







貌似是挺有争议的一篇文章,挺多人说这篇文章抄袭hdrnet,结果还中了CVPR的oral,不值这个价。暂时还没看hdrnet,所以我也不好评说,不过hdrnet的主页是这个这个,有空大概会去看一看。
(2020.7.13更新)昨天终于去把hdrnet的坑填了,传送门 在这里,然后发现果然这篇文章的网络和hdrnet是超级像的
Abstract&Introduction&Background
算法是用来增强曝光不足的图像的,之前的人们都是直接学习一个从图像到图像的映射,这里是引入了一个中间光照在输入和输出之间,增强了网络的能力
现有的一些面向非专业用户的软件都是没有大幅改变曝光度和对比度的,但是这样就对严重曝光不足的图片处理效果很差
早期的方法都是聚焦于对比度的增强,但是这样对于恢复细节和颜色不利,而通过学习的方法同时学习对颜色,对比度,亮度的调整,但是这些方法对于严重低光的图片效果仍然不好
新网络首先估计一个从图像到光照的映射,然后用光照图来增强曝光不够的图片。然后又想了个办法来降低计算消耗
Contributions
设计了一个对于多种环境都适用的网络以及一个更好的loss function
弄了一个3000张图像的数据集
在新的和现有的数据集上测试了方法,发现我们的新方法更好
Related Work
基于Retinex的方法:
将图片分解成反射和光照的像素级乘积,retinex把反射当做一个可信的近似,这样就只需要估计光照了。然而由于颜色通道的非线性性,现有方法增强颜色的能力有限,因为颜色在本地很容易就被扭曲。我们的工作有两点提高:网络学习了各种各样的光照条件、可以从多通道来进行非线性的颜色增强
基于学习的方法:反正挺多的,略
方法
图像增强的本质就是找到一个从输入图像到ground truth的映射函数,之前的工作中经常把F的逆建模为一个光照图S,这个S和反射图像(reflectance image)做逐像素的乘积得到的就是观察到的图像I
把反射分量I’当成曝光良好的图像(所以明明只是输入图像的一个分量,为什么可以当成我们要得到的目标图像)(——这个锅LIME来背,我们只是采取了和LIME一样的做法),但是注意,我们和[11,14]的做法不一样,我们把S建模成了一个具有RGB三个颜色通道的,这样比单通道能更好的处理不同颜色通道之间的非线性性
学习光照图的优点在于这东西如果有了先验,表达形式就会大大简化,另一方面,加入不同的先验可以获得所希望获得的不同的调整程度的图像
网络架构: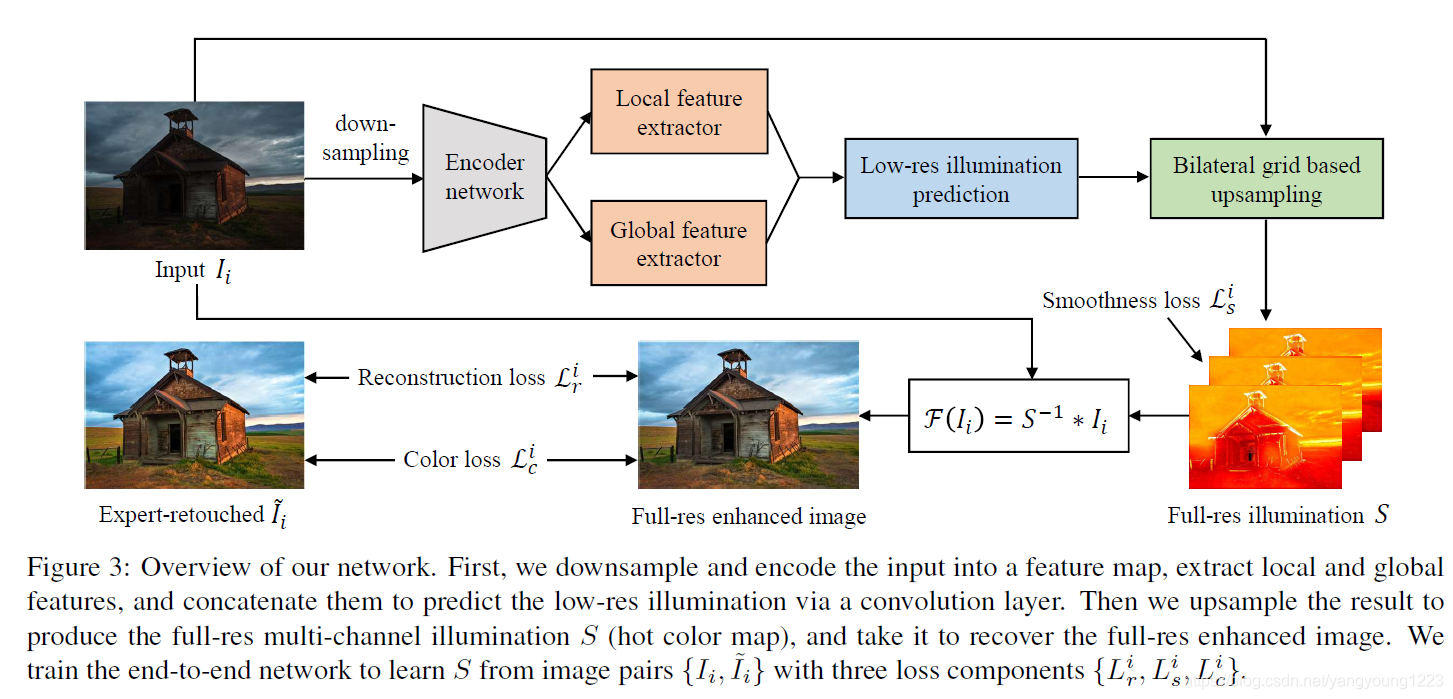
该网络有两个主要的好处:学习的过程是高效的、网络的计算是高效的
高效学习:对于改善一张曝光不足的照片既需要全局特征(颜色分布,平均亮度,场景分类),也需要局部特征(细节锐度、阴影、高光);
首先进行降采样,然后利用一个编码器来抽取局部和全局的特征(疑问:在低光照的情况下特征提取能成功吗),然后把他们连接到一起来进行低分辨率下的光照的预测,随后再进行采样的分辨率的提升得到S,(注意在获得S的时候加入了一个平滑的先验,所以会出来一个loss)因此,大部分计算是在低分辨率下进行的,所以也节省计算资源
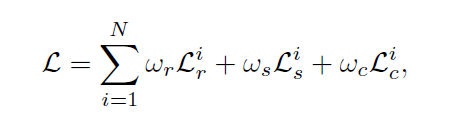
平滑的loss:Ls
自然光照下的图片都是局部光滑的
训练过程中要最小化的函数如下
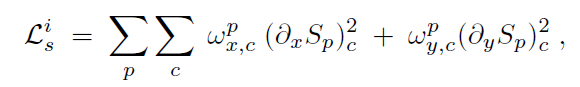
两个偏导符号代表这个图像沿x和沿y方向梯度,同样的,w依然是权重,权重的表达式如下
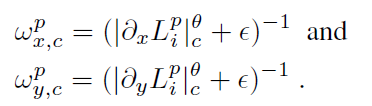
θ是一个超参数,这里取1.2,ε是一个防止除以0的极小量0.0001
Lr:图像之间逐像素的平方误差
Lr就是输入图像和ground truth被S作用(注意,我们这里的目标是要学习这样的一个S,而输入就是input和ground truth——I’)后得到的结果之间的差的模平方,如下
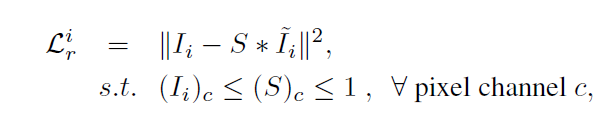
这里把I和I’的像素通道中的值统统归一成了0-1之间的数,控制这样的大小关系也是为了不让转换过的图像出现大于1的通道值
颜色损失:Lc
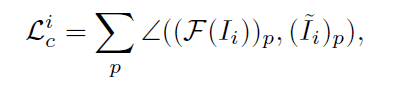
将颜色的RGB值当成三维向量,∠符号即表示两个向量之间的夹角
为什么不用L2范数呢?一方面,在Lr里面已经包含了颜色的L2范数,第二,对于颜色来说,更重要的似乎是颜色的向量方向而非单纯的像素差别小,最后,这样算得快
缺损实验结果:

可以看出,加了Lc的loss之后颜色确实更接近ground truth
数据集的选择
没有选择Adobe FiveK的数据集原因是他的数据集面向的是更广泛的图像增强,并没有特别针对曝光不足的图像(只有4%)
我们的数据集首先是从网上找到以低光照为标签的图像,然后交给图像专家用Adobe Lr调整出来的
代码细节
使用TensorFlow完成,40个epoch,batch size=16,用Adam优化器优化,学习率10^-4,为了增强数据,还把一些照片切割成512×512的小块,降采样的分辨率是256×256,encoder是一个预训练好的VGG16,本地特征提取器有两个卷积层,全局提取器包括两个卷积层和三个全连接层,用bilateral grid-based module(来自Deep bilateral learning for realtime image enhancement.)来升采样,对于网络的效果评估采用PSNR和SSIM
实验结果

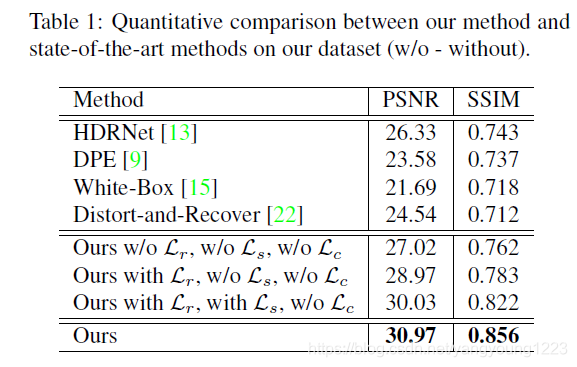
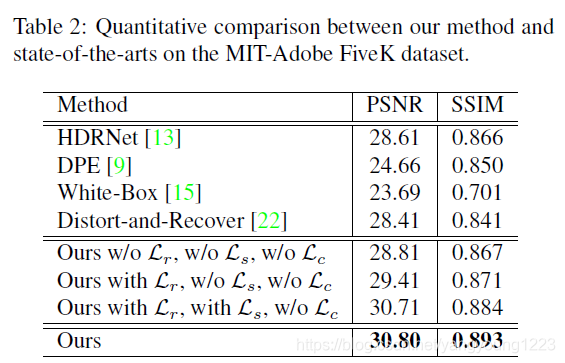
扩展到Adobe数据集上的结果表示我们的网络具有很好的泛化能力,不局限于弱光图像的增强
在人类受试者看来我们的图像也更好
局限
对以下二者的表现不好,以后要把去噪作为研究方向















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









