









正则表达式
关于正则表达式的来源和历史有感兴趣的小伙伴直接看百度百科就好;
正则表达式你可以理解它是用事先规定好的一些符号,及一些特定组合来组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑”,来过滤你想要找出的字符串;而其强大之处在于,这个规则是通用的,不管你在哪个版本,哪里,只要是支持正则表达式,他就是这个规则,所以还是有必要记一记的;
下面就来说一说这些事先定好的规则,主要分为三类:
字符类
数量限定符
位置限定符
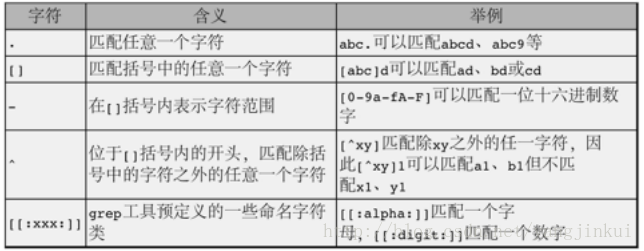
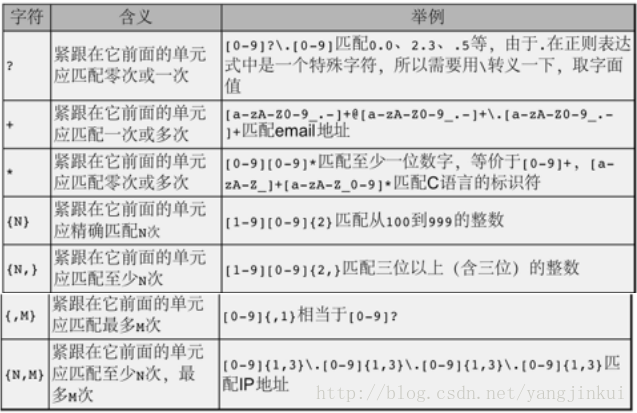
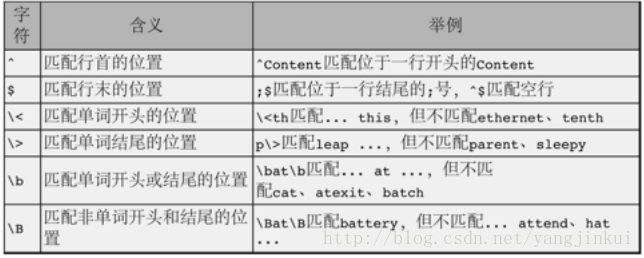
这里三种类型的符号就已经足以表达一个你想要找到的字符串类型;
例如我们想找IP地址的话,
^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}$
这里^代表开始,就是开头的意思;
然后[]代表其中的字符挑选一个,可以[1-4]也可以[1234]都是一个意思;
{1,3}可以查上面的数量限定符,代表最少1个最多3个,因为IP是0-255一个分割的;
‘.’直接用的话是有特殊含义的,代表匹配任意一个字符,这里我们要的是字面意思 就是 ‘.’所以加一个\转义字符;
所以这样就能够把我们想要表达的意思表达出来了;
但是同时还要注意一件事情,正则表达式是有两个规范的,一个基本的Basic规范,一个扩展版的Extended规范;在基本规范中字符?+{}|()应解释 为普通字符,要表⽰上述特殊含义则需要加\转义;而在扩展规范中其代表特殊含义,要取字面意思,则要加转义字符\;
下面就再举一些linux实际使用正则表达式来搜索的例子:
使用grep命令搜索文件的时候就可以用正则表达式来搜索自己想要的;
假设我现在有一个文件中储存了一些qq邮箱,现在我们要查找其中合法的qq邮箱;这里的-E就代表我们要使用Extended规范,grep默认是Basic规范;
file文件:
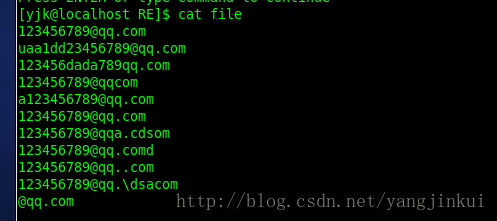
这个时候就是要把我们要查找的字符串用定好的规则书写出来就好:
首先是开头肯定是5-11的数字,并且肯定不是0开头的,所以开头为[1-9][0-9]{4,9};代表1-9中出现一个,0-9中数字出现最少4次最多9次;
然后在加上@qq.com因为 . 也是特殊字符所以需要转义,就成了@qq.com;
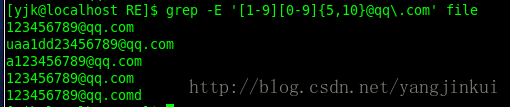
这个时候不成功是因为我们没有对其出现的位置进行限定所以导致其判断跟我们想的不一样,所以再规定开头^结尾¥就好了;

所以正则表达式并不难,但是为了能够熟用它,还是要多多练习的;














 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









