







比较排序
冒泡排序
冒泡排序是比较排序中最基础的算法,通过和旁边的元素进行比较上浮,从而进行排序。
public static void bubbleSort(int[] a){
for(int i=0;i<a.length;i++)
{
for(int j=a.length-1;j>i;j--)
{
if(a[j] < a[j-1])
exchange(a,j, j-1);
}
}
}
选择排序
选择排序是对冒泡排序进行了优化,没必要每次比较都进行交换引用,去遍历得到最小的元素再来交换引用,这样,效率就提升了很多。
public static void selectSort(int[] a){
int var;
for(int i=0;i<a.length;i++)
{
var = i;
for(int j=i+1;j<a.length;j++)
{
if(a[j] < a[var])
var = j;
}
if(var != i)
exchange(a, i, var);
}
}
插入排序
插入排序也是比较简单的算法,插入排序保证了从0到位置i的元素都为已排状态。
public static void insertSort(int[] a){
int j;
for(int i=1;i<a.length;i++)
{
int tmp = a[i];
for( j = i ; j > 0 && tmp < a[j-1]; j--)
a[j] = a[j-1]; //比tmp大的元素都往右平移一个单位
a[j] = tmp; //最后的位置放入tmp
}
}
希尔排序
希尔排序是冲破二次时间屏障的第一批算法,直到其被发现若干年之后才发现它的亚二次时间界,它是通过比较相距一定间隔的元素来进行排序,直到只比较相邻元素,这也是最后一次比较。当然它的效率和增量(间隔)有着密切的关系,一个流行的选择是使用N/2作为增量的开始。
public static void shellSort(int[] a){
int j;
for(int grap = a.length/2 ; grap > 0 ; grap /=2)
{
for( int i = grap ; i< a.length ; i++)
{
int tmp = a[i];
for(j = i; j >= grap && tmp < a[j-grap]; j-= grap)
a[j] = a[j-grap];
a[j] = tmp;
}
}
}
堆排序
二叉堆是一颗完全填满的二叉树,他的结构性质是从左到右依次排开,可以看到二叉堆完全可以用数组来表示,一个节点的左儿子是2i+1。而让操作快速的执行是它的堆性特质,即最大元在根节点上。
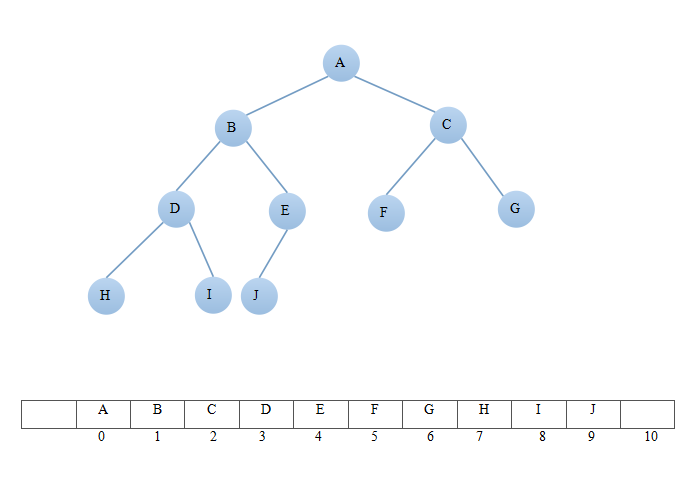
那我们的堆排序,就可以利用二叉堆来实现,首先第一步要做的是建堆,建堆之后,最大元素就是我们的根元素了,然后我们在删除我们的根元素放置数组的最后一位,依次类推,直到剩下最后一个元素。建堆的阶段花费O(N)时间,执行delete阶段花费O(logN),总的时间就花费了O(NlogN)。它给出了我们至今见到的最佳的大O运行时间。
private static int leftChild(int i){
return 2*i + 1;
}
private static void buildHead(int[] a,int i,int n)
{
int child;
int tmp;
for(tmp = a[i];leftChild(i) < n;i = child)
{
child = leftChild(i);
if(child != n-1 && a[child] < a[child + 1])
child ++ ;
if(tmp < a[child])
a[i] = a[child];
else
break;
}
a[i] = tmp;
}
public static void headSort(int[] a){
for(int i= a.length /2 -1 ; i>= 0;i--)
buildHead(a, i, a.length);
for(int i = a.length -1;i>0;i--)
{
exchange(a, 0, i);
buildHead(a, 0, i);
}
}
至于上面为什么是从a.length/2-1开始建堆,因为这个数值就是我们的完全二叉树的深度-1的位置,随着i–,就可以遍历到每个节点,这样就找出我们的最大节点元素。
第一次建堆的过程如下:
i = 2 —> 31,41,97,26,53,58,59
i = 1 —> 31,53,97,26,41,58,59
i = 0 —> 97,53,31,26,41,58,59
说白了,其实建堆的过程就是从每个节点找出最大的元素,第一次建堆就找出了97。当执行第二个for循环的时候,exchange方法会把我们找出的最大元素放到队列的末尾,那么建堆的过程变无法找到我们的97,因为我们的n是a.length-1,就不满足 child != n-1 的条件,依次类推,剩余最大的元素都放到队列的末尾,从而完成排序。
归并排序
归并排序把比较的数组分成已排序的两组,然后通过两组元素一一比较,最小的放到缓存数组中,从而完成排序。那么如何得到已排序的两组序列呢,就用递归到初始情况,每个数组只有一个元素的时候比较,依次回退从而得到排序。
//归并排序
private static void merge(int[] a,int[] tmp,int leftPos,int rightPos,int rightEnd){
int leftEnd = rightPos - 1;
int tmpPos = leftPos;
int numElements = rightEnd - leftPos + 1;
while(leftPos <= leftEnd && rightPos <= rightEnd)
if(a[leftPos] <= a[rightPos])
tmp[tmpPos ++] = a[leftPos ++];
else
tmp[tmpPos ++] = a[rightPos ++];
while(leftPos <= leftEnd)
tmp[tmpPos++] = a[leftPos++];
while(rightPos <= rightEnd)
tmp[tmpPos++] = a[rightPos ++];
for(int i=0;i<numElements;i++,rightEnd--)
a[rightEnd] = tmp[rightEnd];
}
private static void mergeSort(int[] a,int[] tmp,int left,int right){
if(left < right)
{
int center = (left + right) /2;
mergeSort(a,tmp,left,center);
mergeSort(a,tmp,center+1,right);
merge(a,tmp,left,center+1,right);
}
}
public static void mergeSort(int[] a){
int[] tmp = new int[a.length];
mergeSort(a,tmp,0,a.length-1);
}
假设输入元素:[7, 12, 24, 28, 35, 36, 54, 67, 87, 95] 则比较情况打印如下:
leftPos = 0/ leftEnd =0/ rightPos = 1/ rightEnd = 1
leftPos = 0/ leftEnd =1/ rightPos = 2/ rightEnd = 2
leftPos = 3/ leftEnd =3/ rightPos = 4/ rightEnd = 4
leftPos = 0/ leftEnd =2/ rightPos = 3/ rightEnd = 4
leftPos = 5/ leftEnd =5/ rightPos = 6/ rightEnd = 6
leftPos = 5/ leftEnd =6/ rightPos = 7/ rightEnd = 7
leftPos = 8/ leftEnd =8/ rightPos = 9/ rightEnd = 9
leftPos = 5/ leftEnd =7/ rightPos = 8/ rightEnd = 9
leftPos = 0/ leftEnd =4/ rightPos = 5/ rightEnd = 9
快速排序
快速排序的做法是首先找一个枢纽元,然后拿数组中的元素和它一一比较,比它小的放到一个新的数组A中,比他大的放到另外一个数组B中。然后在A,B中再找出枢纽元再进行排序,直到只剩下3个元素。采用快速排序一般要考虑到三个问题:
- 如何找到枢纽元
- 如何避免额外的内存开支
- 对于小数组的处理方式
那么针对第一个问题,一般采用的是三数中值分割法,即使用左端、右端和中心位置的三个数进行比较,折中的就是我们的枢纽元。
第二个问题,就要考虑到分割的策略了,我们在找到枢纽元之后,把它放置到 length-1 的位置,而首元素和末尾的元素就不需要参加比较了,因为他们是正确的摆放位置,那么就要从 position(首元素) + 1 的位置和 position(尾元素)-2开始比较,直到 i 和 j 交错为止,然后再将i的位置和枢纽元的位置交换,这样就达到我们的预期了,并且没有开支额外的内存。
对于小数组的情况,快速排序还不如插入排序,除了效率问题,还可以避免,当三个数进行比较的时候,实际上我们只有一个或者两个元素。
//选出中值
private static int selectPivot(int[] a,int left,int right){
int center = (left + right)/2;
if(a[center] < a[left])
exchange(a, left, center);
if(a[right]<a[left])
exchange(a, left, right);
if(a[right]<a[center])
exchange(a, center, right);
exchange(a, center, right-1);
return a[right-1];
}
private static int CUTOFF = 3;
private static void quickSort(int[] a,int left,int right){
if(left + CUTOFF < right)
{
int pivot = selectPivot(a, left, right);
int i= left,j = right - 1;
for( ; ; )
{
while(a[++i] < pivot){}
while(a[--j] > pivot){}
if( i < j)
exchange(a, i, j);
else
break;
}
exchange(a, i, right-1);
quickSort(a, left, i-1);
quickSort(a, i+1, right);
}
else
insertSort(a,left,right);
}
private static void insertSort(int[] a,int left,int right){
int j;
for(int i= left + 1;i<=right;i++){
int tmp = a[i];
for(j = i;j > left && tmp < a[j-1];j--)
a[j] = a[j-1];
a[j] = tmp;
}
}
//快速排序的驱动程序
public static void quickSort(int[] a){
quickSort(a,0,a.length - 1);
}
线性排序
根据决策树,我们知道只是用元素间比较的任何排序算法均需要 Ω(NlogN)次比较。但在某些情况下以线性时间进行排序还是有可能的,当然需要我们牺牲空间为基础。
桶排序
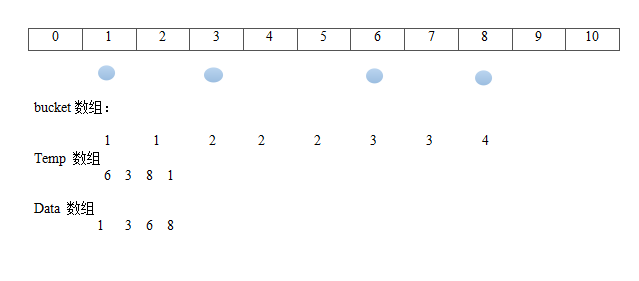
对于一些小的值域数组,我们可以用桶排序,比如比较的数都在[1,10]范围内,我们可以准备0~10个桶,依次统计比较数组落入桶中的次数,然后依次打印即可。
public static void bucketSort(int[] data, int min, int max) {
// 缓存数组
int[] tmp = new int[data.length];
// buckets用于记录待排序元素的信息
// buckets数组定义了max-min个桶
int[] buckets = new int[max - min];
// 计算每个元素在序列出现的次数
for (int i = 0; i < data.length; i++) {
buckets[data[i] - min]++;
}
// 计算“落入”各桶内的元素在有序序列中的位置
for (int i = 1; i < max - min ; i++) {
buckets[i] = buckets[i] + buckets[i - 1];
}
// 将data中的元素完全复制到tmp数组中
System.arraycopy(data, 0, tmp, 0, data.length);
// 根据buckets数组中的信息将待排序列的各元素放入相应位置
for (int k = data.length - 1; k >= 0; k--) {
data[--buckets[tmp[k] - min]] = tmp[k];
}
} 假设输入 [6,3,8,1] 上述过程如下图所示:
基数排序
理解了桶排序,那么基数排序自然就懂了,桶排序针对的是面对小数组的排序,那么需要排序的数很大,三位甚至四位怎么办,可以根据每个位数上的数字来比较。
public static void radixSort(int[] data, int radix, int d) {
// 缓存数组
int[] tmp = new int[data.length];
// buckets用于记录待排序元素的信息
// buckets数组定义了max-min个桶
int[] buckets = new int[radix];
for (int i = 0, rate = 1; i < d; i++) {
// 重置count数组,开始统计下一个关键字
Arrays.fill(buckets, 0);
// 将data中的元素完全复制到tmp数组中
System.arraycopy(data, 0, tmp, 0, data.length);
// 计算每个待排序数据的子关键字
for (int j = 0; j < data.length; j++) {
int subKey = (tmp[j] / rate) % radix;
buckets[subKey]++;
}
for (int j = 1; j < radix; j++) {
buckets[j] = buckets[j] + buckets[j - 1];
}
// 按子关键字对指定的数据进行排序
for (int m = data.length - 1; m >= 0; m--) {
int subKey = (tmp[m] / rate) % radix;
data[--buckets[subKey]] = tmp[m];
}
rate *= radix;
}
} 排序比较
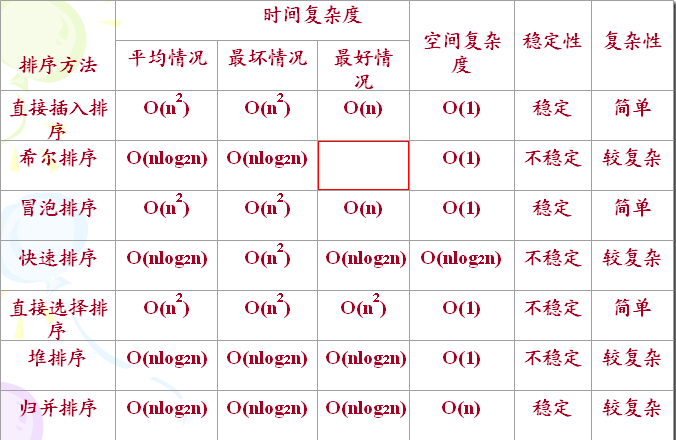
资料
1.《数据结构与算法分析》 Mark Allen Weiss
2. http://blog.csdn.net/apei830/article/details/6596104















 6729
6729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









