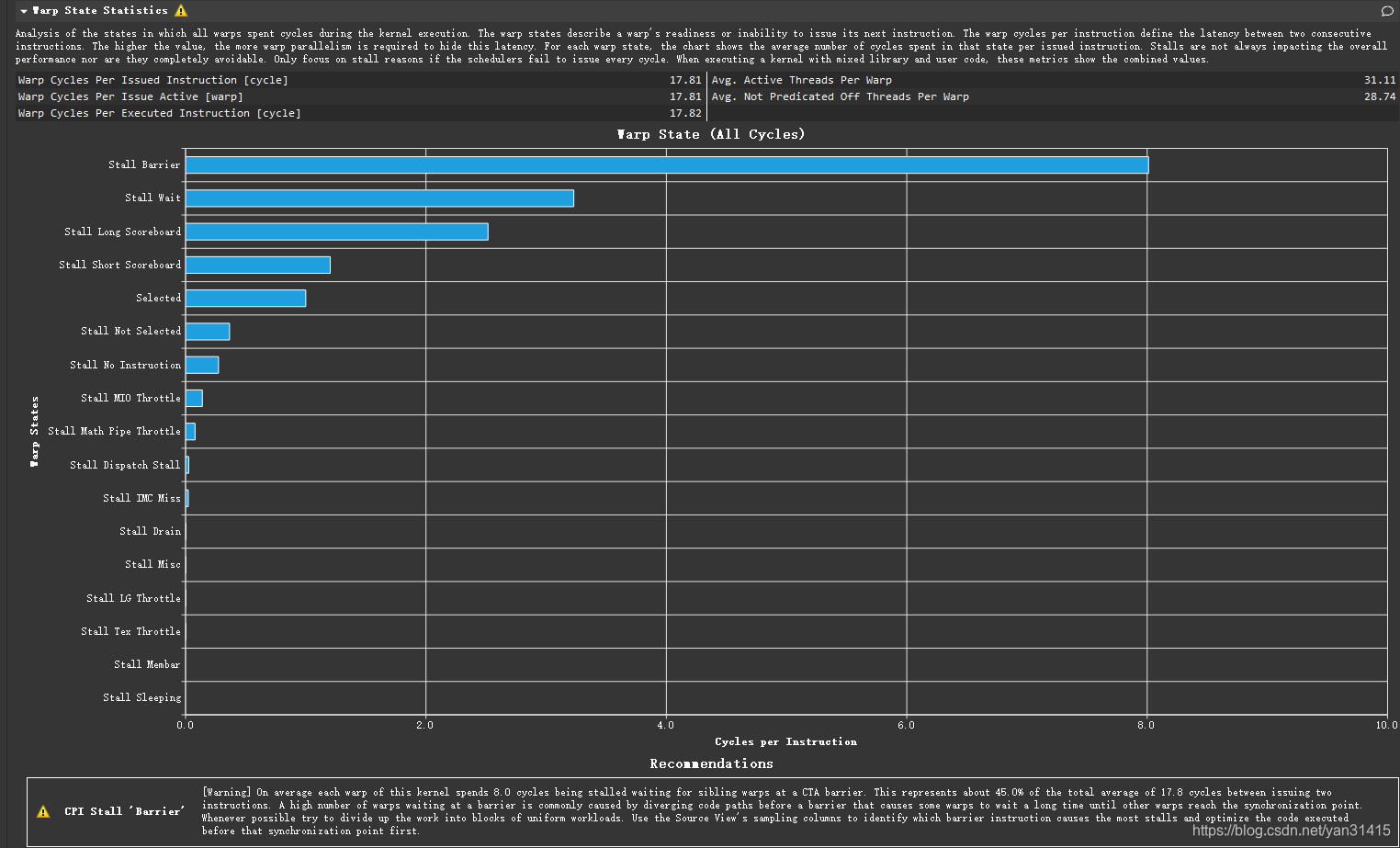
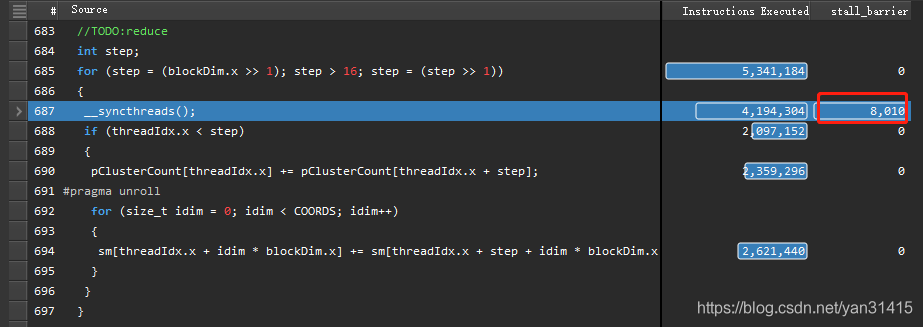
这里总的stall_barrier相对上一个版本减少,但是执行的总的指令数量也相应减少,因此相对的总体指标反而升高了。
V4 进一步展开
在block大小这里通过编译器展开。
/*V4 blockdim展开*/
template<int COORDS,int BLOCKISZE>
__global__ void kKmeansSumUnroll(int SrcCount,
int Coords/*[1]*/,
int ClusterCount/*[16]*/,
float* d_pSrc, /*[Coords][SrcCount]*/
int* d_pMembership,/*[SrcCount]*/
float* d_pDst,/*[ClusterCount][Coords]*/
int* d_pMemberCount/*[ClusterCount]*/
)
{
extern __shared__ float sm[];/*[Coords][blockDim.x] + [blockDim.x]*/
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int* pClusterCount = (int*)(sm + BLOCKISZE * COORDS);
int RealCluster = d_pMembership[tid];
//TODO:sum each cluster
for (int itcluster = 0; itcluster < ClusterCount; itcluster++)
{
//TODO:load
bool bCurCluster = (RealCluster == itcluster);
pClusterCount[threadIdx.x] = bCurCluster ? 1 : 0;
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
sm[threadIdx.x + idim * blockDim.x] = bCurCluster ? d_pSrc[idim * SrcCount + tid] : 0.0f;
}
//__syncthreads();/*stall barrier 原因*/
//TODO:reduce
int step;
#pragma unroll
for (step = (BLOCKISZE >> 1); step > 16; step = (step >> 1))
{
__syncthreads();
if (threadIdx.x < step)
{
pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + step];
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
sm[threadIdx.x + idim * blockDim.x] += sm[threadIdx.x + step + idim * blockDim.x];
}
}
}
//TODO:reduce warp
if (threadIdx.x < kWarpSize)
{
int LocalClusterCount = pClusterCount[threadIdx.x];
float LocalPoints[kCoords];
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalPoints[i] = sm[threadIdx.x + i * blockDim.x];
}
#pragma unroll
for (; step > 0; step = (step >> 1))
{
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, step, 32);
LocalPoints[0] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[0], step, 32);
}
if (0 == threadIdx.x)
{
atomicAdd(d_pMemberCount + itcluster, LocalClusterCount);
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
atomicAdd((d_pDst + itcluster * Coords + idim), LocalPoints[idim]);
}
}
}
}
}
虽然占用率提升不少,但执行速度并没有快多少363us
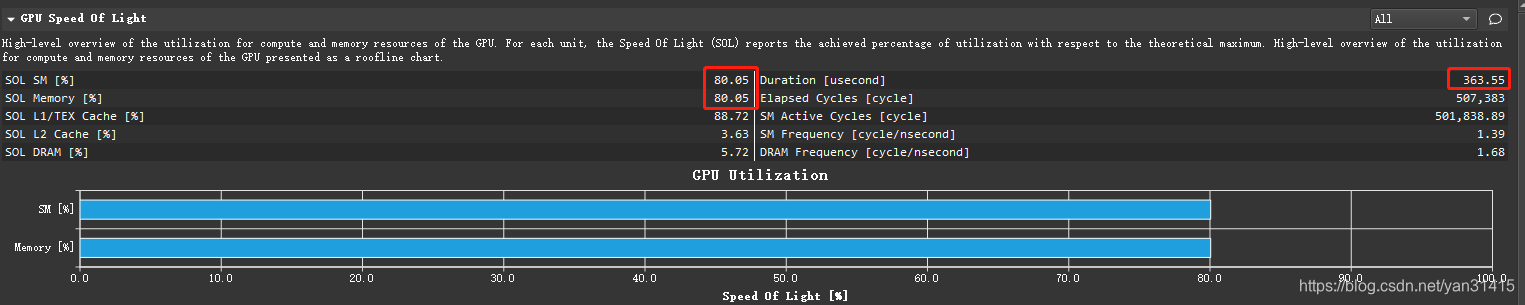
V5 增加负载
基于V5,加载内存部分进行16倍展开
template<int BLOCKSIZE,int UNROLL,int COORDS>
__global__ void kkKmeansUnrollAdv(int SrcCount,
int Coords,
int ClusterCount,
float* d_pSrc, /*[Coords][SrcCount]*/
int* d_pMembership,/*[SrcCount]*/
float* d_pDst,/*[ClusterCount][Coords]*/
int* d_pMemberCount/*[ClusterCount]*/
)
{
extern __shared__ float sm[];/*[Coords][blockDim.x] + [blockDim.x]*/
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int* pClusterCount = (int*)(sm + blockDim.x * COORDS);
//int RealCluster = d_pMembership[tid];
//TODO:sum each cluster
for (int itcluster = 0; itcluster < ClusterCount; itcluster++)
{
//TODO:load
bool bCurCluster;
pClusterCount[threadIdx.x] = 0;
sm[threadIdx.x] = 0.0f;
#pragma unroll
for (size_t i = 0; i < UNROLL; i++)
{
bCurCluster = (d_pMembership[tid + (i * SrcCount / UNROLL)] == itcluster);
pClusterCount[threadIdx.x] += bCurCluster ? 1 : 0;
sm[threadIdx.x] += bCurCluster ? d_pSrc[tid + (i * SrcCount / UNROLL)] : 0.0f;
}
//__syncthreads();
TODO:reduce
//if ((BLOCKSIZE >= 256) && threadIdx.x < 128)
//{
// sm[threadIdx.x] += sm[threadIdx.x + 128];
// pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + 128];
//}
__syncthreads();
if ((BLOCKSIZE >= 128) && threadIdx.x < 64)
{
sm[threadIdx.x] += sm[threadIdx.x + 64];
pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + 64];
}
__syncthreads();
if ((BLOCKSIZE >= 64) && threadIdx.x < 32)
{
sm[threadIdx.x] += sm[threadIdx.x + 32];
pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + 32];
}
__syncthreads();
//TODO:reduce warp
if (threadIdx.x < kWarpSize)
{
int LocalClusterCount = pClusterCount[threadIdx.x];
float LocalPoints[COORDS];
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalPoints[i] = sm[threadIdx.x + i * blockDim.x];
}
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 16, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 8, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 4, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 2, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 1, 32);
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 16, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 8, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 4, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 2, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 1, 32);
}
if (0 == threadIdx.x)
{
atomicAdd(d_pMemberCount + itcluster, LocalClusterCount);
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
atomicAdd((d_pDst + itcluster * Coords + idim), LocalPoints[idim]);
}
}
}
}
}
执行情况


耗时179us
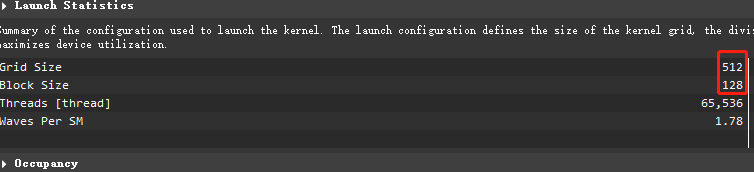
block 128 grid 1024
当前的主要性能问题为 Stall MIO Throttle
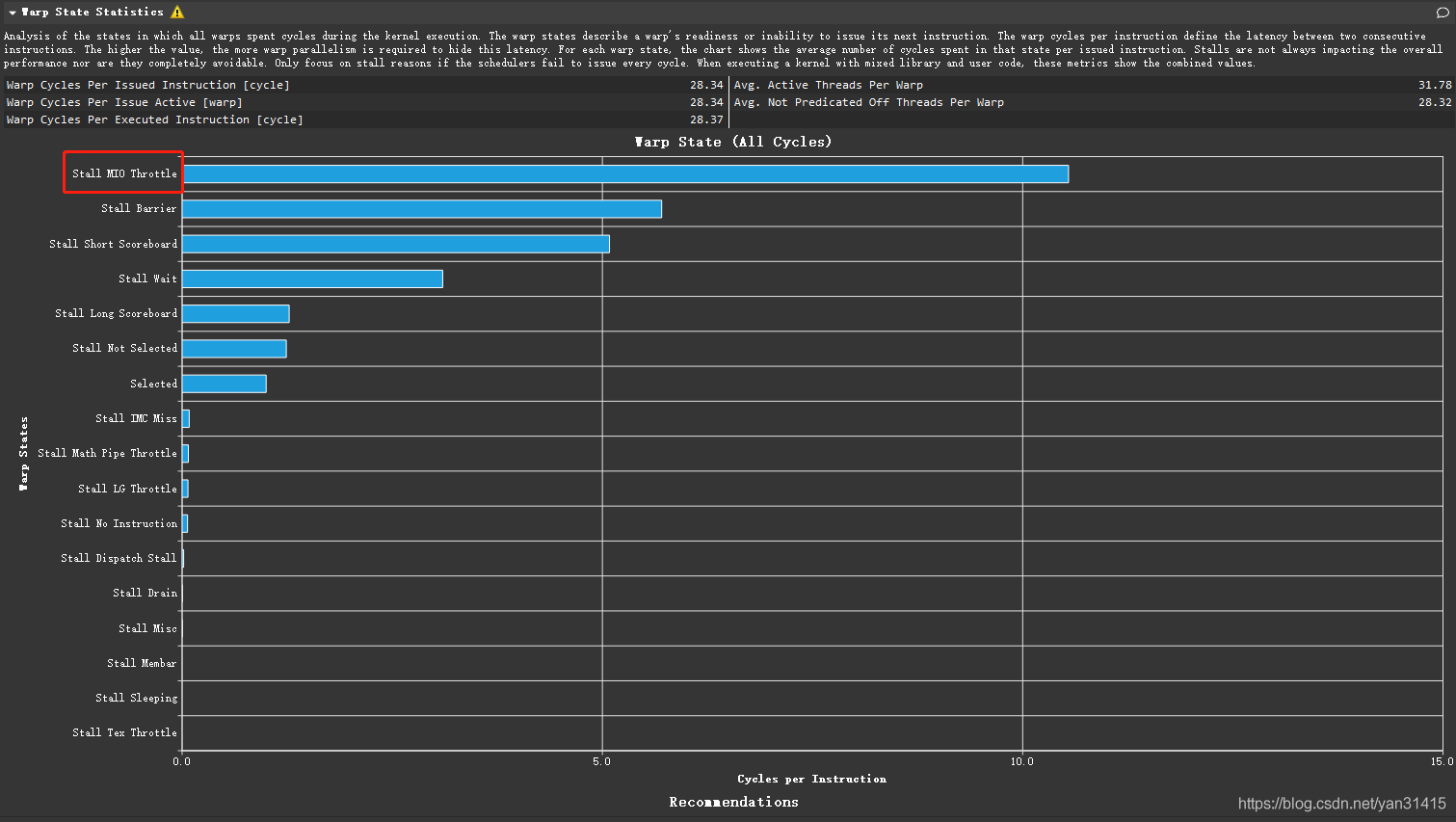
代码位置
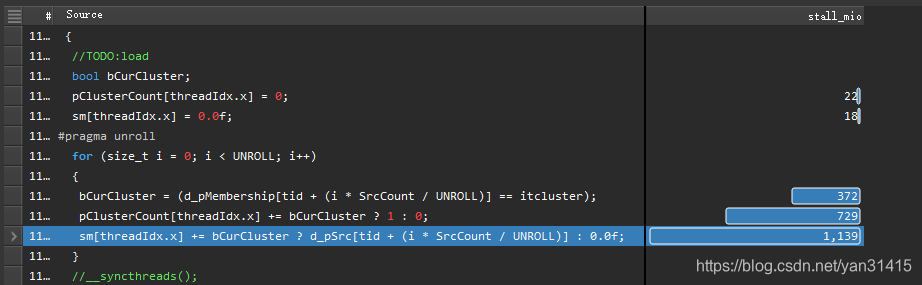
这里由于频繁访问共享内存导致性能瓶颈。
V6 寄存器中实现16倍的展开操作
如题,代码实现如下
template<int BLOCKSIZE, int UNROLL, int COORDS>
__global__ void kkKmeansUnrollAdvopt(int SrcCount,
int Coords,
int ClusterCount,
float* d_pSrc, /*[Coords][SrcCount]*/
int* d_pMembership,/*[SrcCount]*/
float* d_pDst,/*[ClusterCount][Coords]*/
int* d_pMemberCount/*[ClusterCount]*/
)
{
extern __shared__ float sm[];/*[Coords][blockDim.x] + [blockDim.x]*/
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int* pClusterCount = (int*)(sm + blockDim.x * COORDS);
int LocalCount = 0;
float LocalClusters[COORDS];
//int RealCluster = d_pMembership[tid];
//TODO:sum each cluster
for (int itcluster = 0; itcluster < ClusterCount; itcluster++)
{
//TODO:load
bool bCurCluster;
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalClusters[i] = 0.0f;
}
LocalCount = 0;
pClusterCount[threadIdx.x] = 0;
sm[threadIdx.x] = 0.0f;
#pragma unroll
for (size_t i = 0; i < UNROLL; i++)
{
bCurCluster = (d_pMembership[tid + (i * SrcCount / UNROLL)] == itcluster);
LocalCount += bCurCluster ? 1 : 0;
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
LocalClusters[idim] += bCurCluster ? d_pSrc[tid + (i * SrcCount / UNROLL)] : 0.0f;
}
}
pClusterCount[threadIdx.x] = LocalCount;
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
sm[threadIdx.x] = LocalClusters[idim];
}
__syncthreads();
if ((BLOCKSIZE >= 128) && threadIdx.x < 64)
{
sm[threadIdx.x] += sm[threadIdx.x + 64];
pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + 64];
}
__syncthreads();
if ((BLOCKSIZE >= 64) && threadIdx.x < 32)
{
sm[threadIdx.x] += sm[threadIdx.x + 32];
pClusterCount[threadIdx.x] += pClusterCount[threadIdx.x + 32];
}
__syncthreads();
//TODO:reduce warp
if (threadIdx.x < kWarpSize)
{
int LocalClusterCount = pClusterCount[threadIdx.x];
float LocalPoints[COORDS];
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalPoints[i] = sm[threadIdx.x + i * blockDim.x];
}
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 16, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 8, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 4, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 2, 32);
LocalClusterCount += __shfl_down_sync(0xFFFFFFFF, LocalClusterCount, 1, 32);
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 16, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 8, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 4, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 2, 32);
LocalPoints[i] += __shfl_down_sync(0xFFFFFFFF, LocalPoints[i], 1, 32);
}
if (0 == threadIdx.x)
{
atomicAdd(d_pMemberCount + itcluster, LocalClusterCount);
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
atomicAdd((d_pDst + itcluster * Coords + idim), LocalPoints[idim]);
}
}
}
}
}
执行情况如下
V7 寄存器版本2
进一步减少共享内存的访问。
/*V6 寄存器进行归约*/
template<int BLOCKSIZE, int UNROLL, int COORDS>
__global__ void kkKmeansReg(int SrcCount,
int Coords,
int ClusterCount,
float* d_pSrc, /*[Coords][SrcCount]*/
int* d_pMembership,/*[SrcCount]*/
float* d_pDst,/*[ClusterCount][Coords]*/
int* d_pMemberCount/*[ClusterCount]*/
)
{
extern __shared__ float sm[];/*[blockDim.x/kWarpSize] + [blockDim.x/kWarpSize*COORDS]*/
float* smLCluster = (float*)(sm +( BLOCKSIZE >> 5));
int* smClusterCount = (int*)sm;
int LocalClusCount = 0;
float LocalClus[COORDS];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
//TODO:sum each cluster
#pragma unroll
for (int itcluster = 0; itcluster < ClusterCount; itcluster++)
{
//TODO:load
bool bCurCluster;
LocalClusCount = 0;
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalClus[i] = 0.0f;
}
#pragma unroll
for (size_t unroll = 0; unroll < UNROLL; unroll++)
{
bCurCluster = (d_pMembership[tid + (unroll * SrcCount / UNROLL)] == itcluster);
LocalClusCount += bCurCluster ? 1 : 0;
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
LocalClus[idim] += bCurCluster ? d_pSrc[tid * COORDS + idim + (unroll * SrcCount / UNROLL)] : 0.0f;
}
}
__syncthreads();
LocalClusCount += __shfl_down_sync(0xFFFFFFFF, LocalClusCount, 16, 32);
LocalClusCount += __shfl_down_sync(0xFFFFFFFF, LocalClusCount, 8, 32);
LocalClusCount += __shfl_down_sync(0xFFFFFFFF, LocalClusCount, 4, 32);
LocalClusCount += __shfl_down_sync(0xFFFFFFFF, LocalClusCount, 2, 32);
LocalClusCount += __shfl_down_sync(0xFFFFFFFF, LocalClusCount, 1, 32);
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
LocalClus[i] += __shfl_down_sync(0xFFFFFFFF, LocalClus[i], 16, 32);
LocalClus[i] += __shfl_down_sync(0xFFFFFFFF, LocalClus[i], 8, 32);
LocalClus[i] += __shfl_down_sync(0xFFFFFFFF, LocalClus[i], 4, 32);
LocalClus[i] += __shfl_down_sync(0xFFFFFFFF, LocalClus[i], 2, 32);
LocalClus[i] += __shfl_down_sync(0xFFFFFFFF, LocalClus[i], 1, 32);
}
__syncthreads();
if ((threadIdx.x & 0x1F) == 0 )
{
smClusterCount[threadIdx.x >> 5] = LocalClusCount;
#pragma unroll
for (size_t i = 0; i < COORDS; i++)
{
smLCluster[(threadIdx.x >> 5) * COORDS + i] = LocalClus[i];
}
}
__syncthreads();
//TODO:reduce warp
{
if (0 == threadIdx.x)
{
#pragma unroll
for (size_t i = 1; i < (BLOCKSIZE>>5); i++)
{
LocalClusCount += smClusterCount[i];
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
LocalClus[idim] += smLCluster[i * COORDS + idim];
}
}
atomicAdd(d_pMemberCount + itcluster, LocalClusCount);
#pragma unroll
for (size_t idim = 0; idim < COORDS; idim++)
{
atomicAdd((d_pDst + itcluster * Coords + idim), LocalClus[idim]);
}
}
}
}
}
执行情况

SM和内存使用率为70%左右

执行时间下降到86us
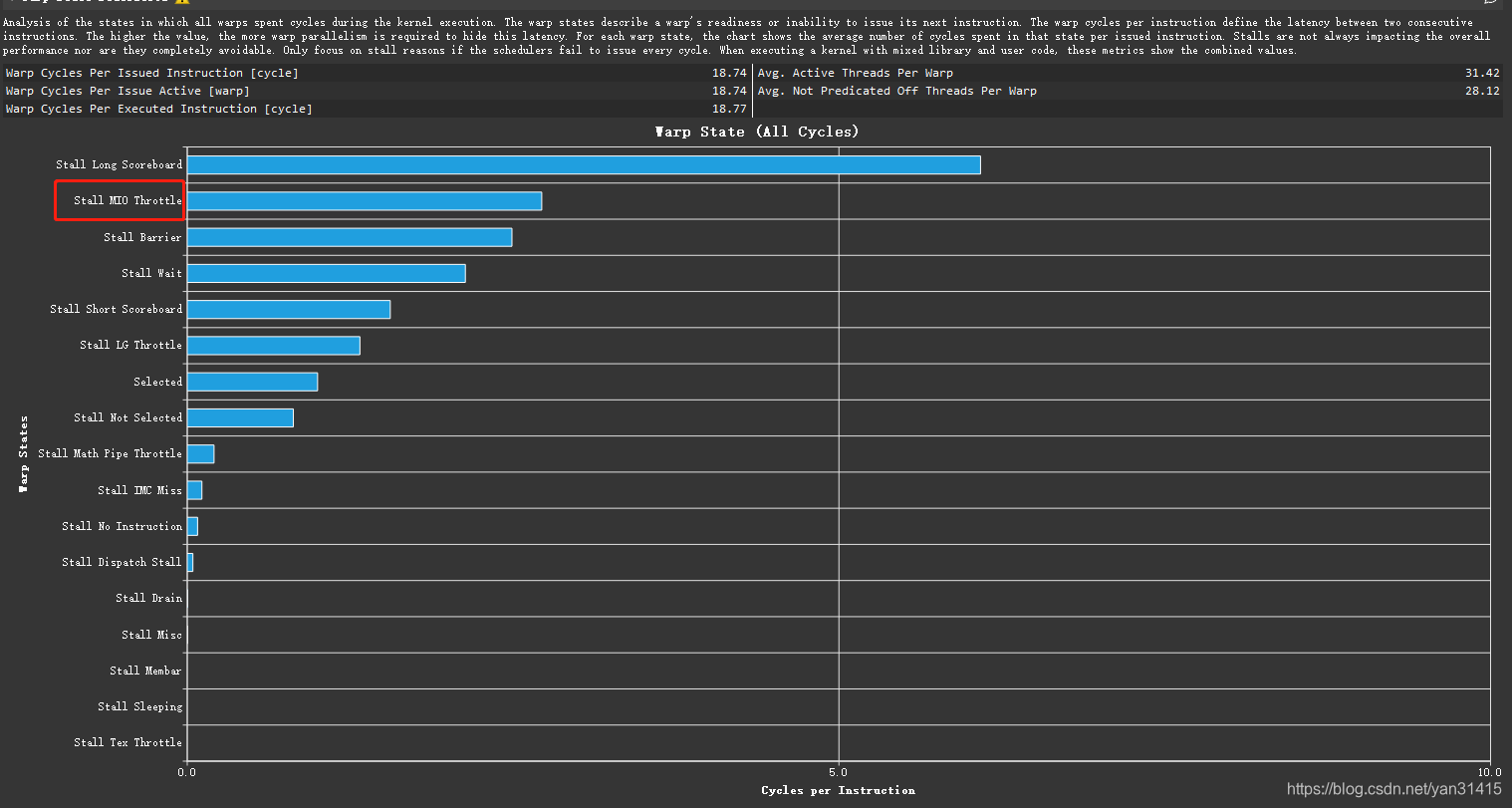
Stall MIO Throttle指标得到改善。
总结
本篇基于CUDA实现了Kmeans算法的归约计算部分,通过6个版本的迭代,执行速度从17200us下降到86us,得到约20倍的加速比。














 1695
1695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









