







背景
小王是一家著名高尔夫俱乐部的经理。但是他被雇员数量问题搞得心情十分不好。某些天好像所有人都來玩高尔夫,以至于所有员工都忙的团团转还是应付不过来,而有些天不知道什么原因却一个人也不来,俱乐部为雇员数量浪费了不少资金。
小王的目的是通过下周天气预报寻找什么时候人们会打高尔夫,以适时调整雇员数量。因此首先他必须了解人们决定是否打球的原因。
在2周时间内我们得到以下记录:
天气状况有晴,云和雨;气温用华氏温度表示;相对湿度用百分比;还有有无风。当然还有顾客是不是在这些日子光顾俱乐部。最终他得到了14列5行的数据表格
操作
py -V
python -m pip install --upgrade pip
pip3 install sklearnexample1.csv
NO,OUTLOOK,TEMPERATURE,HUMIDITY,WINDY,PLAY
1,sunny,85,85,FALSE,n
2,sunny,80,90,TRUE,n
3,overcast,83,78,FALSE,y
4,rain,70,96,FALSE,y
5,rain,68,80,FALSE,y
6,rain,65,70,TRUE,n
7,overcast,64,65,TRUE,y
8,sunny,72,95,FALSE,n
9,sunny,69,70,FALSE,y
10,rain,75,80,FALSE,y
11,sunny,75,70,TRUE,y
12,overcast,72,90,TRUE,y
13,overcast,81,75,FALSE,y
14,rain,71,80,TRUE,n
test.py
from sklearn.feature_extraction import DictVectorizer #将dict类型的list数据,转换成numpy array
import csv #读取CSV文件
from sklearn import tree #导入决策树算法
from sklearn import preprocessing #数据预处理
alldata=open(r'D:\work\example1.csv','r',encoding='utf-8') # 读入数据
reader=csv.reader(alldata) #用reader来代表所有数据
headers=next(reader) #header是指数据的第一行,就是数据的特征
print(headers) #因为SK包的数据输入是有一定的要求的,他的输入不能是类别。只能是 0,1。所以要先将数据转化成DICT类型
label=[] #定义一个存放标签的列表
#然后用DictVextorizer的函数进行转换
feature=[] #定义一个存放特征的列表
for row in reader: #以行遍历所有数据
label.append(row[-1]) #取出最后一个值,这个值是每条数据的标签
rowDict={} #定义一个字典类型
for i in range(1,len(row)-1 ):
if row[i].isdigit() and i>1:#对那些连续的属性值做一个简单的离散化
row[i]= int(int(row[i])/10)
rowDict[headers[i]]=row[i] #把每条数据的 特征:属性 插入字典
feature.append(rowDict) #把字典插入列表
print()
print(label)
print()
print(feature)
vec=DictVectorizer() #实例化
dummX=vec.fit_transform(feature).toarray() #使用实例内的方法对数据进行转换
print()
print(vec.get_feature_names())#打印出转换后的数据的表头
print()
print(str(dummX)) #打印出转换后的数据的表值
lb=preprocessing.LabelBinarizer() #实例化
dummY=lb.fit_transform(label) #数据的转换
print(str(dummY))
#上面的过程就是把数据都转换成符合格式的数据了
#可以调用sk包中的决策树算法进行分类
clf=tree.DecisionTreeClassifier(criterion='gini') #使用基尼指数的方法
clf=clf.fit(dummX,dummY) #构建决策树
print("clf: " + str(clf))#打印
#输出到TD3.DOT文件中
with open("d:\\work\\example.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) #要安装可视化工具graphviz
#预测数据
oneRow=dummX[0,:]#取出一条数据进行修改
newRow=oneRow
print(newRow)
oneRow[0]=6
oneRow[2]=1
print(oneRow)
#进行预测
predictY=clf.predict([newRow])
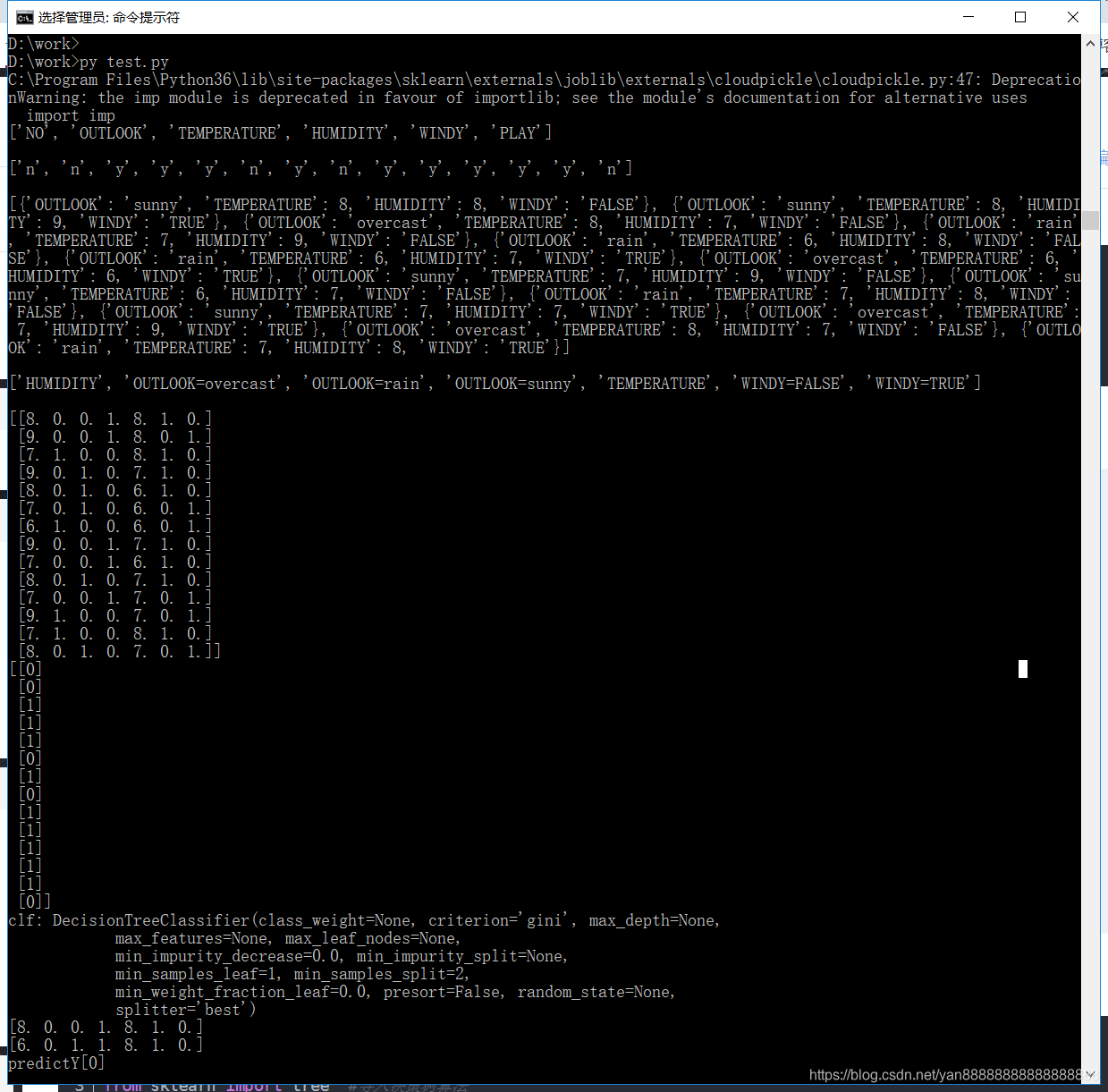
print("predictY"+str(predictY))结果图
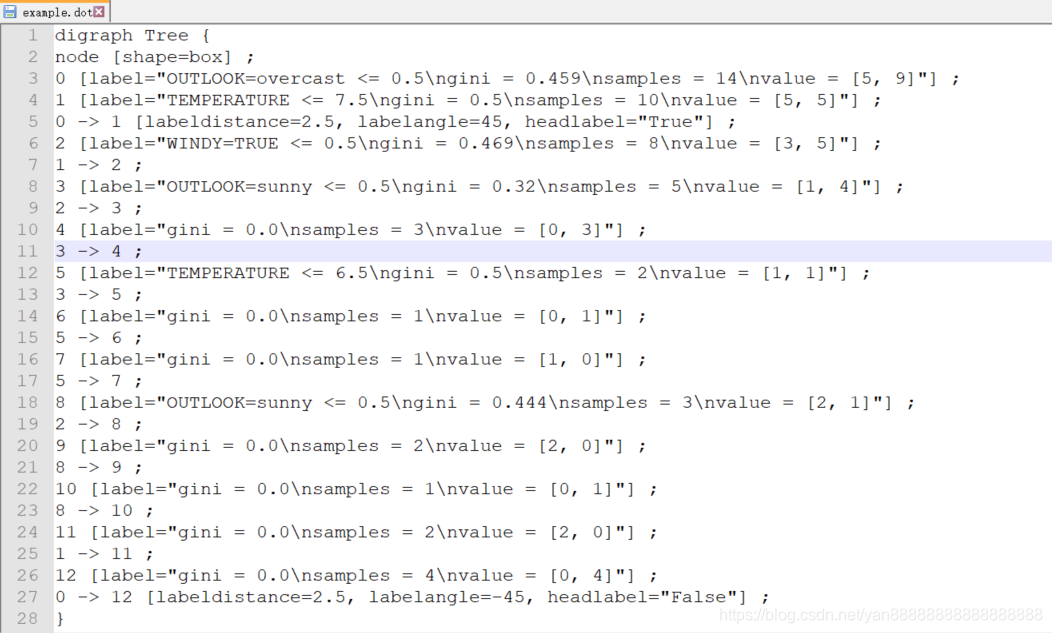
example.dot 文件内容














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









