








文章目录
一、高级编程
1.可迭代对象
- 我们对list、tuple、dict、set、str等类型的数据使用for…in…的循环语法从其中依次拿到数据进行使用,这个过程称为遍历,也叫迭代。
- 把可以通过for…in…这类语句迭代读取一条数据供我们使用的对象称之为可迭代对象(Iterable)。
2.推导式
- 推导式分为: 列表推导式、字典推导式、集合推导式等。
- 在这里我们主要说其中一种也是用的最多列表推导式
列表推导式是Python构建列表(list)的一种快捷方式,可以使用简洁的代码就创建出一个列表,简单理解就是由一个旧的列表来构建出一个新的列表
示例1:获取列表中长度大于5的字符串
# 推导式
# [表达式 for 变量 in 旧列表]
# [表达式 for 变量 in 旧列表 if 条件]
list1 = ['yangyu','king','zhangyu','chenliang']
def fun1(lst):
new_list = []
for i in list1:
if len(i) > 6:
new_list.append(i)
print(new_list)
fun1(list1)
'''['zhangyu', 'chenliang']'''
list2 = [i for i in list1 if len(i) > 5]
print(list2)
'''['yangyu', 'zhangyu', 'chenliang']'''
示例2:求1-50之间的偶数,求1-50之间的偶数且被3整除的偶数
# 推导式
# [表达式 for 变量 in 旧列表]
# [表达式 for 变量 in 旧列表 if 条件]
# 需求:求1-50之间的偶数
list1 = [i for i in range(1, 51) if i % 2 == 0]
print(list1)
'''
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50]'''
# 需求:求1-50之间的偶数且被3整除的偶数
list2 = [i for i in range(1, 51) if i % 2 == 0 and i % 3 == 0]
print(list2)
'''[6, 12, 18, 24, 30, 36, 42, 48]'''
3.生成器
背景
通过列表推导式我们可以直接创建出一个列表,但是受到内存的限制,我们不可能创造出一个无限大的列表。而且创建一个有200万个元素的列表,会占用很大的内存空间,而这个时候我们仅仅需要访问列表中几个元素,那么后面的元素占用着空间就是一种浪费的行为。那么我们可不可以用几个元素就创建出几个元素。这样在一定程度上就优化了内存。那么在Python中有一种一边循环一边计算的机制就是生成器
- 创建生成器的方式
1.通过列表推导式的方式
gen = (i for i in range(1, 11))
print(gen) # <generator object <genexpr> at 0x00000000027F7748>
2.通过函数的方式
def fu():
n = 0
while True:
n += 1
yield n
只要在函数中出现yield关键字它就是一个生成器函数
示例1
# 创建生成器的方法
# 方法一:通过列表推导式的方式
list1 = [i for i in range(1, 11)]
print(list1) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
'''
创建一个有200万个元素的列表,会占用很大的内存空间,而这个时候我们仅仅需要访问列表中几个元素,那么后面的元素就占用着空间就是一种浪费的行为'''
gen = (i for i in range(1, 11))
print(gen) # <generator object <genexpr> at 0x00000000027F7748>
print(type(gen)) # <class 'generator'>
# 我不希望一次性得到太多的数据,我要多少数据你就给我多少数据(非常人性化,由认为控制)
# print(gen.__next__()) # 1
# print(gen.__next__()) # 2
# 通过next()函数来获得
# print(next(gen)) # 1
# print(next(gen)) # 2
# print(next(gen)) # 3
i = 0
while i < 5:
print(next(gen))
i += 1
'''
1
2
3
4
5'''
# 生成器的特性1:生成器会记住上一次取数据的位置,然后下一次取数据时继续从上一次的位置运行
list2 = [i for i in gen]
list3 = [i for i in gen]
print(list2) # [6, 7, 8, 9, 10]
print(list3) # []
# 方法二:使用函数加上yield来实现生成器
def fun1():
i = 0
while True:
i += 1
# return 1
yield i
r = fun1()
print(next(r)) # 1
print(next(r)) # 2
print(next(r)) # 3
print(next(r)) # 4
# 生成器的特性2:生成器生成一次只能取完一次数据,第二次再取就不存在数据了
示例2
# 使用 yield 实现斐波那契数列:
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print(next(f), end=" ")
except StopIteration:
sys.exit()
'''0 1 1 2 3 5 8 13 21 34 55 '''
4.迭代器
- 关系对应图
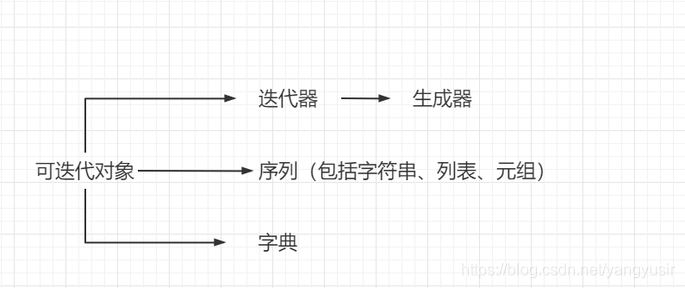
- 迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
示例
# 迭代器
list1 = [1, 2, 3, 4, 5, 6]
ite = iter(list1)
print(type(ite)) # <class 'list_iterator'>
print(ite) # <list_iterator object at 0x00000000023E33C8>
print(next(ite)) # 1 输出迭代器的下一个元素
tuple1 = (1, 2, 3, 4, 5, 6)
ite2 = iter(tuple1)
print(type(ite2)) # <class 'tuple_iterator'>
print(ite2) # <tuple_iterator object at 0x0000000002853408>
print(next(ite2)) # 1 输出迭代器的下一个元素
# 把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。
class MyNum:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 10:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNum()
myiter = iter(myclass)
for x in myiter:
print(x)
'''
1
2
3
4
5
6
7
8
9
10
'''
5.迭代器、生成器、可迭代对象关系
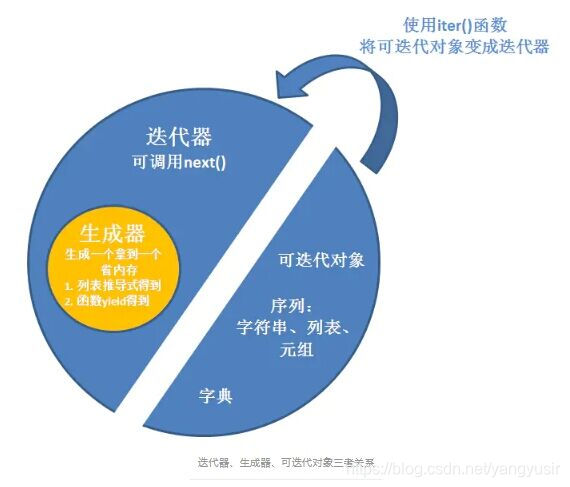
6.PEP8规范编写代码
PEP8: Python代码风格指南
PEP8 提供了 Python 代码的编写约定. 本节知识点旨在提高代码的可读性, 并使其在各种 Python 代码中编写风格保持一致.
- 1.缩进使用4个空格, 空格是首选的缩进方式. Python3 不允许混合使用制表符和空格来缩进.
- 2.每一行最大长度限制在79个字符以内.
- 3.顶层函数、类的定义, 前后使用两个空行隔开.
- 4.import 导入
导入建议在不同的行, 例如:
import os
import sys
不建议如下导包
import os, sys
但是可以如下:
from subprocess import Popen, PIPE
- 5.导包位于文件顶部, 在模块注释、文档字符串之后, 全局变量、常量之前. 导入按照以下顺序分组:
标准库导入
相关第三方导入
本地应用/库导入
在每一组导入之间加入空行 - 6.Python 中定义字符串使用双引号、单引号是相同的, 尽量保持使用同一方式定义字符串. 当一个字符串包含单引号或者双引号时, 在最外层使用不同的符号来避免使用反斜杠转义, 从而提高可读性.
- 7.表达式和语句中的空格:
避免在小括号、方括号、花括号后跟空格.
避免在逗号、分号、冒号之前添加空格.
冒号在切片中就像二元运算符, 两边要有相同数量的空格. 如果某个切片参数省略, 空格也省略.
避免为了和另外一个赋值语句对齐, 在赋值运算符附加多个空格.
避免在表达式尾部添加空格, 因为尾部空格通常看不见, 会产生混乱.
总是在二元运算符两边加一个空格, 赋值(=),增量赋值(+=,-=),比较(==,<,>,!=,<>,<=,>=,in,not,in,is,is not),布尔(and, or, not)
避免将小的代码块和 if/for/while 放在同一行, 要避免代码行太长.
if foo == 'blah': do_blah_thing()
for x in lst: total += x
while t < 10: t = delay()
- 8.永远不要使用字母 ‘l’(小写的L), ‘O’(大写的O), 或者 ‘I’(大写的i) 作为单字符变量名. 在有些字体里, 这些字符无法和数字0和1区分, 如果想用 ‘l’, 用 ‘L’ 代替.
- 9.类名一般使用首字母大写的约定.
- 10.函数名应该小写, 如果想提高可读性可以用下划线分隔.
- 11.如果函数的参数名和已有的关键词冲突, 在最后加单一下划线比缩写或随意拼写更好. 因此 class_ 比 clss 更好.(也许最好用同义词来避免这种冲突).
- 12.方法名和实例变量使用下划线分割的小写单词, 以提高可读性.
二、面向对象
- Python是一门面向对象的编程语言
- 所谓面向对象的语言,简单理解就是语言中的所有操作都是通过对象来进行的
- 面向过程
面向过程指将我们的程序分解为一个一个步骤,通过对每个步骤的抽象来完成程序,这种编写方式往往只适用于一个功能,如果要实现别的功能,往往复用性比较低,这种编程方式符号人类的思维,编写起来比较容易。 - 面向对象的编程语言,关注的是对象,而不注重过程,对于面向对象:一切皆对象
- 面向对象的编程思想,将所有功能统一保存到对应的对象中,要使用某个功能,直接找到对应的对象即可
- 这种编码方式比较容易阅读,并且易于维护,容易复用。但是编写的过程中不太符合常规的思维,编写相对麻烦
1. 类(class)
- 我们目前学习的都是Python的内置对象,但是内置对象并不都能满足我们的需求,所以我们在开发中经常要自定义一些对象
- 类简单理解它就是相当于一个图纸,在程序汇总时,我们需要根据类来创建对象。
- 类就是对象的图纸
- 我们也称对象是类的实例(instance)
- 如果多个对象是通过一个类创建的,我们称这些对象是一类对象
# 在python中,想要使用一个东西,必须先创建一个这样的对象
# 自定义类 图纸 通过图纸创建出来的汽车 汽车就是通过图纸创建出来的实例对象
class MyClass(): # 定义类,给它取名为MyClass 类相当于一个图纸,类对象:只是用于存储功能
pass
mc = MyClass() # 创建实例对象(类的实例化) 实现效果的功能
# 类对象(存储属性、功能) 实例对象(实现效果的功能)
mc1 = MyClass()
print(id(mc), id(mc1)) # 42466312 42455816
# 类可以创建多个实例,每个实例各不相同,我们称这一些实例为一类实例
# isinstance() 用来检测这个实例是否是这个类创建出来的
print(isinstance(mc, MyClass)) # True
print(isinstance(mc1, MyClass)) # True
- 语法
class 类名([父类]):
pass
- 类也是一个对象,类就是用来创建对象的对象
- 可以向对象中添加变量,对象中的变量称之为属性
- 语法:对象.属性名 = 属性值
2. 类的定义
类(Class): 用来描述具有相同的属性和方法的对象的集合。
- 类和对象都是对现实生活中事物的抽象
- 事物包含两部分
1.数据(属性)
2.行为(方法) - 调用方法:对象.方法名()
- 方法调用和函数调用的区别:如果是函数调用,调用时有几个形参,就会传递几个实参。如果是方法调用,默认传递一个参数,所以方法中至少得有一个形参
- 在类代码块中,我们可以定义变量和函数
- 变量会成为该类实例的公共属性,所有该类实例都可以通过 对象.属性名的形式访问
- 函数会成为该类实例的公共方法,所有该类实例都可以通过 对象.方法名的形式访问
示例1
class Person(): # 类里面有的东西,实例里面一定会有
name = '花花' # 属性
p1 = Person()
print(p1.name) # 花花 实例.属性 就可以获取属性值
p2 = Person()
p2.name = '草草'
print(p2.name) # 草草
p3 = Person()
print(p3.name) # 花花
示例2
class Person(): # 类里面有的东西,实例里面一定会有
name = '花花' # 属性
def speak(self): # 方法
print('你好')
p1 = Person()
print(p1.name) # 花花 实例.属性 就可以获取属性值
p1.speak() # 你好
# 在类代码中,我们可以定义变量和函数
# 定义在类中的变量会成为该类实例的公共属性,所有的实例都可以通过 对象.属性名的形式来访问
# 定义在类中的函数会成为该类实例的公共方法,所有的实例都可以通过 对象.方法名()的形式来访问
3. 参数self
3.1 属性和方法
- 类中定义的属性和方法都是公共的,任何该类实例都可以访问
- 属性和方法的查找流程
- 当我们调用一个对象的属性时,解析器会先在当前的对象中寻找是否有该属性,如果有,则直接返回当前的对象的属性值。如果没有,则去当前对象的类对象中去寻找,如果有则返回类对象的属性值。如果没有就报错
- 类对象和实例对象中都可以保存属性(方法)
- 如果这个属性(方法)是所有的实例共享的,则应该将其保存到类对象中
- 如果这个属性(方法)是某个实例独有的。则应该保存到实例对象中
- 一般情况下,属性保存到实例对象中, 而方法需要保存到类对象中
3.2 self
- self在定义时需要定义,但是在调用时会自动传入。
- self的名字并不是规定死的,但是最好还是按照约定是用self
- self总是指调用时的类的实例
示例1
class Person():
name = '花花'
# 哪个对象调用speak方法,那么s就是这个对象
def speak(s):
# print('你好,我是%s' % s.name)
print(s)
p1 = Person()
print(p1)
p1.speak()
'''
<__main__.Person object at 0x00000000028337C8>
<__main__.Person object at 0x00000000028337C8>'''
示例2
class Person():
def speak(self):
print('你好,我是%s' % self.name)
def run(self): # self就等于任何调用我这个方法的对象本身
pass
p1 = Person()
p1.name = '花花'
p1.speak()
p2 = Person()
p2.name = '草草'
p2.speak()
'''
你好,我是花花
你好,我是草草'''
4. 魔术方法
• 在类中可以定义一些特殊方法称为魔术方法
• 特殊方法都是形如 __xxx__()这种形式
• 特殊方法不需要我们调用,特殊方法会在特定时候自动调用
# 魔术方法
class Person():
# 初始化方法
def __init__(self, name, age): # 实例创建的时候__init__方法就会调用
self.name = name
self.age = age
def speak(self):
print("大家好,我是%s,今年%s岁" % (self.name, self.age))
# 问题:1.手动添加容易忘记,查看代码需要哪些参数比较麻烦 2.没有提示,可以创建成功实例,会导致后面的代码运行出错
p1 = Person('yangyu', 18)
p1.speak()
p2 = Person('huahua', 17)
p2.speak()
'''
大家好,我是yangyu,今年18岁
大家好,我是huahua,今年17岁'''
5. 封装
- 出现封装的原因:我们需要一种方式来增强数据的安全性
- 属性不能随意修改
- 属性不能改为任意的值
# 封装的引入
# 封装的概念:就是为了数据的安全,形成了一个默认的规则,告诉你的协同开发者,这个属性很重要,不要随意修改
class Car():
def __init__(self, name, color):
self.name = name
self.color = color
def run(self):
print("汽车开始启动")
def dididi(self):
print("汽车开始鸣笛")
car = Car('布加迪', '蓝色')
car.name = '破二手车'
print(car.name)
car.run()
car.dididi()
'''
破二手车
汽车开始启动
汽车开始鸣笛'''
# 封装:私有属性
class Car():
def __init__(self, name, color):
self._name = name # 私有属性
self.color = color
def run(self):
print("汽车开始启动")
def dididi(self):
print("汽车开始鸣笛")
car = Car('布加迪', '蓝色')
car.run()
car.dididi()
# print(car.name) # AttributeError: 'Car' object has no attribute 'name'
print(car._name) # 布加迪
# 封装:隐藏属性
class Car():
def __init__(self, name, color):
self.__name = name # 隐藏属性 不可读属性
self.color = color
def run(self):
print("汽车开始启动")
def dididi(self):
print("汽车开始鸣笛")
car = Car('布加迪', '蓝色')
car.run()
car.dididi()
# print(car.__name) # 'Car' object has no attribute '__name'
print(car._Car__name) # 布加迪 不推荐这样使用
- 封装是面向对象的三大特性之一
- 封装是指隐藏对象中一些不希望被外部所访问到的属性或方法
- 我们也可以提供给一个getter()和setter()方法使外部可以访问到属性
getter() 获取对象中指定的属性
setter() 用来设置对象指定的属性
# 设置getter()和setter()方法
class Car():
def __init__(self, name, color):
self._name = name
self.color = color
# getter() 提供给你访问属性的方法
def get_name(self):
return self._name
# setter()方法 提供给你修改属性的方法
def set_name(self, name):
self._name = name
def run(self):
print("汽车开始启动")
def dididi(self):
print("汽车开始鸣笛")
car = Car('布加迪', '蓝色')
car.run()
car.dididi()
print(car.get_name()) # 布加迪
car.set_name('帕拉梅拉')
print(car.get_name()) # 帕拉梅拉
- 使用封装,确实增加了类的定义的复杂程度,但是它也确保了数据的安全
隐藏属性名,使调用者无法随意的修改对象中的属性
增加了getter()和setter()方法,很好控制属性是否是只读的
使用setter()设置属性,可以在做一个数据的验证
使用getter()方法获取属性,使用setter()方法设置属性可以在读取属性和修改属性的同时做一些其他的处理 - 可以为对象的属性使用双下划线开头 __xxx。双下划线开头的属性,是对象的隐藏属性,隐藏属性只能在类的内部访问,无法通过对象访问
- 其实隐藏属性只不过是Python自动为属性改了一个名字 --> _类名__属性名 例如 __name -> _Person__name,这种方式实际上依然可以在外部访问,所以这种方式我们一般不用。一般我们会将一些私有属性以_开头
- 一般情况下,使用_开头的属性都是私有属性,没有特殊情况下不要修改私有属性
6. property装饰器
- 我们可以使用@property装饰器来创建只读属性,@property装饰器会将方法转换为相同名称的只读属性,可以与所定义的属性配合使用,这样可以防止属性被修改
# property装饰器
class Car():
def __init__(self, name, color):
self._name = name
self.color = color
@property # 使car.get_name()变成car.get_name,可以进一步简写为name
# getter() 提供给你访问属性的方法
def name(self):
return self._name
@name.setter
# setter()方法 提供给你修改属性的方法
def name(self, name):
self._name = name
def run(self):
print("汽车开始启动")
def dididi(self):
print("汽车开始鸣笛")
car = Car('布加迪', '蓝色')
car.run()
car.dididi()
print(car.name) # 布加迪
car.name = '玛莎拉蒂'
print(car.name) # 玛莎拉蒂
7. 继承
- 继承是面向对象三大特性之一
- 通过继承我们可以使一个类获取到其他类中的属性和方法
- 在定义类时,可以在类名后面的括号中指定当前类的父类(超类、基类)
- 继承提高了类的复用性。让类与类之间产生了关系。有了这个关系,才有了多态的特性
# 继承的引入
class Animal(object): # 括号内没写,默认继承object
def sleep(self):
print('动物会睡觉')
def run(self):
print('动物会跑')
class Dog(Animal):
def sleep(self): # 同名方法的重写
print('狗会睡觉')
dog = Dog()
dog.run() # 动物会跑
dog.sleep() # 狗会睡觉
# 检测实例是否是一个类的实例
print(isinstance(dog, Dog)) # True
print(isinstance(dog, Animal)) # True
# 检测一个类是否是一个类的父类
print(issubclass(Dog, Animal)) # True
print(issubclass(Animal,object)) # True
7.1 方法重写
- 如果在子类中有和父类同名的方法,则通过子类实例去调用方法时,会调用子类的方法而不是父类的方法,这个特点我们称之为方法的重写(覆盖)
- 当我们调用一个对象的方法时:
- 会优先去当前对象中寻找是否有该方法,如果有则直接调用
- 如果没有,则去当前对象的父类中寻找,如果父类中有则直接调用父类中的方法
- 如果没有,则去父类中的父类寻找,以此类推,直到找到object,如果依然没有找到就报错了
# 方法的重写: 必须建立在继承的基础之上
class A(object):
def text(self):
print('A')
class B(A):
pass
class C(B):
pass
c = C()
c.text() # A
7.2 super()
- super()可以获取当前类的父类
- 并且通过super()返回对象调用父类方法时,不需要传递self
# super()方法的使用:必须要有父类的继承和方法的重写
class A(object):
def sleep(self):
print('睡觉')
class Animal(A):
def sleep(self):
print('动物会睡觉')
super().sleep()
def run(self):
print('动物会跑')
class Dog(Animal):
def sleep(self): # 同名方法的重写
print('狗会睡觉')
# super()的作用:将覆盖了的父类方法重新调用
super().sleep()
dog = Dog()
dog.sleep()
'''
狗会睡觉
动物会睡觉
睡觉'''
7.3 多重继承
- 在Python中是支持多重继承的。也就是我们可以为一个类同时指定多个父类
- 可以在类名的()后边添加多个类,来实现多重继承
- 多重继承,会使子类同时拥有多个父类,并且会获取到所有父类中的方法
- 在开发中没有特殊情况,应该尽量避免使用多重继承。因为多重继承会让我们的代码更加复杂
- 如果多个父类中有同名的方法,则会先在第一个父类中寻找,然后找第二个,找第三个…前面会覆盖后面的
# 多重继承:不推荐使用解耦合原则:不希望太多代码称为彼此相牵连的代码
class Person1(object):
def chuiniu(self):
print('很会吹牛')
def cool(self):
print('貌似潘安')
class Person2(object):
def paimabi(self):
print('很会拍马屁')
def cool(self):
print('貌似大郎')
class Son(Person1, Person2):
pass
son = Son()
son.chuiniu() # 很会吹牛
son.paimabi() # 很会拍马屁
son.cool() # 貌似潘安
# 解耦合原则:就是尽量不希望太多代码称为彼此相牵连的代码
# 解耦合的作用:方便维护,提高了问题的解决效率,降低了问题的解决难度
7.4 多态
- 多态是面向对象的三大特性之一。从字面理解就是多种形态
- 一个对象可以以不同形态去呈现
- 面向对象三大特性
封装 确保对象中数据的安全
继承 保证了对象的扩展性
多态 保证了程序的灵活性 - Python中多态的特点
1、只关心对象的实例方法是否同名,不关心对象所属的类型;
2、对象所属的类之间,继承关系可有可无;
3、多态的好处可以增加代码的外部调用灵活度,让代码更加通用,兼容性比较强;
4、多态是调用方法的技巧,不会影响到类的内部设计。
# 多态的简介
# 示例1:
class A(object):
def __init__(self, name):
self.name = name
def speak(self):
print('大家好,我是%s' % self.name)
class B(object):
def __init__(self, name):
self.name = name
def speak(self):
print('大家好,我是%s' % self.name)
a = A('yangyu')
b = B('KING')
def fun(obj):
obj.speak()
fun(a) # 大家好,我是yangyu
fun(b) # 大家好,我是KING
# 鸭子类型:“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
# 在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型。
# 示例2:
class Duck(object):
def fly(self):
print('鸭子沿着地面飞起来了')
class Swan(object):
def fly(self):
print('天鹅飞起来了')
class Plane(object):
def fly(self):
print('飞机飞起来了')
def fly(obj):
obj.fly()
duck = Duck()
swan = Swan()
plane = Plane()
fly(duck) # 鸭子沿着地面飞起来了
fly(swan) # 天鹅飞起来了
fly(plane) # 飞机飞起来了
# 示例3:
class Grandpa(object):
def money(self):
print('这是爷爷的钱')
class Father(Grandpa):
def money(self):
super().money()
print('这是爸爸的钱')
class Mother(Grandpa):
def money(self):
super().money()
print('这是妈妈的钱')
def money(obj):
obj.money()
g = Grandpa()
f = Father()
m = Mother()
money(g) # 这是爷爷的钱
money(f) # 这是爸爸的钱
money(m) # 这是妈妈的钱
'''
这是爷爷的钱
这是爷爷的钱
这是爸爸的钱
这是爷爷的钱
这是妈妈的钱'''
7.5 属性和方法
- 属性
类属性,直接在类中定义的属性是类属性
类属性可以通过类或类的实例访问到。但是类属性只能通过类对象来修改,无法通过实例对象修改 - 实例属性 通过实例对象添加的属性属于实例属性
实例属性只能通过实例对象来访问和修改,类对象无法访问修改 - 方法
- 在类中定义,以self为第一个参数的方法都是实例方法
实例方法在调用时,Python会将调用对象以self传入
实例方法可以通过类实例和类去调用
当通过实例调用时,会自动将当前调用对象作为self传入
当通过类调用时,不会自动传递self,我们必须手动传递self - 类方法 在类的内容以@classmethod 来修饰的方法属性类方法
类方法第一个参数是cls 也会自动被传递。cls就是当前的类对象
类方法和实例方法的区别,实例方法的第一个参数是self,类方法的第一个参数是cls
类方法可以通过类去调用,也可以通过实例调用 - 静态方法
在类中用@staticmethod来修饰的方法属于静态方法
静态方法不需要指定任何的默认参数,静态方法可以通过类和实例调用
静态方法,基本上是一个和当前类无关的方法,它只是一个保存到当前类中的函数
静态方法一般都是些工具方法,和当前类无关
# 属性和方法
# 类属性和实例属性
class A(object):
# 类属性:直接定义在类中的属性
# 类属性可以通过类和实例对象来调用
# 类属性只能通过类对象来修改,不能通过实例对象来修改
num = 0 # 类属性
def __init__(self, name):
self.name = name # 这个属性也是实例属性
print(self) # <__main__.A object at 0x0000000002801748>
def speak(self): # 实例方法
print('大家好,我是%s' % self.name)
@classmethod # 类方法
def run(cls):
print('我能跑')
@staticmethod
def static(): # 功能方法、工具方法
print('我是静态方法')
a = A('yangyu')
print(a) # <__main__.A object at 0x0000000002801748>
# 实例属性:通过实例对象添加的属性就是实例属性,只能通过实例对象调用,不能使用类对象调用
a.num = 10
print(A.num) # 0 使用类对象来调用属性
print(a.num) # 10 使用实例对象来调用属性
print(a.name) # yangyu
# print(A.name) # AttributeError: type object 'A' has no attribute 'name'
# 实例方法 类对象和实例对象都可以调动,但是类对象需要传递一个实例对象参数
a.speak() # 大家好,我是yangyu
# A.speak() # TypeError: speak() missing 1 required positional argument: 'self'
A.speak(a) # 大家好,我是yangyu
# 类方法 类对象和实例对象都可以调用
A.run() # 我能跑
a.run() # 我能跑
# 静态方法
A.static() # 我是静态方法
a.static() # 我是静态方法
7.6 单例模式
__new__()方法
__new__()方法用于创建和返回一个对象。在类准备将自身实例化时调用。
练习:以下代码打印输出的顺序?
A.__init__,__new__
B.__init__
C.__new__
D.__new__,__init__
class Demo(object):
def __init__(self):
print("__init__")
def __new__(cls, *args, **kwargs):
print("__new__")
d = Demo()
'''
__new__
'''
注意
- __new__()方法用于创建对象
- __init__()方法在对象创建的时候,自动调用
- 但是此处重写了父类的__new__()方法,覆盖了父类__new__()创建对象的功能,所以对象并没有创建成功。所以仅执行__new__()方法内部代码
对象创建执行顺序
1.通过__new__()方法创建对象
2.并将对象返回,传给__init__()
练习:在自定义类中实现创建对象
思路
- 重写父类__new__()方法
- 并且在该方法内部,调用父类的__new__()方法
class Demo(object):
def __init__(self):
print("__init__")
def __new__(cls, *args, **kwargs):
print("__new__")
return super().__new__(cls)
d = Demo()
'''
__new__
__init__
'''
注意
- 在创建对象时,一定要将对象返回,才会自动触发__init__()方法
- __init__()方法当中的self,实际上就是__new__返回的实例,也就是该对象
__init__()与__new__()区别:
- __init__实例方法,__new__静态方法
- __init__在对象创建后自动调用,__new__创建对象的方法
单例模式
单例模式是一种常用的软件设计模式。也就是说该类只包含一个实例。
通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
通常应用在一些资源管理器中,比如日志记录等。
单例模式实现
思路
• 当对象不存在时,就调用super()方法创建实例并返回
• 当对象存在时,就不在调用super()方法,而是直接返回之前的那个实例对象
class single(object):
obj = None
def __new__(cls, *args, **kwargs):
if cls.obj is None:
cls.obj = super().__new__(cls)
return cls.obj
else:
return cls.obj
a = single()
b = single()
print(id(a))
print(id(b))
'''
42276680
42276680'''
三、模块
1.模块的简介
模块化指将一个完整的程序分解成一个个的小模块
通过将模块组合,来搭建出一个完整的程序
模块化的优点:方便开发,方便维护,模块可以复用
2.模块的创建
在Python当中一个py文件就是一个模块
在一个模块中引入外部模块: import 模块名(模块名就是py文件)
可以引入同一个模块多次,但是模块的实例只会创建一次
import 模块名 as 模块别名
在一个模块内部都有一个__name__。通过它我们可以获取模块的名字
如果py文件直接运行时,那么__name__默认等于字符串’__main__’。__name__属性值为__main__的模块是主模块。一个程序中只有一个主模块。
示例
创建一个模块module1.py
print("yangyu is a good man")
a = 1
b = 2
def fun1():
print('yangyu is king of world')
print(__name__) # __main__
# print(locals())
'''
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000000000207FD88>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'F:/PycharmProjects/项目/module1.py', '__cached__': None, 'a': 1, 'b': 2, 'fun1': <function fun1 at 0x00000000025570D8>}'''
class A():
def __init__(self, name):
self.name = name
print(A, '我的名字是%s' % self.name)
if __name__ == '__main__': # main函数,程序的入口函数:不是在当前模块运行的程序,那么这个程序就不会运行
c = A('king') # <class '__main__.A'> 我的名字是king
同目录下创建一个text.py文件
# 模块的创建
# 添加导包路径:在根文件夹点击鼠标右键-> Mark Directory as -> Sources Root
import module1 # yangyu is a good man
import module1 as m1
print(module1) # <module 'module1' from 'F:\\PycharmProjects\\项目\\module1.py'>
print(m1) # <module 'module1' from 'F:\\PycharmProjects\\项目\\module1.py'>
# from module1 import fun1
from module1 import *
fun1() # yangyu is king of world
print(a) # 1
print(b) # 2
c = A('yangyu') # <class 'module1.A'> 我的名字是yangyu
3.模块的使用
访问模块中的变量, 语法: 模块名.变量名
访问模块中的函数, 语法: 模块名.函数名
访问模块中的对象, 语法: 模块名.对象名
我们也可以引入模块中部分内容,语法: from 模块名 import 变量,变量…
还有一种引入方式, 语法: from 模块名 import 变量 as 别名
四、异常
1.异常简介
- 程序在运行过程中可能会出现一些错误。比如: 使用了不存在的索引,两个不同类型的数据相加…这些错误我们称之为异常
- 处理异常:程序运行时出现异常,目的并不是让我们的程序直接终止!Python是希望在出现异常时,我们可以编写代码来对异常进行处理
示例1
# 异常的简介
# import random
res = random.randint(1, 5)
print(res) # NameError: name 'random' is not defined
# 异常处理的语句
# try:
# 可能出错的语句
# except:
# 出错了怎么解决
示例2
# 异常的简介
# 异常处理的语句:让代码尝试去运行,并且一定不会给我们报错
# try:
# 可能出错的语句
# except:
# 出错了怎么解决
try:
res = random.randint(1, 5)
print(res)
except:
print("代码出错了,我们这么做")
'''
代码出错了,我们这么做
'''
示例3
# 异常的简介
import random
try:
res = random.randint(1, 5)
print(res)
except:
print("代码出错了,我们这么做")
else:
print("代码没问题,我们就执行")
'''
1
代码没问题,我们就执行
'''
2.异常的传播
- 当在函数中出现异常时,如果在函数中对异常进行了处理,则异常不会再进行传播。如果函数中没有对异常进行处理,则异常会继续向函数调用处传播。如果函数调用处处理了异常,则不再传播异常,如果没有处理则继续向调用处传播。直到传递到全局作用域(主模块)如果依然没有处理,则程序终止,并显示异常信息。
- 当程序运行过程中出现异常以后,所有异常信息会保存到一个异常对象中。而异常传播时,实际上就是异常对象抛给了调用处
示例1
# 异常的传播
def fun():
print('我是fun函数')
print(1/0)
fun()
'''
Traceback (most recent call last):
File "F:/PycharmProjects/test.py", line 7, in <module>
fun()
File "F:/PycharmProjects/test.py", line 4, in fun
print(1/0)
ZeroDivisionError: division by zero'''
示例2
# 异常的传播
def fun():
print('我是fun函数')
try:
print(1 / 0)
except:
print("报错了")
fun()
'''
我是fun函数
报错了'''
def fun1():
print('我是fun函数')
print(1 / 0)
try:
fun1()
except:
print("报错了")
'''
我是fun函数
报错了'''
示例3
# 异常的传播
def fun():
print(1 / 0)
def fun1():
fun()
def fun2():
fun1()
def fun3():
fun2()
fun3()
'''
Traceback (most recent call last):
File "F:/PycharmProjects/项目/test.py", line 18, in <module>
fun3()
File "F:/PycharmProjects/项目/test.py", line 15, in fun3
fun2()
File "F:/PycharmProjects/项目/test.py", line 11, in fun2
fun1()
File "F:/PycharmProjects/项目/test.py", line 7, in fun1
fun()
File "F:/PycharmProjects/项目/test.py", line 3, in fun
print(1 / 0)
ZeroDivisionError: division by zero
'''
3.异常对象
try语句
try:
代码块(可能出现错误的语句)
except 异常类型 as 异常名:
代码块(出现错误以后的处理方式)
except 异常类型 as 异常名:
代码块(出现错误以后的处理方式)
except 异常类型 as 异常名:
代码块(出现错误以后的处理方式)
…
else:
代码块(没出错时要执行的语句)
finally:
代码块(是否出错该代码块都会执行)
try是必须的
else有没有都可以
except和finally至少有一个
示例1
# 异常对象
# 这是对异常进行一个捕获处理,使程序不会报错而停止运行
try:
print(a) # NameError
print(1 / 0) # ZeroDivisionError
except:
print("我不知道出了什么错,我就知道出错了")
else:
print('没错')
'''
我不知道出了什么错,我就知道出错了'''
try:
print(a) # NameError
print(1 / 0) # ZeroDivisionError
except NameError:
print("变量没有被定义")
else:
print('没错')
'''
变量没有被定义'''
try:
# print(a) # NameError
print(1 / 0) # ZeroDivisionError
except ZeroDivisionError:
print("除零错误")
else:
print('没错')
'''
除零错误'''
try:
print(a) # NameError
print(1 / 0) # ZeroDivisionError
except Exception as e:
print("出错了", e, type(e))
else:
print('没错')
'''
出错了 name 'a' is not defined <class 'NameError'>'''
示例2
# finally:不管是否有异常都会执行
try:
print(a) # NameError
print(1 / 0) # ZeroDivisionError
except Exception as e:
print("出错了", e, type(e))
else:
print('没错')
finally:
print("不管是否有异常都会执行")
'''
出错了 name 'a' is not defined <class 'NameError'>
不管是否有异常都会执行'''
try:
pass
# print(a) # NameError
# print(1 / 0) # ZeroDivisionError
except Exception as e:
print("出错了", e, type(e))
else:
print('没错')
finally:
print("不管是否有异常都会执行")
'''
没错
不管是否有异常都会执行'''
五、文件
1.文件打开
- 文件(file) 通过Python程序来对计算机中的各种文件进行增删改查的操作。
- 文件的操作步骤
打开文件
对文件进行各种操作(读、写)然后保存
关闭文件 - 文件会有一个返回值。返回一个对象,这个对象就表示的是当前的文件
示例
# 打开文件
# python操作数据都是要通过操作这个数据创建的变量才可以实施
file_name = 'demo.txt' # file_name = r'F:\PycharmProjects\项目\demo.txt' # 绝对路径
file_obj = open(file_name) # 打开文件对象
print(file_obj) # <_io.TextIOWrapper name='demo.txt' mode='r' encoding='cp936'>
print(file_obj.read()) # yangyu is king of the world!
2.关闭文件
- 调用close()方法来关闭文件
- with…as 语句不用写close()来关闭。它自带关闭
示例1
# 文件的关闭
file_name = 'demo.txt' # file_name = r'F:\PycharmProjects\demo.txt' # 绝对路径
file_obj = open(file_name) # 打开文件对象
print(file_obj) # <_io.TextIOWrapper name='demo.txt' mode='r' encoding='cp936'>
content = file_obj.read()
print(content) # yangyu is king of the world!
file_obj.close() # 关闭文件之后就不能继续读取了
content1 = file_obj.read()
print(content1)
'''
File "F:/PycharmProjects/test.py", line 9, in <module>
content1 = file_obj.read()
ValueError: I/O operation on closed file.'''
示例2
# with...as 语句不用写close()来关闭。它自带关闭
file_name = 'demo.txt' # file_name = r'F:\PycharmProjects\demo.txt' # 绝对路径
with open(file_name) as f: # 对于我们打开的文件取名f
print(f) # <_io.TextIOWrapper name='demo.txt' mode='r' encoding='cp936'>
print(type(f)) # <class '_io.TextIOWrapper'>
content = f.read()
print(content) # yangyu is king of the world!
f.read()
'''
Traceback (most recent call last):
File "F:/PycharmProjects/项目/test.py", line 10, in <module>
f.read()
ValueError: I/O operation on closed file.
<_io.TextIOWrapper name='demo.txt' mode='r' encoding='cp936'>
<class '_io.TextIOWrapper'>
abcdef
yangyu
yangyu
'''
示例3
file_name = 'demosss.txt'
try:
with open(file_name) as f:
print(f)
print(type(f))
content = f.read()
print(content)
except FileNotFoundError:
print('文件没有找到')
'''
文件没有找到'''
3.读取文件
- 通过read()来读取文件的内容
- 调用open()来打开一个文件,可以将文件分为2种类型
- 一种 纯文本文件(使用utf-8编码编写的文件)
- 一种 二进制文件(图片 mp3 视频…)
- open()打开文件时,默认是以文本文件的形式打开的 open()默认的编码为None。所以处理文本文件时要指定编码
示例1

# 文件的读取
file_name = 'demo.txt'
with open(file_name) as f:
content = f.read()
print(content)
'''
Traceback (most recent call last):
File "F:/PycharmProjects/项目/test.py", line 5, in <module>
content = f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaf in position 110: illegal multibyte sequence'''
示例2
# 文件的读取
file_name = 'demo.txt'
with open(file_name,encoding='utf-8') as f:
content = f.read()
print(content)
'''
优美胜于丑陋(Python 以编写优美的代码为目标)
明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)
简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)
复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)
扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)
间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)
可读性很重要(优美的代码是可读的)
即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)
不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)
当存在多种可能,不要尝试去猜测
而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)
虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido )
做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)
如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准)
命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)'''
3.1较大文件的读取
- 通过read()读取文件内容时会将文件中所有的内容全部读取出来。如果对于读取的文件比较大的话。会一次性的将文件加载到内容中。容易导致内存泄露。所以对于较大的文件。不要直接调用read()
- read()可以接收一个size作为的参数。该参数用来指定要读取字符的数量。默认值为-1。-1也就是要读取全部的内容
- 每次读取都会从上次读取到的位置开始。如果字符的数量小于size。则会读取所有的。如果读取到最后的文件。则会返回空串
- readline() 该方法用来读取一行
- readlines() 该方法用于一行一行的读取内容,它会一次性将读取到的内容封装到一个列表当中返回
示例1
# 文件的读取
file_name = 'demo.txt'
with open(file_name,encoding='utf-8') as f:
# content = f.read() # read(self, n: int = -1) -> AnyStr: 默认-1,读取全部
# help(f.read) # read(size=-1, /)
content = f.read(10) # 给size传递参数,一次读取多少个字节
print(content) # 优美胜于丑陋(Pyt
示例2
# 文件的读取 f.readline() 逐行读取
file_name = 'demo.txt'
with open(file_name,encoding='utf-8') as f:
content = f.readline()
print(content) # 优美胜于丑陋(Python 以编写优美的代码为目标)
content = f.readline()
print(content) # 明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)
示例3
# 文件的读取 f.readlines() 以列表的方式读取全部
file_name = 'demo.txt'
with open(file_name,encoding='utf-8') as f:
content = f.readlines()
print(content)
'''
['优美胜于丑陋(Python 以编写优美的代码为目标)\n', '明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)\n', '简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)\n', '复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)\n', '扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)\n', '间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)\n', '可读性很重要(优美的代码是可读的)\n', '即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)\n', '不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)\n', '当存在多种可能,不要尝试去猜测\n', '而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)\n', '虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido )\n', '做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)\n', '如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准)\n', '命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)']
'''
4.文件的写入
- write()来向文件中写入内容
- 该方法可以分多次向文件写入内容
- 写入完成之后该方法会返回写入的字符的个数
- 使用open()函数打开文件时,必须要指定打开文件要做的操作(读、写、追加)。如果不指定操作类型,则默认是读取文件,而读取文件是不能向文件中写入
- r 表示只读
- w表示可以写。使用w写入文件时,如果文件不存在则会创建一个文件。如果文件存在则会覆盖原文件内容
示例1
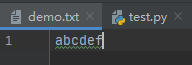
# 文件的写入
file_name = 'demo.txt'
with open(file_name, 'w', encoding='utf-8') as f:
f.write('abc') # 写入的内容必须是字符串
# f.write(123) # TypeError: write() argument must be str, not int
f.write('def')
示例2
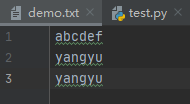
# 文件的写入
# 'w'是覆盖性写入
# 'a'是追加
file_name = 'demo.txt'
with open(file_name, 'a', encoding='utf-8') as f:
f.write('\nyangyu') # 换行追加
5.二进制文件写入
- 读取文本文件时,size是以字符为单位。读取二进制文件时,size是以字节为单位
- 我们用wb来写入二进制文件
示例
# 二进制文件读写操作
import pygame
import time
file_name = '1.mp3'
# 将读取出来的二进制内容写成一个新的二进制文件
with open(file_name, 'rb') as f:
# print(f) # <_io.TextIOWrapper name='1.mp3' mode='r' encoding='cp936'>
# print(f.read(30)) # b'ID3\x03\x00\x00\x00\x00













 198
198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









